shell基础
linux-shell-base来自b站课程3天搞定Linux,1天搞定ShellP66-P88
写在前面:此笔记来自b站课程3天搞定Linux,1天搞定ShellP66-P88
概述
shell是外层应用程序与系统内核连接的桥梁,本质上一个命令行解释器——它接收应用程序/用户的命令,然后调用操作系统内核
基本格式:
-
注释以
#开头 -
脚本第一行指定解析器
#!/bin/bash -
之后的就是shell代码
执行方式:
-
bash/sh+脚本的绝对/相对路径

-
直接输入脚本的绝对/相对路径,但要为脚本添加可执行权限
chmod +x 脚本路径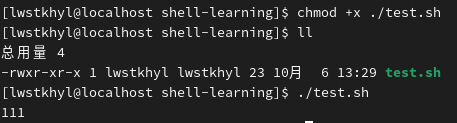
可以看到文件名变成绿色,代表可被执行
注:使用相对路径时不能直接写
test.sh,必须写成./test.sh。因为系统会将test.sh当成命令(在/bin目录中寻找同名文件)去执行
为什么第一种方式不需可执行权限:第一种实际上是运行sh或bash命令,脚本路径作为参数;而第二种是将脚本名作为命令
补充:使用.或source命令也可执行脚本文件
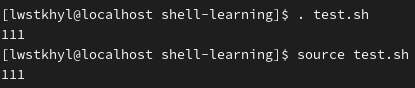
区别:前两种都是再开一个子shell进程去执行脚本,而.和source是直接在当前shell环境中执行。有时候子shell会出现内外层环境变量不通用的问题,这时就需要.和source来执行,例如有时更改了某个配置文件,为使其立即生效,就运行source .profile命令
补充:能不能通过直接输入脚本名称的方式来运行脚本?
其实是可以的,因为系统会在/bin中找命令/脚本文件,所以如果该文件位于/bin目录下,就可以这样执行。但一般情况下,不推荐改变/bin目录中的文件
方法:更改$PATH变量,相当于Windows环境变量中的path
基础知识
变量
主要分为系统定义的和用户定义的变量,还可分为全局变量和局部变量
-
全局变量是当前bash进程和其子进程都可访问
-
局部变量只在当前bash进程中可访问,其子进程无法访问
使用set/set | less命令查看当前环境内的全部变量
系统预定义变量
可以理解成环境变量,通常是全局的
-
HOME主目录路径 -
PWD当前工作目录 -
SHELL当前使用的shell解释器 -
USER当前用户 -
还有很多类似的,都是由大写字母组成的
echo $HOME # 查看某个系统变量
printenv HOME # 查看某个系统变量,不需要加$符号
env # 查看全部系统变量
env | less # 更清楚地查看
printenv
printenv | less # 同上,也是查看全部系统变量
printenv只是单纯查看变量值,所以不加$,正常情况下我们想使用变量,都要在变量名加$,例如
ls $HOME # 查看主目录内容
自定义变量
-
定义/更改变量:
变量名=变量值,注意=前后不能有空格,因为加了空格之后bash会将空格前的内容当成命令 -
删除变量:
unset 变量名 -
声明只读变量:
readonly 变量名=变量值,它不能被修改/删除
变量定义规则:
-
变量名可由字母、数字、下划线组成,不能以数字开头
-
环境变量名建议大写
-
变量默认类型都是字符串类型,不能直接进行数值运算
-
变量值如果有空格,需用单/双引号括起来;如果没空格,可以不加引号直接写(反之默认都是字符串)
补充:
-
使用
echo $变量名输出变量值 -
如果一个变量名没有声明/赋值,也可以用上述方法输出,只是结果为空行,不会报错
注意:
-
使用
变量名=变量值创建的都是局部变量,如果希望其提升为全局变量,可以使用export 变量名,这样它就可以在子shell中使用。但如果在子shell中对该变量重新赋值,只有子shell中的这个变量发生改变,外层的该变量不变(即使在子shell中使用export也不行) -
如果我们在命令行中声明了局部变量,现在运行一个shell脚本,其中用到了上述局部变量
-
使用
./source运行,可以访问到,因为它们都是在当前进程中运行的 -
使用
sh/bash/路径运行,不能访问,因为它们是在子shell中运行,子shell不能访问父级的局部变量
解决方法:使用export提升父级变量
-
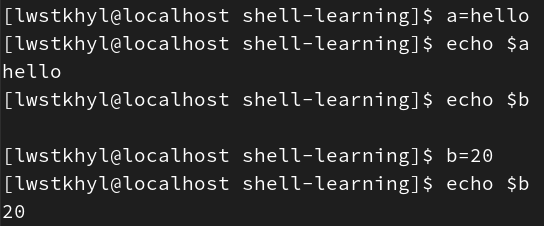

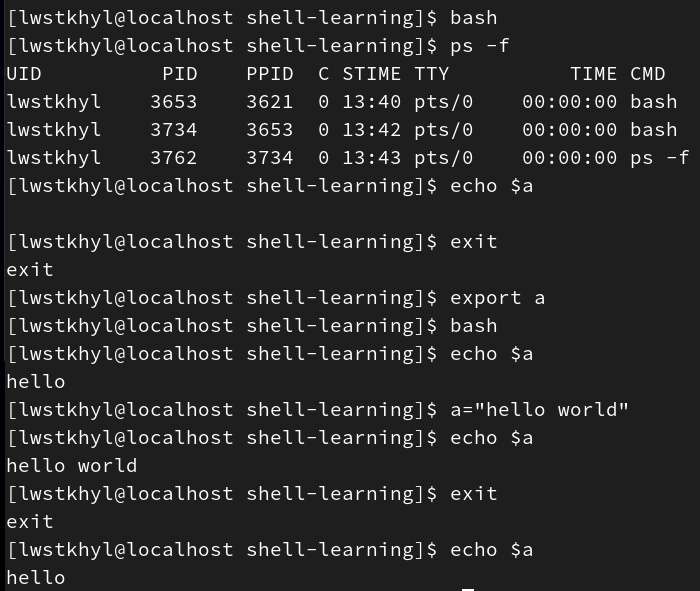
其中bash命令可以打开一个子shell,ps -f检查是否在子shell中(如果由两个bash就是在子shell)
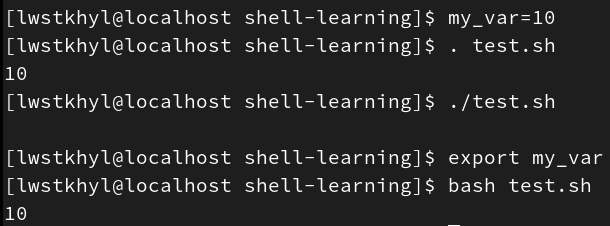
创建test.sh:
#!/bin/bash
echo $my_var
特殊变量
注:所有的特殊变量只有在双引号中或者不加引号才会被认为是变量,在单引号中会被认为是普通字符串
-
$n:n为数字,表示在命令行中执行该脚本时后面跟着的参数——$0代表该脚本名称(命令行中执行的文件名称),$1-$9代表第1-9个参数,如果n>=10,需用大括号包含,如${10} -
$#获取所有输入的参数个数(不包括脚本名称$0),常配合循环使用,配合参数的个数是否正确#!/bin/bash echo '-------------$n----------------' echo "I'm $0" echo "Hello, $1" echo '-------------$#----------------' echo parameter numbers: $#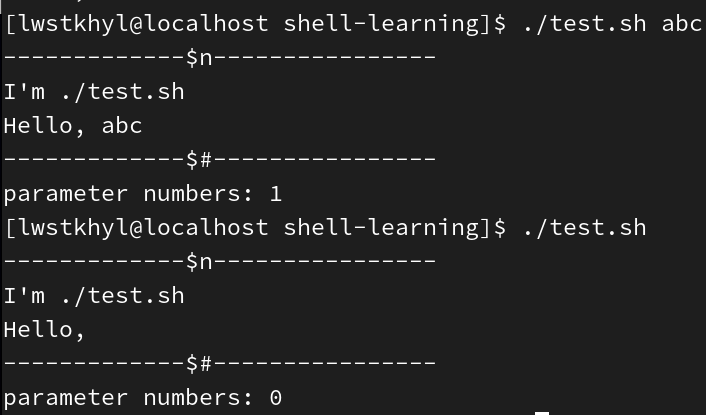
-
$*获取所有参数(把所有的参数都看成一个整体) -
$@获取所有参数构成的集合(把每个参数区分对待)注:如果不使用循环遍历,上面得到的结果其实是一样的
#!/bin/bash echo '-------------$*----------------' echo $* echo '-------------$@----------------' echo $@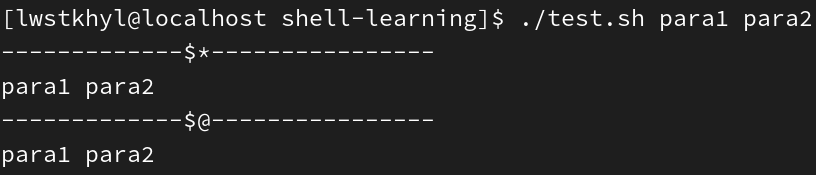
-
$?获取上一次执行的命令的返回状态。如果其值为0,则上个命令正确执行;如果非0,则说明执行出错(具体是哪个值由上个命令自己决定)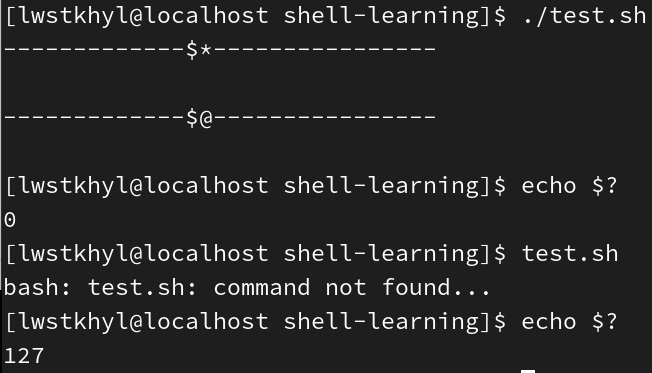
补充:
-
什么时候变量名前要加
$?给变量赋值/修改值的时候不加,使用变量(读取值)的时候加
-
如果拼接变量时,变量前后都有字符,怎么让变量名之后的字符串不被认为是变量名的一部分?
使用
${var_name}包裹,例如aa_${var}_bb。这其实就是为什么第10个参数要用${10}的原因
运算符
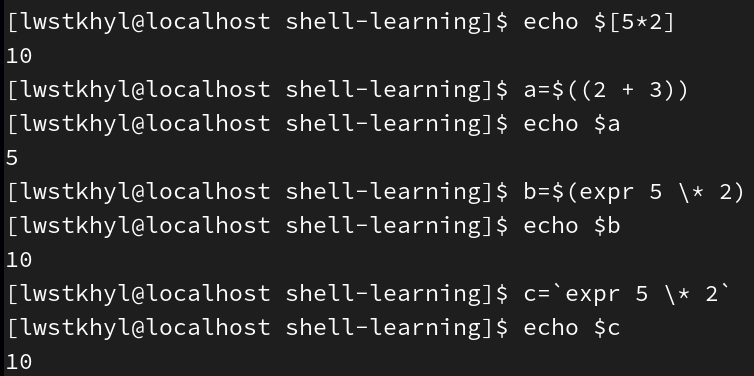
第一种实现运算的方式:expr 表达式,表达式的每个数字和运算符间必须有空格,支持+-*/,但如果使用*,必须写成\*进行转义

这种方式过于麻烦,因此通常不使用
第二种实现运算的方式:$((表达式))或$[表达式],表达式中不必写空格。它本质上一个变量,因此可以用一个变量来接收,并用echo的方式输出其值
补充:使用expr 表达式的方法也可以给变量赋值,a=$(expr 表达式)或a=`expr 表达式`,当然一般情况下也不用这种方式
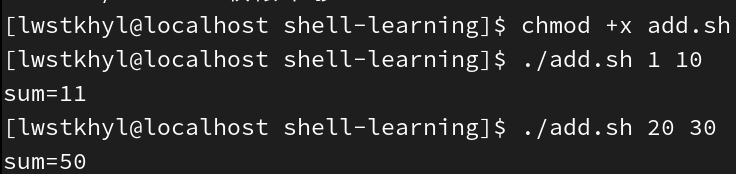
例:创建add.sh,接收两个参数,输出这两个参数的和
#!/bin/bash
sum=$[$1+$2]
echo sum=$sum
条件判断
第一种方法(不常用):test 条件表达式,若条件为true则返回0,反之返回1,在执行完该命令后,通过echo $?获取它的返回值
中括号
第二种方法:[ 条件表达式 ],注意条件表达式前后要有空格,返回值同上
注意:
-
条件表达式中值和判断符号间也要有空格
-
如果条件表达式中只有一个值则返回true,条件表达式为空(如
[ ])返回false
a=hello
test a = hello
echo $? # 1
test $a = hello
echo $? # 0
[ $a != hello ]
echo $? # 1
[ $a ]
echo $? # 0
[ ]
echo $? # 1
常用判断条件:
-
字符串(两个字符串分别放在判断符两侧)
-
等于
= -
不等于
!=
-
-
两个整数间比较(两个数分别放在判断符两侧)
-
等于
-eq -
不等于
-ne -
小于
-lt -
小于等于
-le -
大于
-gt -
大于等于
-ge
-
-
文件权限(文件名放判断符后面)
-
-r是否有读的权限 -
-w是否有写的权限 -
-x是否有执行的权限
-
-
文件类型(文件名放判断符后面)
-
-e文件/目录是否存在 -
-f文件是否存在 -
-d目录是否存在
-
-
-z $变量名变量是否为0/空
[ 2 -gt 8 ]
echo $? # 1
[ -x add.sh ]
echo $? # 0
[ -e test2.sh ]
echo $? # 1
多条件判断:
-
第一种方法——使用
&&和||进行多条件判断:[ $a = $b ] && [ $a = $c ]-
&&表示当前一条命令执行成功时,才执行后一条命令 -
||表示当前一条命令执行失败时,才执行后一条命令
利用这个原理,可以写出shell中的三元表达式:
[ 条件表达式 ] && 语句1 || 语句2[ 2 -lt 5 ] && [ 3 -lt 5 ] echo $? # 0 [ 2 -lt 5 ] || [ 3 -gt 5 ] && [ 4 -gt 5 ] echo $? # 1 a=15 [ $a -lt 20 ] && echo "$a < 20" || echo "$a >= 20" # 15 < 20 [ ] && echo "true" || echo "false" # false -
-
第二种方法——使用
-a/-o参数分别表示与/或:[ $a = $b -a $a = $c ]
双小括号
第三种方法:((条件表达式)),不用写空格,可以直接使用数学符号比较大小,常用于流程控制语句中
((2>3))
echo $? # 1
a=3
(($a>=3))
echo $? # 0
(($a<3))
echo $? # 1
((a<3)) # 等效于(($a<3)),可省略$
echo $? # 1
补充:let和双小括号
可以看到,上面提到的方法中,如果想使用运算符号,必须在外面写上$[]或$(()),里面的变量也要加$
因此shell提供了简化:
let 运算式和((运算式)),它们允许运算式中直接使用变量,并支持各种运算符号(如+=、++等)
a=0
let a++
echo $a # 1
a=0
let a++
((a+=1))
echo $a # 2
let a*=5
echo $a # 10
流程控制
if
单分支:
if [ 条件判断式 ];then
程序
fi
# 或者
if [ 条件判断式 ]
then
程序
fi
注:
-
;用于分隔同一行的多个命令,所以也可以写成if [ 条件判断式 ]; then 程序; fi的形式 -
[ 条件判断式 ]也可写成双小括号形式,下同
多分支:
if [ 条件判断式 ]
then
程序
elif [ 条件判断式 ]
程序
else
程序
fi
其中elif段可省略,直接else
例:单分支
# 单分支
age=20
if [ $age -gt 18 ]; then echo "age>18"; fi
if [ $age -gt 18 ]; then
echo "age>18"
fi
if [ $age -gt 18 ]
then
echo "age>18"
fi
# 多条件判断
a=30
if [ $a -gt 18 ] && [ $a -lt 30 ]; then
echo ok
fi
if [ $a -gt 18 -a $a -lt 30 -o $1 -gt 20 ]; then
echo ok
fi
例:多分支
if [ $1 -ge 80 ]
then
echo A
elif [ $1 -ge 60 ]; then
echo B
else
echo C
fi
if [ $2 -ge 60 ]
then
echo pass
else
echo "not pass"
fi
补充:如果我们需要对传入的参数进行判断,比如[ $1 = abc ]这种,一般要确保$1非空
方法:写成[ "$1"x = "abc"x ]的形式
原理:相当于进行字符串拼接。在$1后加上别的字符,确保=左侧非空
# 当不传参数时会报错
if [ $1 = abc ]; then
echo ok
fi
# 不会报错
if [ "$1"x = "abc"x ]; then
echo ok
fi
case
case 变量 in
值1)
程序1
;;
值2)
程序2
;;
*)
如果变量都不是以上的值,则执行此段程序
;;
esac
-
;;相当于break -
*(相当于default -
case行尾必须为in,每个子case的值必须以)结束
例:
case $1 in
"abc")
echo '$1=abc'
;;
1)
echo '$1=1'
;;
2)
echo '$1=2'
;;
*)
echo "没有匹配的值"
;;
esac
./test.sh 60 # 没有匹配的值
./test.sh 1 # $1=1
./test.sh 2 # $1=2
./test.sh abc # $1=abc
for
有两种不同的语法,分别对应for(i=1;i<10;i++)和for i in list
-
第一种
for((初始值;循环控制条件;变量改变)) do 程序 done注:循环控制条件中可以用
<=这种判断大小,变量改变中也有i++和i--,这是因为它们被双小括号(())包裹 -
第二种
for 变量 in 值1 值2 值3 ... do 程序 done # 或 for 变量 in {1..100} # 表示1,2,3,...,100的序列 do 程序 done
例:求1-$1的累加结果
sum=0
for((i=1;i<=$1;i++))
do
sum=$(($sum+$i))
done
echo $sum
注意sum=$(($sum+$i))中要用$(())进行包裹,以及使用变量时要加$
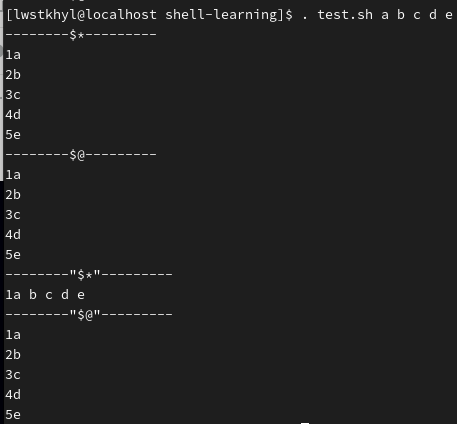
补充:$*和$@的区别
如果它们都不加引号,直接写在for循环中,则都是一个包含所有参数的序列,没有区别
如果加上双引号,则"$*"会把所有参数拼接成一个字符串整体,而"$@"仍是一个序列
echo '--------$*---------'
i=0
for para in $*
do
i=$[$i+1]
echo $i$para
done
echo '--------$@---------'
i=0
for para in $@
do
i=$[$i+1]
echo $i$para
done
echo '--------"$*"---------'
i=0
for para in "$*"
do
i=$[$i+1]
echo $i$para
done
echo '--------"$@"---------'
i=0
for para in "$@"
do
i=$[$i+1]
echo $i$para
done
while
while [ 条件判断式 ]
do
程序
done
例:求1-$1的累加结果
sum=0
i=1
while [ $i -le $1 ]
do
sum=$[$sum+$i]
((i++)) # 也可以写成i=$[$i+1]
done
echo $sum
读取控制台输入
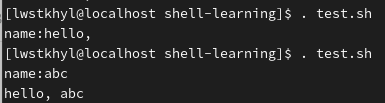
read -t 等待时间 -p 提示符 变量名
-
-p 提示符:等待输入时的提示文字 -
-t 等待时间:等待时间(单位为秒),超过等待时间后会退出等待输入状态,不加该参数表示一直等待 -
变量名:即指定是哪个变量接收输入值
read -t 5 -p "name:" name
echo "hello, $name"
函数
系统函数
其实就是像cd或ls之类的命令
命令替换:$(函数名 参数)或`函数名 参数`,即获取该函数输出的值
例如在命令行中输入date +%s,将输出当前事件戳;我们在脚本中可以使用$(date +%s)将其输出的值当作一个变量使用
# test.sh
str=$1_$(date +%s)
echo $str
# 命令行
. test.sh abc # abc_1728720828
可以看到结果只有我们在脚本中echo的$str,而没有date +%s的echo值
常用系统函数:
-
basename 文件路径 后缀获取指定路径的文件名称(删去文件/前的路径),如果指定了后缀,后缀也会被删除basename /a/b/c.sh # c.sh basename /c.sh # c.sh basename c.sh # c.sh basename /a/c.sh .sh # c -
dirname 文件路径获取文件的路径(与上面的basename正好互补,dirname取的是前面的部分)注:和basename一样,它只会把输入的路径当作字符串处理,不会真的去找这个文件,也不一定返回的是文件绝对路径
dirname /a/b/c.sh # /a/b dirname ../a/b.sh # ../a dirname ./b.sh # .
例:获取当前执行的脚本名称和绝对路径
如何获取绝对路径:先使用cd $(dirname $0)进入到脚本所在的文件夹,之后再调用pwd命令获取当前的绝对路径
# test.sh
script_name=$(basename $0 .sh)
cd $(dirname $0)
script_path=$(pwd)
# 以上两行命令可连写成↓
# script_path=$(cd $(dirname $0); pwd)
echo "script_name: $script_name"
echo "script_path: $script_path"
# 命令行
./test.sh
# script_name: test
# script_path: /home/lwstkhyl/桌面/shell-learning
为什么必须要cd:因为运行脚本的地方可能并不是脚本所在的文件夹,pwd只会输出当前执行脚本的路径
自定义函数
# 声明
[function] funcname[()]
{
程序;
[return 返回值;]
}
# 调用
funcname 参数1 参数2 ...
-
其中
[]括起来的为可选项 -
函数定义中无需写形参,传入的形参仍是以
$1、$2这种形式获取 -
函数返回值只能通过
$?获得,返回值只能为[0,255]的整数值,如果不return,将以最后一条命令运行的结果作为返回值注:如果返回值超过255,会循环减去256,直至值达到0-255(如果return 256则返回0)
-
必须先声明再调用
-
如果想真正像其它语言一样返回值,可以使用命令替换
[function] funcname[()]{ echo 返回值; } res=$(funcname 参数1 参数2 ...) # res就是返回值
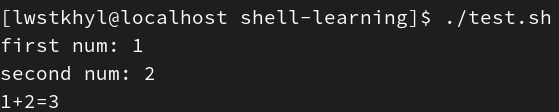
例:输入两个数求和
函数内直接输出:
# test.sh
function add(){
sum=$[$1+$2]
echo "$1+$2=$sum"
}
read -p "first num: " a
read -p "second num: " b
add $a $b
返回值版本:
# test.sh
function add(){
sum=$[$1+$2]
echo $sum
}
read -p "first num: " a
read -p "second num: " b
sum=$(add $a $b)
echo "$a+$b=$sum"
正则表达式与文本处理
正则表达式的基本使用
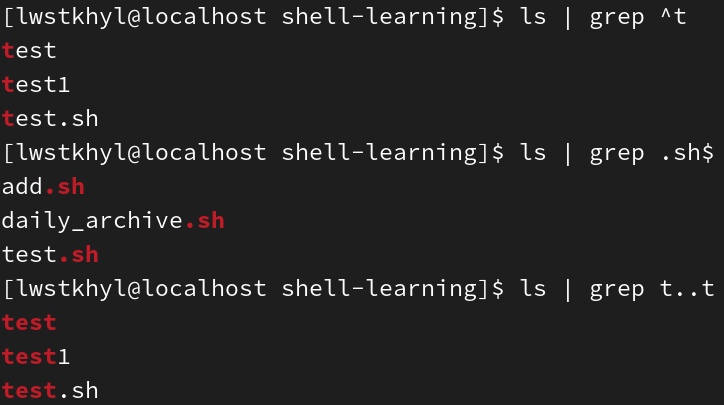
最常用的就是grep命令:命令 | grep 正则表达式/grep 正则表达式 文件
正则表达式简介:
-
^匹配开头$匹配结尾 常一起使用:^abc$ -
.匹配任意字符 -
*前一字符出现0次或多次+1次或多次?0次或1次.*就是任意字符串(包括空字符串^a.*b$以a开头以b结尾 -
{n}前一字符出现n次(n为整数),注意这里shell与其它语言不一样,grep默认不支持这种扩展的正则语法,有两种方式-
写成
"\{n\}",将大括号转义且放进双引号中 -
给grep命令加上参数
-E(表示支持扩展的正则语法)
-
-
[]某个范围内的字符-
[6,8]6或8,也可写成[68] -
[0-9]0-9的字符 -
[0-9]*任意长度的数字串 -
[a-z]a-z的字符 -
[a-z]*任意长度的字母串 -
[a-d, e-f]a-c或e-f的字符
-
-
\转义,但必须在单引号中使用,比如想匹配$就是'\$',想匹配/$file就是'/\$file'
grep的选项参数:
-
-i忽略大小写进行匹配 -
-v反向查找(只打印不匹配的行) -
-n显示匹配行的行号 -
-r递归查找子目录中的文件 -
-l只打印匹配的文件名 -
-c只打印匹配的行数 -
-m后面加一个整数,表示取结果的前多少行
例:正则匹配手机号(以1开头,第二位3/4/5/7/8,之后是任意数字)
reg="^1[34578][0-9]\{9\}$"
echo "13456789123" | grep $reg
# 13456789123
grep $reg test.txt # 在指定文件中查找
# 13412345678
# 13412345670
# 或者写成↓
reg=^1[34578][0-9]{9}$
grep -E $reg test.txt
正则表达式在脚本中的使用
[[ 字符串 =~ 正则表达式 ]]判断字符串是否包含指定模式(正则表达式)
注意:
-
判断的是包含关系,不是完整匹配,即判断右边的模式是否为左边字符串的子字符串,而不是判断右边的模式是否完全等于左边字符串
-
在右面的正则表达式中,用引号括起来的部分会被当成字符串,不再被当成正则表达式,表示匹配这个字符串自身的内容
-
只有
[[命令支持=~操作符,test和[都不支持
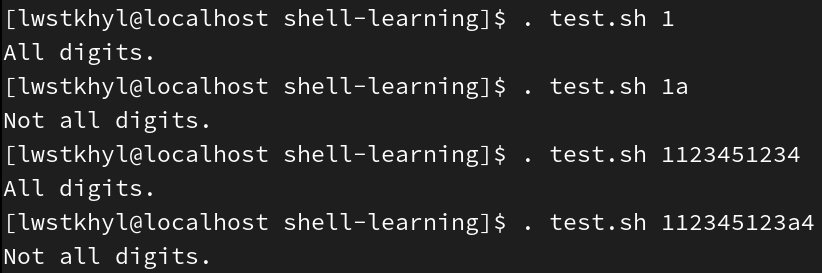
例1:判断字符串是否全是数字
if [[ "$1" =~ [0-9]{${#1}} ]]; then
echo "All digits."
else
echo "Not all digits."
fi
-
${#1}表示传入的第一个参数的长度,[0-9]{${#1}}就表示相等长度的数字串 -
正则不能写成
[0-9]+,因为这样只要有数字就为true(判断的是包含)
例2:判断某个字符串是否为另一个字符串的子字符串
if [[ "$1" =~ "$2" ]]; then
echo \"$1\" contains \"$2\"
else
echo \"$1\" does not contain \"$2\"
fi
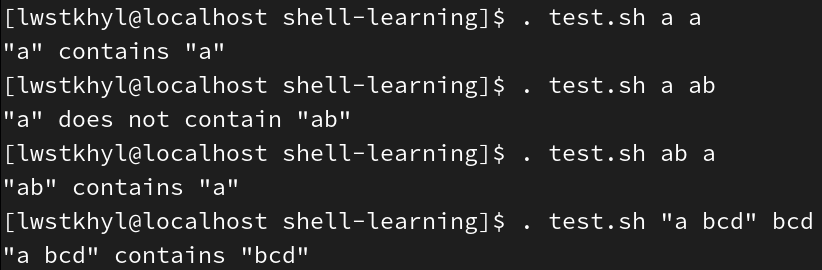
=~右边的"$2"加了双引号,不再当成正则表达式处理,只会比较字符串自身的内容
文本处理
cut
cut [选项参数] 文件或命令 | cut [选项参数]:对文本根据指定分隔符剪切成多列
选项参数:
-
-f列号,标明提取第几列-
-f 1,2第1和2列 -
-f 1-3第1到3列 -
-f 2-第2和其后的所有列
-
-
-d分隔符,默认是"\t" -
-c每个字符为1列,后加一个整数表示取第几列,如-c 1
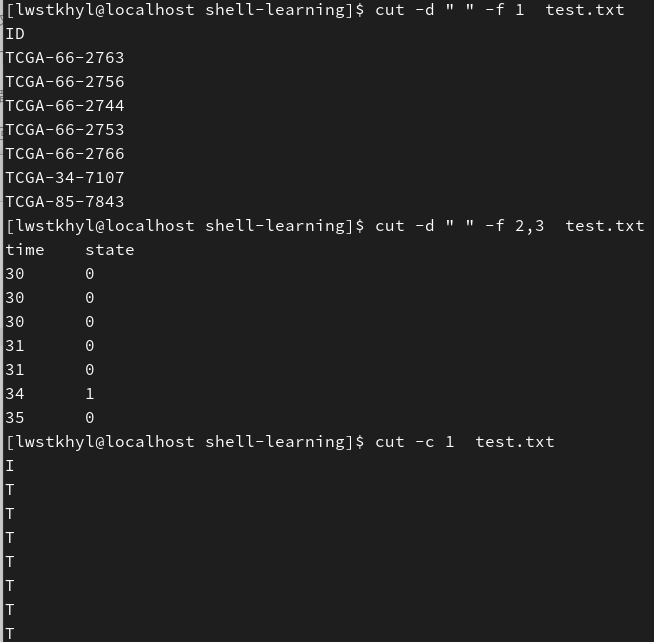
例1:
ID time state
TCGA-66-2763 30 0
TCGA-66-2756 30 0
TCGA-66-2744 30 0
TCGA-66-2753 31 0
TCGA-66-2766 31 0
TCGA-34-7107 34 1
TCGA-85-7843 35 0
# 提取第一列
cut -d " " -f 1 test.txt
# 同时提取第2、3列
cut -d " " -f 2,3 test.txt
# 提取第一个字符
cut -c 1 test.txt
例2:
cat /etc/passwd | grep bash$
# root:x:0:0:root:/root:/bin/bash
# lwstkhyl:x:1000:1000:wth:/home/lwstkhyl:/bin/bash
# oracle:x:54321:1001::/home/oracle:/bin/bash
按:分隔,提取第1、6、7列(用户名和目录)
cat /etc/passwd | grep bash$ | cut -d ":" -f 1,6,7
# root:/root:/bin/bash
# lwstkhyl:/home/lwstkhyl:/bin/bash
# oracle:/home/oracle:/bin/bash
例3:选取系统PATH变量中,第2个:后的所有路径
echo $PATH | cut -d ":" -f 3-
# /usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin
例4:
ifconfig lo
# lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
# inet 127.0.0.1 netmask 255.0.0.0
# inet6 ::1 prefixlen 128 scopeid 0x10<host>
# loop txqueuelen 1000 (Local Loopback)
# RX packets 192 bytes 17242 (16.8 KiB)
# RX errors 0 dropped 0 overruns 0 frame 0
# TX packets 192 bytes 17242 (16.8 KiB)
# TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
提取出inet行的IP地址127.0.0.1:
ifconfig lo | grep netmask # 提取出inet那行
# inet 127.0.0.1 netmask 255.0.0.0
ifconfig lo | grep netmask | cut -d " " -f 10
# 127.0.0.1
为什么是-f 10:因为这行前面有8个空格,相当于8列,inet是第9列,IP就是第10列
awk
比cut更强大的文本分析工具,可以把文件逐行读入,以空格为默认分隔符将每行切片
-
awk [选项参数] '/pattern1/{action1} /pattern2/{action2}' ... 文件 -
或
命令 | awk [选项参数] '/pattern1/{action1}' '/pattern2/{action2}' ...
说明:
-
pattern:awk在文件中查找的内容(匹配模式),一般为正则表达式,注意要放在两个/里面。这部分相当于根据正则找符合条件的行,如果省略将会把所有行传入action中/pattern/可替换成:-
BEGIN表示在所有数据读取前执行 -
END表示在所有数据读取完成后执行
-
-
action:在找到匹配内容时执行的命令,就像大括号括起来的代码块。这部分接收前面pattern找到的行,并根据分隔符对这些行进行分隔补充:action提供一个命令
print,用于输出指定内容,其中$n表示第n列的值,可以进行拼接操作;其中的普通字符串需要用双引号括起来
选项参数:
-
-F指定分隔符,默认为空格 -
-v给一个变量赋值,例如-v a=1,之后在代码块中就可以直接用a来使用a变量(不用加$)注:代码块中无法使用外部定义的变量,只能使用
-v定义的 -
-f将一个脚本传入作为action
补充:如果遇到有连续空格的情况,它不会将每个空格看成1列——字符前面的空格直接忽略,字符间的多个空格看成1个
echo " 1 2" | awk '{print $2}' # 2
例1:对/etc/passwd文件进行分析
该数据的含义:用户名:加密后的密码:用户id:组id:注释:用户家目录:shell解析器
-
搜索以root开头的所有行,并输出该行的第7列
# 原来的方式:先grep找行,再cut切出第7列 cat /etc/passwd | grep ^root | cut -d ":" -f 7 # awk cat /etc/passwd | awk -F ":" '/^root/{print $7}' # /bin/bash -
搜索以root开头的所有行,并输出该行的第1和7列,中间以
,连接cat /etc/passwd | awk -F ":" '/^root/{print $1","$7}' # root,/bin/bash注:
,必须加上双引号,要不不显示 -
输出所有行的第1和7列,以
,连接,在输出结果的最前面添加"user,shell"作为表头,在最后一行添加---cat /etc/passwd | awk -F ":" 'BEGIN{print "user,shell"}{print $1","$7} END{print "---"}'
…

-
定义一个变量
i,将用户id增加i并输出cat /etc/passwd | awk -F ":" -v a=1 '{print $3+a}'
awk的内置变量:
-
FILENAME文件名 -
NR已读的行数(当前行号) -
NF浏览记录的域个数(切割后共有几列)
注:使用它们也不需要加$
例2:
-
打印passwd文件名、每行的行号和列数
awk -F ":" '{print "文件名:"FILENAME",行号:"NR",列数:"NF}' /etc/passwd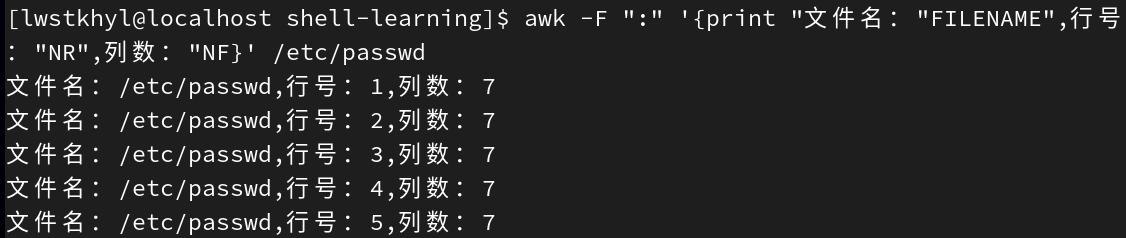
-
查询
ifconfig命令结果中空行所在的行号注:正则表达式
^$匹配空行ifconfig | grep -n ^$ # 9: ifconfig | awk '/^$/{print "空行:"NR}' # 空行:9grep命令输出的行号后带有
:,且无法进行个性化输出,因此常用awk -
实现cut中的例4——提取IP
因为awk会忽略多个空格,所以就是取第2列
ifconfig lo | awk '/netmask/{print $2}' # 127.0.0.1
综合案例
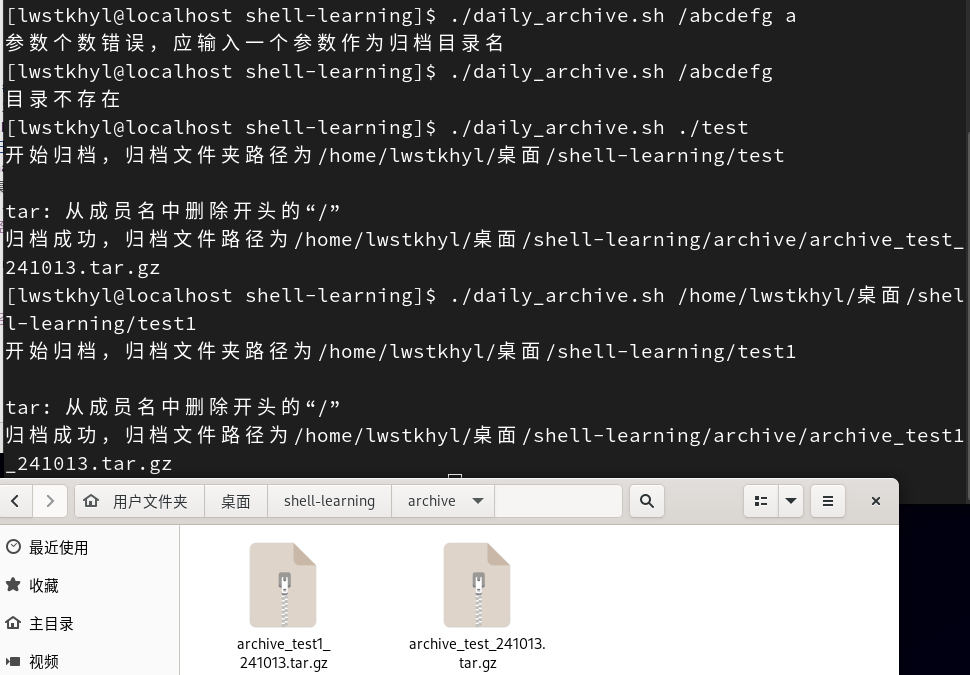
归档文件
写一个对指定目录归档备份的脚本,参数为一个目录(结尾不为/),将目录下的所有文件归档保存,并将归档日期附加在归档文件名上,格式为archive_目录名称_当前年月日日期.tar.gz
-
首先判断输入参数个数是否为1
if [ $# -ne 1 ] # 如果参数个数不为1 then echo "参数个数错误,应输入一个参数作为归档目录名" exit # 退出脚本 fi -
从参数中获取目录名称,拼接生成的归档文件名
if [ -d $1 ] # 如果是一个目录,就继续执行 then [ ] else # 如果不是就退出 echo "目录不存在" exit fi dir_name=$(basename $1) # 目录名称 dir_path=$(cd $(dirname $1); pwd) # 目录所在文件夹的绝对路径 dir_entire_path=${dir_path}/${dir_name} # 目录的完整绝对路径 date=$(date +%y%m%d) # 日期 file_name=archive_${dir_name}_${date}.tar.gz # 生成的归档文件名称 des_path=/home/lwstkhyl/桌面/shell-learning/archive # 归档文件的存放位置 entire_path=${des_path}/${file_name} # 生成的归档文件的完整绝对路径 -
开始归档操作
echo "开始归档,归档文件夹路径为$dir_entire_path" echo cd $dir_path tar -czf $entire_path $dir_name # 这两行也可写成↓,但下面这种会有产生多余的文件夹 # tar -czf $entire_path $dir_entire_path if [ $? -eq 0 ] then echo "归档成功,归档文件路径为$entire_path" else echo "归档失败" fi
补充:如何定时执行该脚本?
先输入命令crontab -e,再输入
0 2 * * * 脚本路径 脚本参数
其中前5个值表示什么时候执行,按分时日月周的顺序,如上面的0 2 * * *就表示每月每周每日的2:00执行
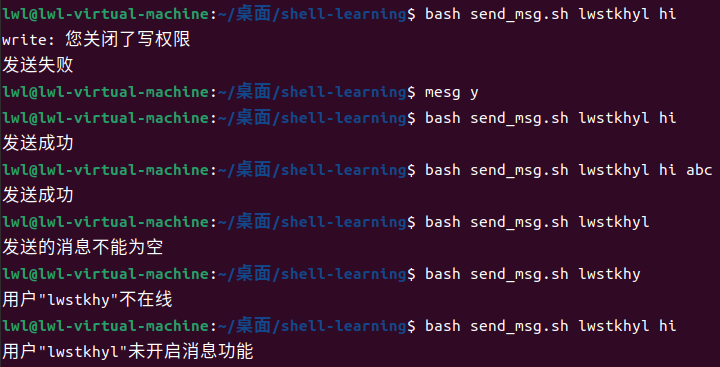
发送消息
利用Linux自带的mesg和write工具,向其它用户发送消息
需求:实现一个向某个用户快速发送消息的脚本,输入用户名作为第一个参数,第二个参数是要发送的消息。需要检测用户是否登录在系统中、是否打开消息功能、要发送的消息是否为空
准备工作:需要多用户同时连接Linux系统,这里我用Windows的ssh连接虚拟机,登录不同的用户
补充知识:
who am i # 查看当前正使用的是哪个用户
who # 查看所有登录的用户
mesg # 查看当前使用的用户是否打开消息功能
who -T # 查看各用户是否打开消息功能
mesg y # 开启消息功能
mesg n # 关闭消息功能
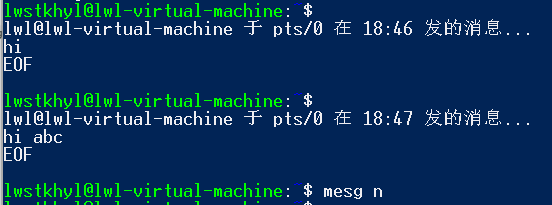
write 用户名 控制台名称 # 向指定用户的指定控制台发送消息
例如:
# windows登录lwstkhyl用户
ssh lwstkhyl@192.168.142.128
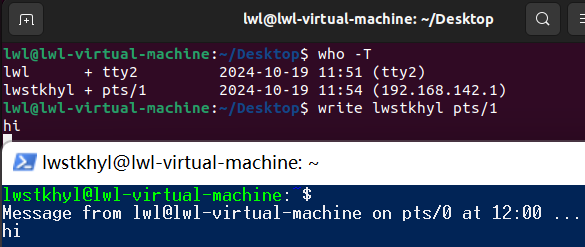
# 虚拟机登录lwl用户
who -T
# lwl + tty2 2024-10-19 12:13 (tty2)
# lwstkhyl + pts/1 2024-10-19 12:14 (192.168.142.1)
write lwstkhyl pts/1
按下回车后就可发送消息
或者也可写成:echo 消息 | write 用户名 控制台名称,这样就是一次性操作(只发送一条)
注意这是单向发送,不能实时交互
-
查看用户是否登录:用
who将所有用户查出来,然后用grep根据传入的用户名进行筛选user=$1 login_user=$(who | awk '$1 ~ /^'$user'$/{print $1}') # 对第一列用户名与输入的用户名进行匹配 if [ -z $login_user ] # 如果没有该用户就退出 then echo "用户\"$1\"不在线" exit fi注:
-
-i忽略大小写 -
-m 1因为可能一个用户有多个控制台,只需要取匹配结果的第一行即可 -
'$1 ~ /^'$user'$/{print $1}'第一列是否符合正则表达式,如果符合就执行大括号内的代码。注意在正则表达式内引入外部变量要加引号 -
使用
\"对字符串内的双引号进行转义
-
-
查看用户是否开启mesg功能:使用
who -T命令,正则判断同上is_allowed=$(who -T | awk '$1 ~ /^'$user'$/{print $2}') # 判断第二列是加号还是减号 if [ $is_allowed != '+' ] # 如果用户没开启就退出 then echo "用户\"$1\"未开启消息功能" exit fi -
判断要发送的消息是否为空
if [ -z $2 ] then echo "发送的消息不能为空" exit fi -
从参数中获取要发送的消息:因为消息间可能有空格,要把第二个及之后的参数都当成消息。使用
echo $*获取全部的参数,之后cut -d " " -f 2-取第2列之后的所有列即可 -
获取用户登录的终端:就是
who的第2列# 从参数中获取要发送的信息 msg=$(echo $* | cut -d " " -f 2-) # 用户登录的终端 terminal=$(who | awk '$1 ~ /^'$user'$/{print $2}') -
写入要发送的消息
# 发送消息 echo $msg | write $user $terminal # 异常情况处理 if [ $? != 0 ] then echo "发送失败" else echo "发送成功" fi