NodeJS--01
JS-NodeJSb站课程尚硅谷Node.js零基础视频教程P1-P66笔记——fs、path、http模块
写在前面:此笔记来自b站课程尚硅谷Node.js零基础视频教程 P1-P66 / 资料下载 提取码:s3wj / 课上案例
NodeJS简介
基本使用
Node.js是一种JS运行环境,可以理解成是一个可以运行JS程序的软件
主要用于:构建服务器、开发工具类应用、桌面端应用
此课程使用的nodejs版本为18.12.1,下载教程,建议先更改下载地址为镜像网站
简单使用:
在vscode中按ctrl+`键打开终端/右键文件后点击在集成终端中打开,输入node JS文件名即可使用node.js运行JS文件
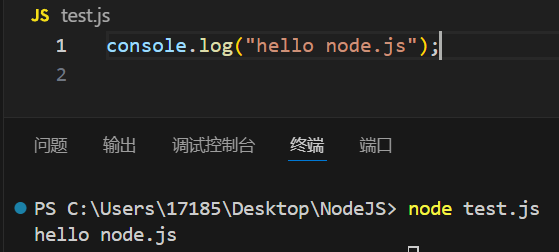
之后无特殊说明,代码都是在该文件种编写,并用这种方法运行
注意事项:在Node.js中不能使用DOM和BOM的API,如window、document、navigator等等
-
浏览器中的JS
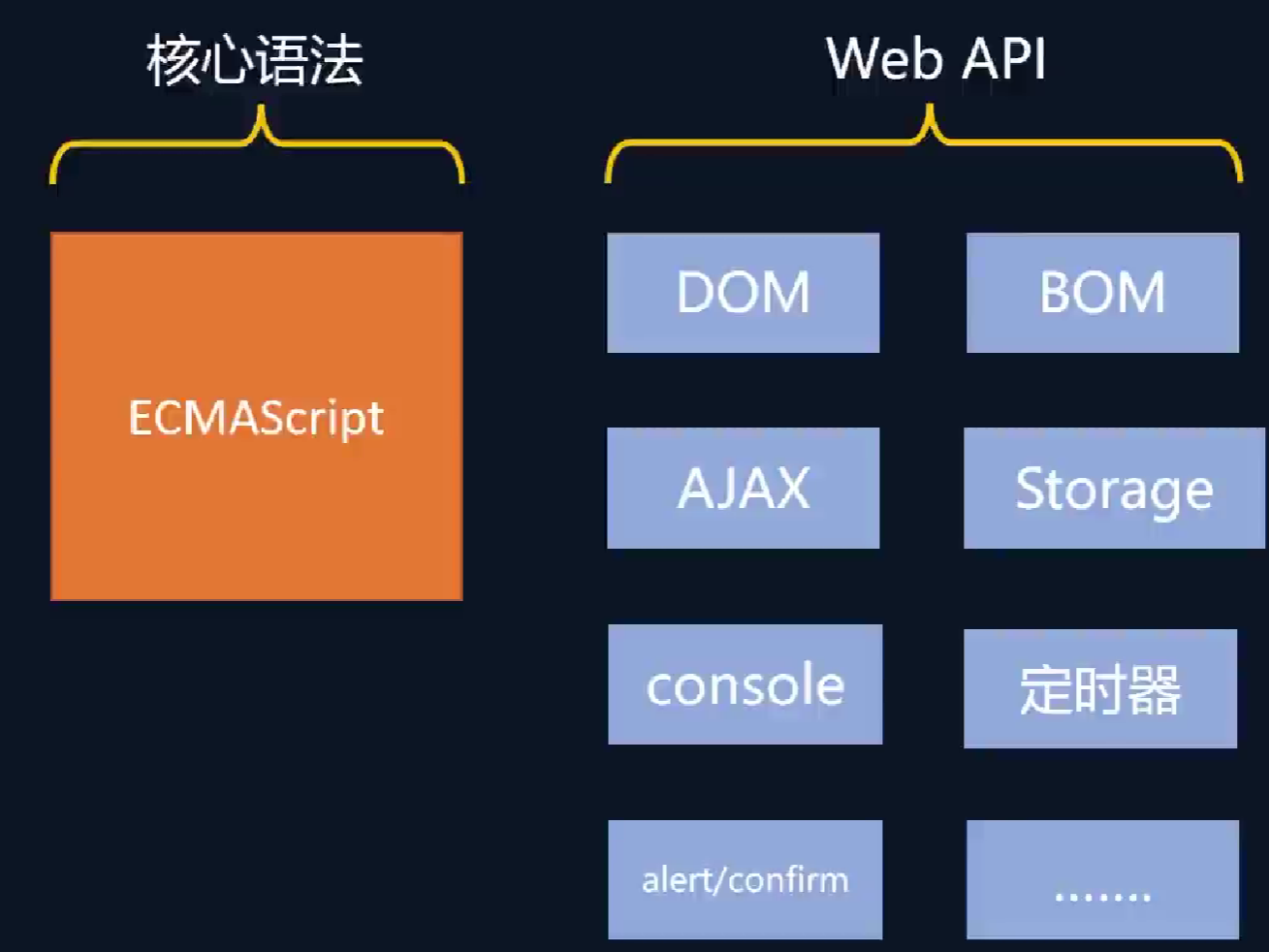
-
Node.js中的JS
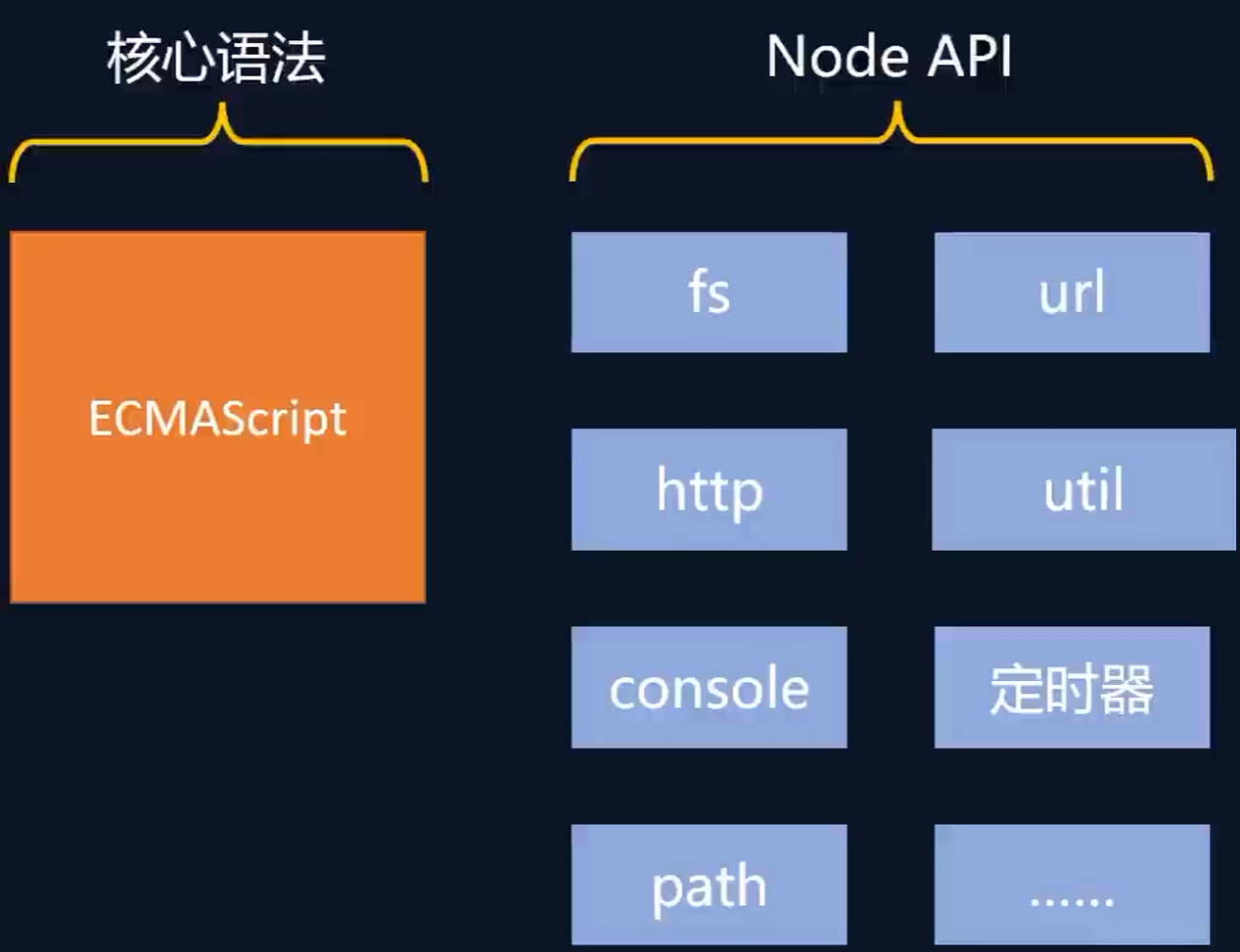
可以看到console和定时器是可以在Node.js中使用的
Node.js中的顶级对象:不是window,而是global和globalThis(它们指的是同一个对象)
buffer
缓冲区(buffer):是一个类似于数组的对象,用于表示固定长度的字节序列
简单来说,buffer就是一段固定长度的内存空间,用于处理二进制数据
特点:
-
大小固定且无法更改
-
可以直接操作内存,因此性能较好
-
每个元素的大小为1字节(byte),是一个8位二进制数
创建
总共有3种方法
-
Buffer.alloc(大小)let buf = Buffer.alloc(10); //长度为10字节 console.log(buf); //<Buffer 00 00 00 00 00 00 00 00 00 00> -
Buffer.allocUnsafe(大小)let buf = Buffer.allocUnsafe(10000); console.log(buf); //<Buffer f0 2c 05 c8 4e 02 00 00 ... 9950 more bytes>与上面
alloc的区别:allocUnsafe使用的内存可能包含旧的内存数据。alloc会先对使用的内存进行清空归零,而allocUnsafe不会,因此结果中会有非零值,这就是旧的内存数据优点:速度比
alloc更快 -
Buffer.from(字符串/数组)将字符串或数组转换为buffer转换规则:每个字符/数组中元素都转为Unicode中的编码,该编码再转成二进制形式,存入buffer数组中
let buf = Buffer.from('hello'); console.log(buf); //<Buffer 68 65 6c 6c 6f> let buf2 = Buffer.from([10, 101, 200, 119]); console.log(buf2); //<Buffer 0a 65 c8 77>为什么输出的是16进制:终端输出运行结果时,会对二进制数字进行转换,方便查看
操作
-
buffer与字符串的转换:
buf.toString()let buf = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]); console.log(buf.toString()); //iloveyou注意:默认是utf-8编码
-
读写:可以直接使用
buf[index]的方式获取/修改元素let buf = Buffer.from([105, 108, 111, 118, 101, 121, 111, 117]); console.log(buf[0]); //105 console.log(buf[0].toString(2)); //1101001 buf[0] = 95; //修改 console.log(buf); //<Buffer 5f 6c 6f 76 65 79 6f 75> console.log(buf.toString()); //_loveyou其中
buf[0].toString(2)是将该元素转为2进制,终端输出时会自动省略前面的0,因此结果只有7位,实际结果应为01101001
补充说明
-
溢出:因为buffer的每个元素是8位2进制,最大只能保存255。如果将元素修改为>255的数,则会将高位数字舍弃
let buf = Buffer.from('hello'); buf[0] = 361; //二进制为0001 0110 1001 console.log(buf[0]); //105 只保留0110 1001 console.log(buf); //<Buffer 69 65 6c 6c 6f> -
中文:也使用utf-8编码,一个汉字占3字节
let buf = Buffer.from('你好'); console.log(buf); //<Buffer e4 bd a0 e5 a5 bd>
进程与线程
进程:程序的一次执行过程,可以理解为正在执行的程序
线程:一个进程中执行的一个执行流,一个线程是属于某个进程的,一个进程至少包含一个线程
查看某个进程中的线程:下载pslist.exe,cmd中输入pslist -dmx 进程PID,进程PID在任务管理器的详细信息中
fs模块
即file system,可以实现与内存/硬盘的交互,如文件/文件夹的创建删除、文件内容的读写等
在使用任何模块前都需要进行导入:
const 变量名 = require('模块名');
//例如:
const fs = require('fs');
其中const也可以是var/let,require是导入模块的函数,变量名可以任取(一般与模块名相同),之后调用模块中的函数都用这个变量名
文件写入
-
覆盖写入(同步/异步)
fs.writeFile(file, data[, options], callback)/fs.writeFileSync(file, data[, options]) -
追加写入(同步/异步)
fs.appendFile(file, data[, options], callback)/fs.appendFileSync(file, data[, options])-
file文件名,如果不存在则自动创建 -
data要写入的数据 -
callback回调函数。接收1个参数err(变量名可任取),当写入失败时,err为错误对象;成功时err为null -
options其它选项 -
无返回值
-
-
流式写入:
const ws = fs.createWriteStream(file); ws.write(data); ws.close();
例:
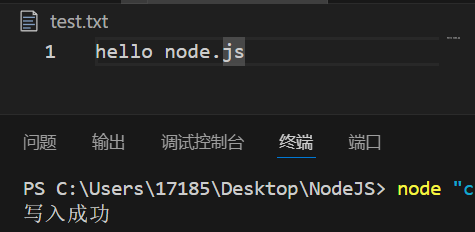
const fs = require('fs');
fs.writeFile('./test.txt', 'hello node.js', err => {
if (err) {
console.log('写入失败');
return;
}
console.log('写入成功');
});
该段程序将'hello node.js'覆盖写入test.txt中
异步写入:有两个线程。JS主线程自上而下运行代码,遇到writeFile函数时,将写入操作交给I/O线程,此时JS主线程继续向下执行,不会等待I/O线程完成写入操作;当I/O线程完成写入操作后,它将回调函数放入JS主线程的任务队列中,根据JS主线程的事件循环机制来执行回调函数(即等待js文件中的其它代码执行后,再执行回调函数)
一个例子:
const fs = require('fs');
fs.writeFile('./test.txt', 'hello node.js', err => {
if (err) {
console.log('写入失败');
return;
}
console.log('写入成功');
});
console.log('123');
会先输出123再输出写入成功
同步写入:当JS主线程执行到该函数时,会等待I/O线程执行完毕后再往下执行。同步比异步的性能差
追加写入:不仅可以用appendFile系列函数,还可以用writeFile系列函数
方法:设置option参数的flag为'a'(追加写入append),该属性默认为'w'(覆盖写入write)
const fs = require('fs');
fs.writeFile('./test.txt', '原有内容', err => {
if (err) {
console.log('写入失败');
return;
}
console.log('写入成功');
});
fs.writeFile('./test.txt', '\n追加内容1', { flag: 'a' }, err => {
if (err) {
console.log('写入失败');
return;
}
console.log('写入成功');
});
fs.appendFile('./test.txt', '\n追加内容2', err => {
if (err) {
console.log('写入失败');
return;
}
console.log('写入成功');
});
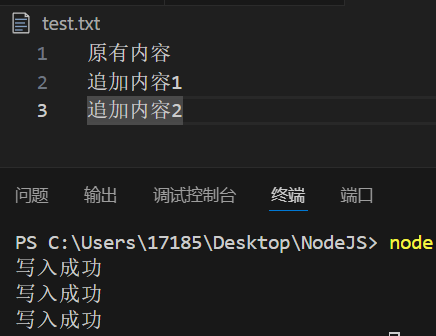
流式写入:先创建写入流对象(可以理解成一个通道/链接),再使用write函数追加写入,最后关闭通道。与python里面的文件写入类似
const fs = require('fs');
const ws = fs.createWriteStream('./test.txt'); //创建写入流对象
ws.write('追加内容1\n');
ws.write('追加内容2\n');
ws.write('追加内容3\n'); //追加写入
ws.close(); //关闭通道(可省略)

流式写入可以减少打开/关闭文件的次数,适用于大文件写入/频繁写入,而前面的方法适用于频率较低的写入
文件写入的应用场景:下载文件、安装软件、保存程序日志(比如git)、文本编辑器保存、视频录制等等
注意:当需要持久化保存数据时,应使用文件写入
文件读取
-
异步读取
fs.readFile(file[, option], callback),无返回值-
file文件名,如果不存在则自动创建 -
callback回调函数,接收2个参数,分别为err和data-
err与文件写入中的相同 -
data为文件内容,是buffer的形式
-
-
options其它选项
-
-
同步读取
fs.readFileSync(file[, option]),直接返回读取的数据,也是buffer的形式 -
流式读取:可以理解成将文件分成多块读取,每一块的最大大小为65536字节(64KB),适用于大文件的读取
const rs = fs.createReadStream(file); //创建读取流对象 rs.on('data', chunk => { }); //绑定data事件 rs.on('end', () => { }); //绑定end事件-
data事件:每读取一块文件时触发,读取到的数据存入
chunk中 -
end事件(可选):当整个文件读取完成后触发
-
例:
//异步读取
const fs = require('fs');
fs.readFile('./test.txt', (err, data) => {
if (err) {
console.log("读取失败");
return;
}
console.log(data);
console.log(data.toString());
});
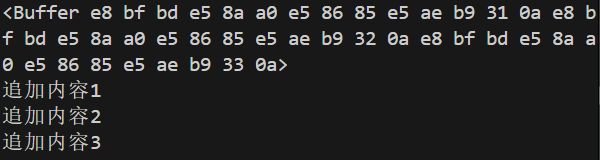
//同步读取
const fs = require('fs');
let data = fs.readFileSync('./test.txt');
console.log(data.toString());
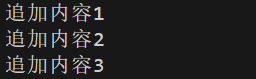
//流式读取
const fs = require('fs');
const rs = fs.createReadStream("./data/test.jpg");
rs.on('data', chunk => {
console.log(chunk);
console.log(chunk.length);
});
rs.on('end', () => {
console.log("读取完毕");
});
注:使用的文件大小为146KB
文件读取的应用场景:程序运行、打开/查看文件、上传文件、git查看日志等等
例:文件复制,即先读取文件,再写入
const fs = require('fs');
//方式1:同步读写
const data = fs.readFileSync('./test.txt'); //读取文件内容
fs.writeFileSync('./test_copy.txt', data); //写入文件
//方式2:异步读写
fs.readFile('./test.txt', (err, data) => {
if (err) {
console.log("读取失败");
return;
}
fs.writeFile('./test_copy.txt', data, err => {
if (err) {
console.log('写入失败');
return;
}
});
});
//方式3:流式读写
const rs = fs.createReadStream('./test.txt'); //读取流对象
const ws = fs.createWriteStream('./test_copy.txt'); //写入流对象
rs.on('data', chunk => {
ws.write(chunk); //每读取一块就写入一块
});
//方式4:流式读写,使用pipe函数,效果更好
rs.pipe(ws); //pipe:将rs的数据输入ws中
对于同步/异步读取,是先把文件的所有内容获取,存入内存中,再进行写入,因此读取大文件需要消耗大量的内存空间;而对于流式读写,每次只读取64KB的内容并写入,因此理想状态下只需要64KB的内存空间就可以完成(实际情况下由于读取速度更快,会有一些内容堆积在内存中等待写入,但仍比同步/异步读取占用内存小)
使用process模块来查看内存占用:
-
同步读写
const fs = require('fs'); const process = require('process'); const data = fs.readFileSync('./test.png'); fs.writeFileSync('./test_copy1.png', data); console.log(process.memoryUsage()); //rss: 29728768 -
异步读写
const fs = require('fs'); const process = require('process'); fs.readFile('./test.png', (err, data) => { if (err) { console.log("读取失败"); return; } fs.writeFile('./test_copy2.png', data, err => { if (err) { console.log('写入失败'); return; } console.log(process.memoryUsage()); }); }); //rss: 29859840 -
流式读写
const fs = require('fs'); const process = require('process'); const rs = fs.createReadStream('./test.png'); const ws = fs.createWriteStream('./test_copy3.png'); rs.pipe(ws); console.log(process.memoryUsage()); //rss: 28454912
由于这里使用的文件大小仅为1MB左右,内存节省不明显。如果想要看到明显效果,至少要10MB数量级
文件移动和重命名
fs.rename(文件原路径, 文件新路径, callback)异步/fs.renameSync(文件原路径, 文件新路径)同步
-
移动和重命名都是依靠修改文件路径实现
-
回调函数接收一个参数
err
例:
const fs = require('fs');
//重命名,即新旧路径只有文件的名称不同
fs.rename('./test.txt', './new_test.txt', err => {
if (err) {
console.log('重命名失败');
return;
}
console.log('重命名成功');
});
//移动,即新旧路径不同
setTimeout(() => { //重命名结束后再移动
fs.rename('./new_test.txt', './test/new_test.txt', err => {
if (err) {
console.log('移动失败');
return;
}
console.log('移动成功');
});
setTimeout(() => { //移动结束后再操作
//移动
fs.renameSync('./test/new_test.txt', './new_test.txt');
//重命名
fs.renameSync('./new_test.txt', './test.txt');
}, 0);
}, 0);
在上面的代码中,我们将'./test.txt'重命名为'./new_test.txt',之后移动到'./test'文件夹中,最后又将这一过程复原
注:移动到的新文件夹必须是已存在的
文件删除
-
fs.unlink(文件路径, callback)异步/fs.unlinkSync(文件路径)同步 -
fs.rm(文件路径, callback)异步/fs.rmSync(文件路径)同步
例:
const fs = require('fs');
fs.rm('./test.txt', err => {
if (err) {
console.log('删除失败');
return;
}
console.log("删除成功");
});
fs.unlinkSync('./test1.txt');
文件夹操作
-
创建文件夹(异步/同步)
fs.mkdir(文件夹路径[, options], callback)/fs.mkdirSync(文件夹路径[, options])-
回调函数接收一个参数
err -
递归创建(即创建一个a文件夹,在其中再创建一个b文件夹):设置option属性
recursive: true
-
-
删除文件夹(异步/同步)
-
fs.rmdir(文件夹路径[, options], callback)/fs.rmdirSync(文件夹路径[, options]) -
fs.rm(文件夹路径[, options], callback)/fs.rmSync(文件夹路径[, options])(建议使用) -
回调函数接收一个参数
err -
需要文件夹为空才能删除
-
递归删除(即文件夹内还有文件/文件夹):还是设置option属性
recursive: true
-
-
读取文件夹(异步/同步)
fs.readdir(文件夹路径[, options], callback)/fs.readdirSync(文件夹路径[, options])-
回调函数接收2个参数
err和data,后者以数组形式列出文件夹中的内容(文件夹和文件的名称) -
对于同步读取,它将读取结果直接返回
-
例:
-
创建
const fs = require('fs'); fs.mkdir('./html', err => { if (err) { console.log('创建失败'); return; } console.log('创建成功'); }); //递归创建 fs.mkdirSync('./a/b', { recursive: true }); -
读取
const fs = require('fs'); fs.readdir('./', (err, data) => { if (err) { console.log('读取失败'); return; } console.log('./', data); }); console.log('../', fs.readdirSync('../'));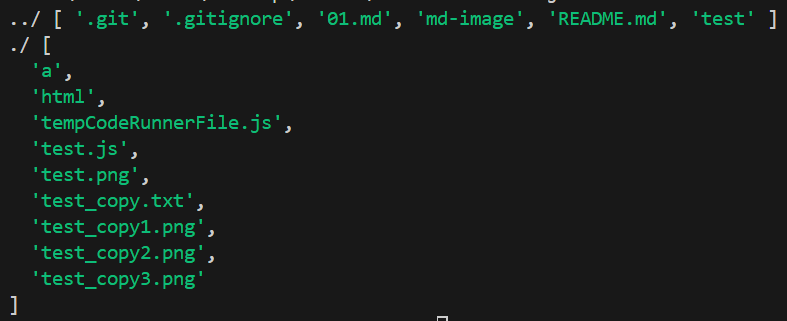
-
删除
const fs = require('fs'); fs.rmdirSync('./html'); //递归删除 fs.rmdir('./a', { recursive: true }, err => { if (err) { console.log('删除失败'); return; } console.log('删除成功'); }); //递归删除 fs.rm('./a', { recursive: true }, err => { if (err) { console.log('删除失败'); return; } console.log('删除成功'); });
查看资源状态
fs.stat(文件路径, callback)/fs.statSync(文件夹路径[, options])
-
回调函数接收2个参数
err和data,后者以类似于对象的形式列出文件信息 -
对于同步读取,它将读取结果直接返回
例:
const fs = require('fs');
fs.stat('./test.png', (err, data) => {
if (err) {
console.log('操作失败');
return;
}
console.log(data);
});
console.log(fs.statSync('./test.png'));
Stats {
dev: 915514105,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 23925373020643384,
size: 1317887,
blocks: 2576,
atimeMs: 1724769221738.6213,
mtimeMs: 1718964433265.3577,
ctimeMs: 1724768416407.0315,
birthtimeMs: 1724768412410.15,
atime: 2024-08-27T14:33:41.739Z,
mtime: 2024-06-21T10:07:13.265Z,
ctime: 2024-08-27T14:20:16.407Z,
birthtime: 2024-08-27T14:20:12.410Z
}
-
size:文件大小 -
birthtime:文件创建时间 -
atime/mtime/ctime:最后一次访问/修改文件内容/修改文件状态的时间-
当文件内容更改时,mtime才会更新
-
更改文件任何属性(包括内容),ctime都会更新
-
data.isFile()/data.isDirectory()判断该文件是不是文件/文件夹
const fs = require('fs');
fs.stat('./test.png', (err, data) => {
if (err) {
console.log('操作失败');
return;
}
console.log(data.isDirectory()); //false
console.log(data.isFile()); //true
});
文件路径说明
相对路径:
-
./xxx等效于xxx -
../xxx是上一级的文件
绝对路径:
-
D:/xxx -
/xxx常见于Linux,但Windows中也可以使用,它表示在当前工作路径的根目录下使用xxx文件- 例如当前工作路径是
C:/a/b,/xxx指的就是C:/xxx;当前工作路径是D:/a/b/c,/xxx指的就是D:/xxx
- 例如当前工作路径是
一个小问题:现想要在test.js的目录下创建一个新文件test.txt,正常情况下应使用:
fs.writeFileSync('./test.txt', '111');
之后在test.js的目录下执行
C:\Users\17185\Desktop\NodeJS\test> node test.js
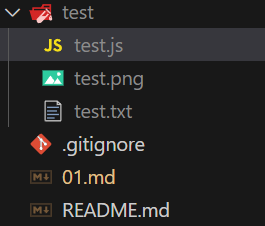
如果我们在test.js的上一级目运行test.js:
C:\Users\17185\Desktop\NodeJS> node test/test.js
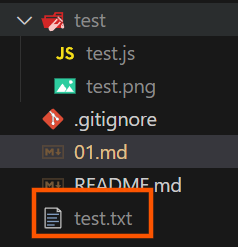
发现文件被创建在了上一级目录中
这是因为fs中相对路径参照的是运行该文件的命令行的工作目录,而不是该文件所在目录
解决办法:使用绝对路径__dirname,它可以简单理解为一个“全局变量”,值为所在js文件的所在目录的绝对路径
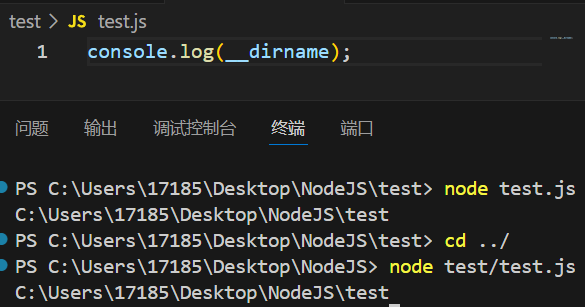
将__dirname与相对路径进行拼接,就可以解决上面的问题:
const fs = require('fs');
fs.writeFileSync(__dirname + '/test.txt', '333');
此时无论在哪里运行该js文件,始终是在它同级目录下创建新文件
补充:__filename类似于__dirname,它保存文件的绝对路径
console.log(__filename);
//C:\Users\17185\Desktop\NodeJS\test\test.js
案例:批量重命名

可以看到文件排序是按1、2、3、10、11的顺序,但在其它软件中,显示方式可能是1、10、11、2、3
为解决这一问题,可以在1、2、3这些个位数的前面加一个0,变成01、02、03
思路:
-
先得到所有文件名
-
遍历该数组,使用
split('-')将每个文件名按-拆分;之后使用shift()取出第一项即为文件序号,如果<10就是个位数,加0;最后使用join('-')将文件序号与数组剩余部分拼接成字符串 -
根据新旧字符串进行重命名
const fs = require('fs');
const file_list = fs.readdirSync('./test'); //所有的文件
file_list.forEach(file_name => { //遍历数组
const file_name_list = file_name.split('-'); //拆分
let num = file_name_list.shift(); //序号
if (parseInt(num) < 10) { //如果是个位数就加上0
num = '0' + num;
}
const new_file_name = [num, ...file_name_list].join('-'); //合并得到新文件名
fs.renameSync(`./test/${file_name}`, `./test/${new_file_name}`); //重命名
});

现要对文件序号进行更改,使其连续

思路:在循环外设置索引,标识是第几个文件
const fs = require('fs');
const file_list = fs.readdirSync('./test'); //所有的文件
let index = 1;
file_list.forEach(file_name => { //遍历数组
const file_name_list = file_name.split('-'); //拆分
file_name_list.shift(); //删除第一个元素,即原有序号
const num = index < 10 ? '0' + index : '' + index; //新序号
index++; //更新序号
const new_file_name = [num, ...file_name_list].join('-'); //合并得到新文件名
fs.renameSync(`./test/${file_name}`, `./test/${new_file_name}`); //重命名
});
path模块
提供了操作路径的功能
| API | 说明 |
|---|---|
path.resolve(绝对路径, 相对路径) |
拼接规范的绝对路径(常用) |
path.sep |
获取路径分隔符 |
path.parse(路径) |
解析路径 |
path.basename(路径) |
获取文件名(包括后缀) |
path.dirname(路径) |
获取文件所在目录名 |
path.extname(路径) |
获取文件扩展名 |
详细介绍:
-
path.resolve(绝对路径, 相对路径)其中绝对路径一般都是__dirname,它可以实现文件路径说明中提到的拼接功能const path = require('path'); console.log(__dirname + './test.txt'); //不规范的拼接(路径中/和\混用) //C:\Users\17185\Desktop\NodeJS\test./test.txt console.log(path.resolve(__dirname, './test.txt')); //常用方法 //C:\Users\17185\Desktop\NodeJS\test\test.txt console.log(path.resolve(__dirname, 'test.txt')); //可以省略./ //C:\Users\17185\Desktop\NodeJS\test\test.txt console.log(path.resolve('/test.txt')); //只传一个绝对路径 //C:\test.txt console.log(path.resolve('/a', 'b.txt')); //也可以 //C:\a\b.txt console.log(path.resolve(__dirname, '/a.txt')); //不行,函数会只识别传入的最后一个绝对路径 //C:\a.txt console.log(path.resolve(__dirname, '/a', 'b.txt')); //第一个绝对路径__dirname被忽略 //C:\a\b.txt -
path.sep获取操作系统的路径分隔符(Windows是\,Linux是/)const path = require('path'); console.log(path.sep); //返回'\' -
path.parse(路径)解析路径,以对象形式返回路径的相关信息const path = require('path'); console.log(path.parse(__filename)); //也可以: console.log(path.parse('C:\\Users\\17185\\Desktop\\NodeJS\\test\\test.js')); //注意是两个\(转义){ root: 'C:\\', 所在根目录 dir: 'C:\\Users\\17185\\Desktop\\NodeJS\\test', 所在文件夹 base: 'test.js', 文件名(包括后缀) ext: '.js', 后缀 name: 'test' 文件名(不包括后缀) }也可以传入相对路径,但结果不完整
const path = require('path'); console.log(path.parse('./test.js')); //{ root: '', dir: '.', base: 'test.js', ext: '.js', name: 'test' } -
path.basename(路径)获取文件名(包括后缀) -
path.dirname(路径)获取文件所在文件夹 -
path.extname(路径)获取文件后缀const path = require('path'); const file_name = 'C:\\Users\\17185\\Desktop\\NodeJS\\test.js'; console.log(path.basename(file_name)); //test.js console.log(path.dirname(file_name)); //C:\Users\17185\Desktop\NodeJS console.log(path.extname(file_name)); //.js
http模块
HTTP基本概念
HTTP(hypertext transfer protocol)超文本传输协议:对浏览器和服务器间的通信作约束
-
请求:浏览器向服务器发送数据,发送的内容称为请求报文
-
响应:服务器给浏览器返回结果,返回的内容称为响应报文
为获取请求与响应的具体内容,这里安装fiddler软件,它可以作为浏览器和服务器间通信的中介,监听请求/响应内容
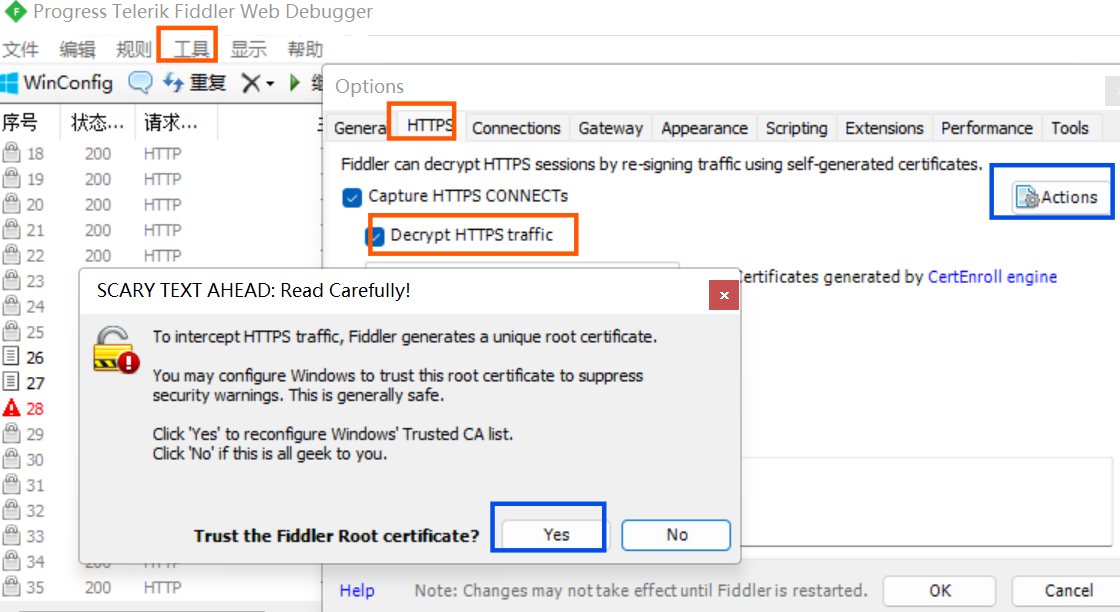
安装完后,点击tools->options->https->decrypt https traffic,之后在弹出的对话框中点击yes;若没有弹出对话框,就点击action->trust root certificate。最后重启fiddler
为更好的监听,建议将下边栏中的all processes改为web browsers,这样就只监听浏览器中的请求与响应
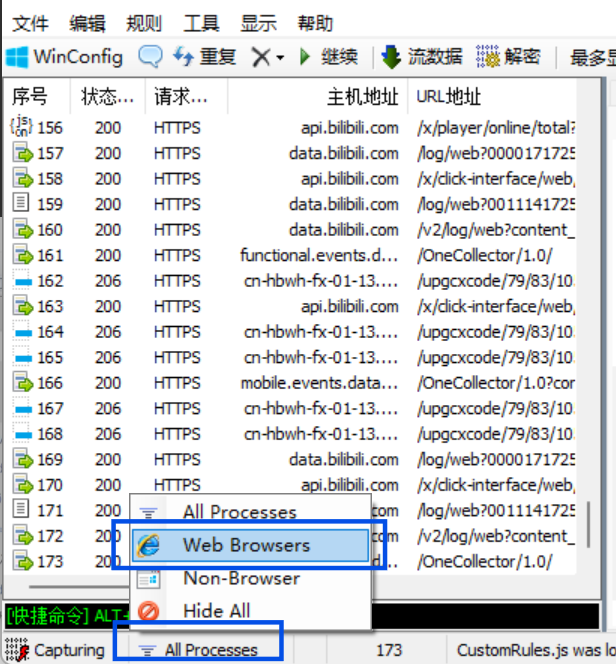
注意:建议使用chrome来进行测试,其它浏览器可能监听不到
双击左侧框中的某条报文,可以在右边框中查看详细信息,其中上面是请求、下面是响应。如果想要看报文原文,点击右侧栏上方的Raw(中文版是数据)。如果有乱码,就点击click to decode
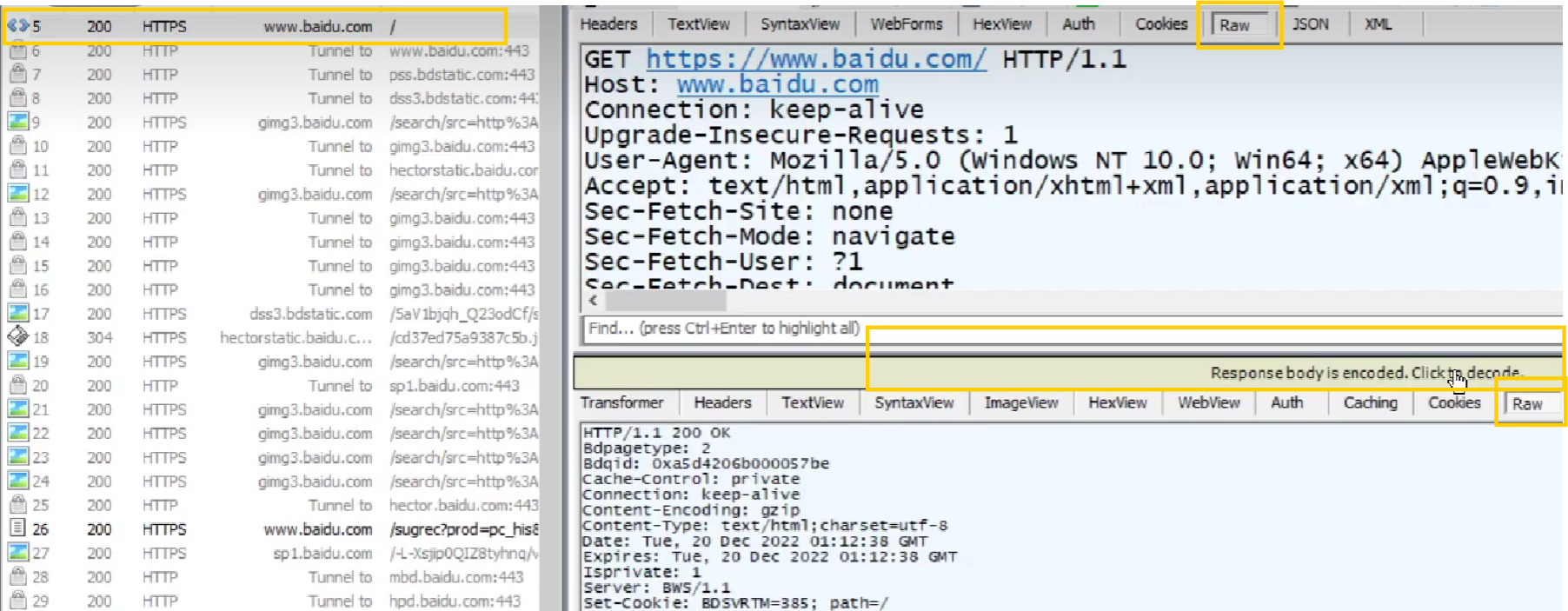
请求
请求报文结构:
-
第一行:请求行
-
第二行~空行:请求头
-
之后的部分:请求体(不一定有)
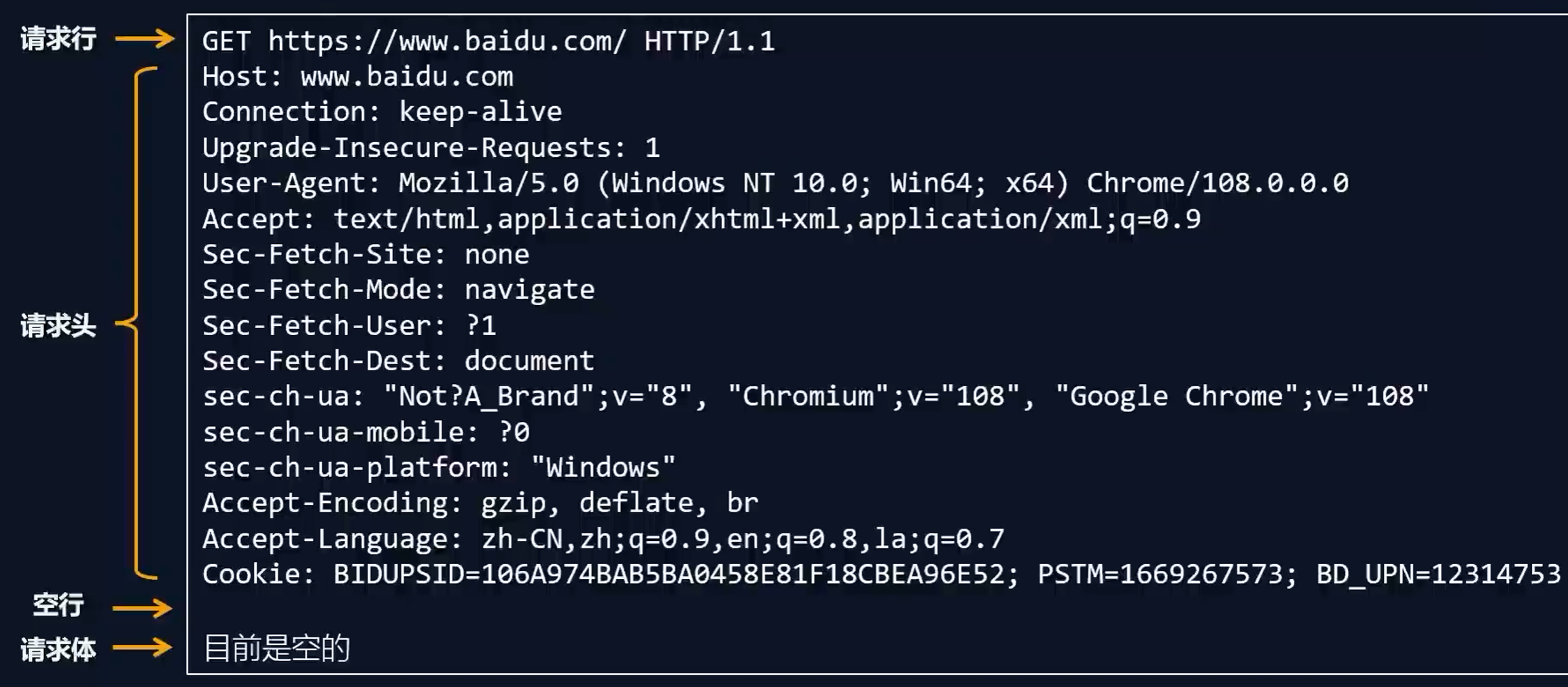
请求行:由三部分组成——请求方法、url、HTTP版本号

-
请求方法:
方法 作用 GET(常用) 获取数据 POST(常用) 新增数据 PUT/PATCH 更新数据 DELETE 删除数据 -
URL(uniform resource locator)统一资源定位符,组成部分:(以https://www.baidu.com/为例)
-
https:协议名,后面的://为协议的固定组成部分 -
www.baidu.com:主机名,可以是这样的域名,也可以是10.20.30.40这样的IP地址 -
最后的
/:路径,用于定位服务器中某部分的资源

-
端口号:http默认端口号是80,https默认端口号是443,如果使用指定协议的默认端口号就省略不写
-
查询字符串:向服务器传入额外的数据。它是键值对的形式,如上面的
keyword和psort就是键,oneplus和3就是值,键值间以=连接,每个键值对间以&分隔
-
-
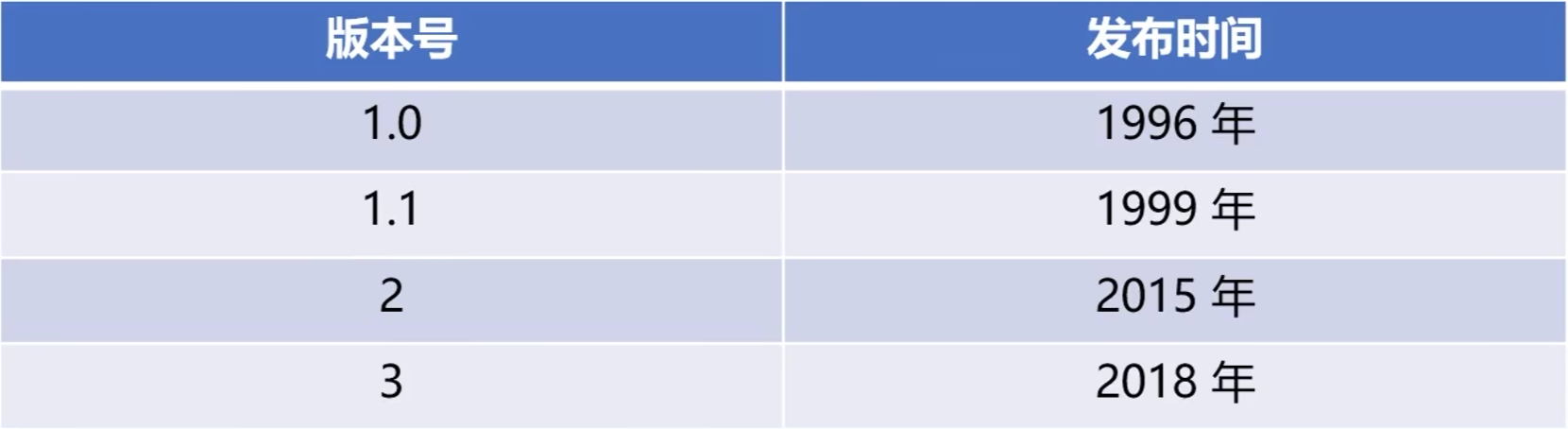
HTTP版本号:
请求头:记录浏览器的相关信息。也是键值对的形式,如Host是键名,www.baidu.com是键值,键值间以:连接
-
User-Agent:浏览器平台及版本号 -
Accept:浏览器能处理的数据类型 -
Accept-Encoding:浏览器支持的压缩方式 -
Accept-Language:浏览器支持的语言 -
Connection: keep-alive:保持连接通道,提高效率 -
Upgrade-Insecure-Requests: 1升级HTTP协议为HTTPS,提高安全性 -
还会包括一些与请求头有关的内容
请求体:内容格式非常灵活,可以设置任意内容

上图是一个登录请求的请求体,以键值对的形式发送了账号、密码等信息

如图,还可以是json的形式,这种方式较常用
响应
响应报文与请求报文结构类似
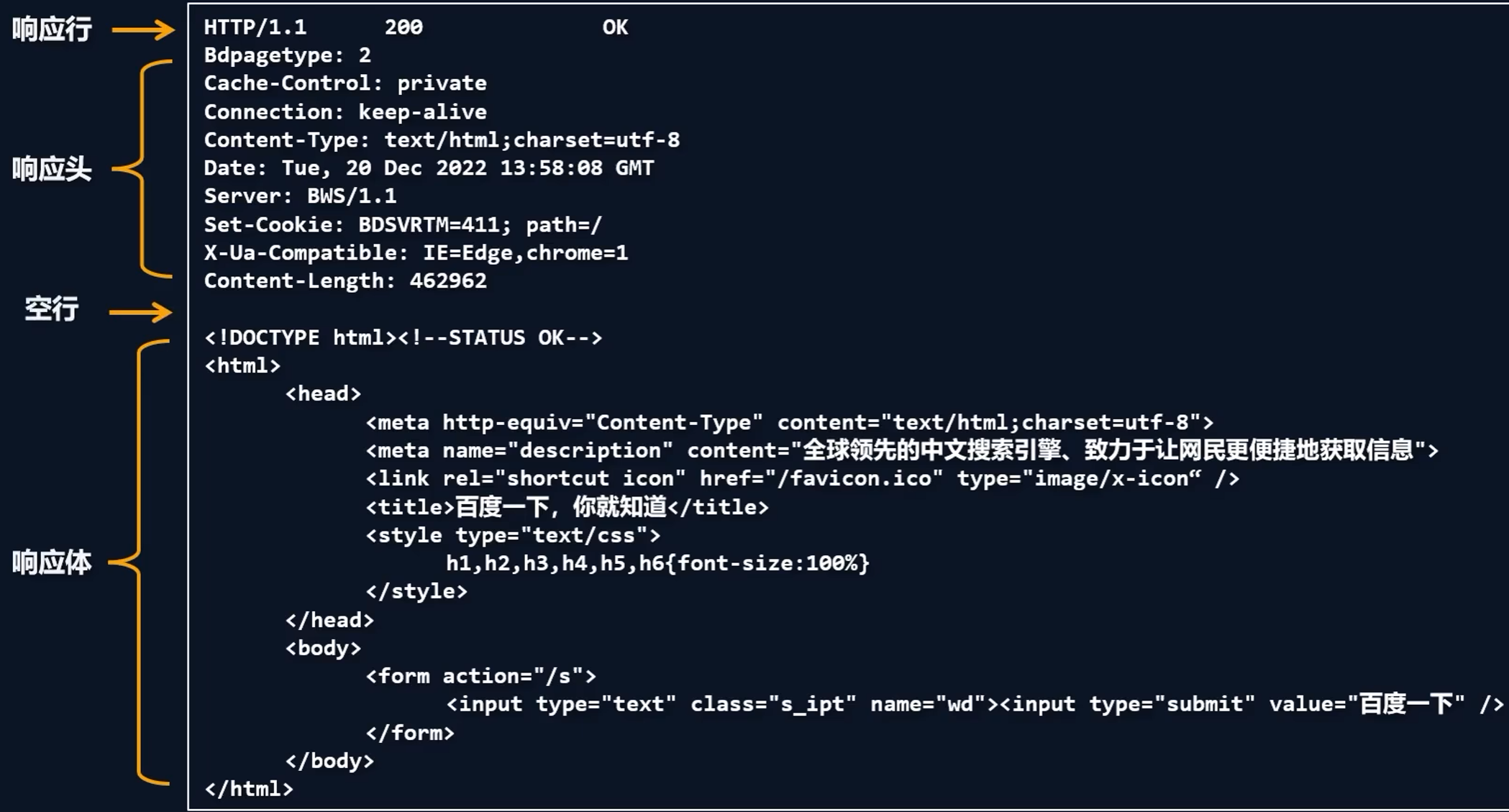
响应行:由三部分组成——HTTP版本号、响应状态码、响应状态的描述

-
HTTP版本号同请求
-
响应状态码:标识响应的结果状态
状态码 含义 200 请求成功 403 禁止请求 404 找不到资源 500 服务器内部错误 响应状态码通过开头的数字进行分类:
状态码 含义 1xx 信息响应 2xx 成功响应 3xx 重定向消息 4xx 客户端错误响应 5xx 服务器错误响应 -
响应状态的描述:是一个字符串,绝大部分时候与响应状态码对应
状态码 状态描述 200 OK 403 Forbidden 404 Not Found 500 Internal Server Error
响应头:记录与服务器相关的内容
-
Server:服务器使用的技术 -
Date:响应的时间 -
Content-Type(重要):响应体内容的格式和字符集 -
Content-Length:响应体内容的长度,单位是字节 -
如果某个响应头不能在上面网站中搜索到,则可能是自定义的响应体
响应体:格式也很灵活,如HTML、CSS、js、图片、视频、json等


如图,除了最上面列举的HTML,也可以是CSS、js、图片、json等
IP
用于标识网络中的设备,实现设备间通信。是一段长度为32的2进制数字标识,8位为1组,通常每组都转为10进制表示,每组间以.分隔,如124.161.107.254。每个接入互联网的设备都有一个自己的IP
因为上述IP只有2^32^个,如果每个设备的IP都不同,IP就不够用了
解决办法:共享IP,即每个区域/家庭中的所有设备使用同一个IP
例如,家里面有4台联网设备,它们都连接到路由器,此时路由器会为它们分配不同的IP,如192.168.1.2、192.168.1.3、192.168.1.4、192.168.1.5,路由器也有一个IP地址192.168.1.1,这样就它们形成了一个网络,称为局域网,上述IP称为局域网IP/私网IP,这些联网设备间可以相互通信,但无法与其它局域网内的设备通信
这时就需要将局域网连接到互联网中,方法是给路由器再接一根网线,此时它又会有一个IP,如180.91.213.151,称为广域网IP/公网IP,每个局域网通过公网IP进行通信。共享IP实际上共享的是公网IP,即不同局域网内可以用相同的私网IP,只需公网IP不同即可
除了公网私网IP之外,还有本地回环IP,最常用的是127.0.0.1,它始终表示本机

端口
是应用程序的数字标识,用于实现不同主机应用程序间的通信。现代计算机有65536个端口(端口号0~65535),一个应用程序可以使用一个或多个端口
当一台主机向另一台主机发送信息时,需要知道该条信息是给目标主机的哪个程序发送的,此时端口就起作用了
通常,端口号写到IP后面,与IP以:连接
如126.35.69.58主机的端口号为18的程序,向192.168.1.3主机的端口号为21的程序发送信息,就可表示为126.35.69.58:18->192.168.1.3:21
基本使用
-
导入模块
http -
创建服务对象
const server = http.createServer((request, response)=>{ }),createServer函数接收一个回调函数作参数,返回服务对象server。该回调函数有两形参request和response,分别是对请求报文和响应报文的封装对象,在服务接收到HTTP请求时执行 -
监听端口,启动服务
server.listen(端口号, ()=>{}),其中的回调函数在服务启动后执行
例:
const http = require('http'); //导入模块
const server = http.createServer((request, response) => { //创建服务对象
response.end('hello http server'); //设置响应体
});
server.listen(9000, () => {
console.log("服务已经启动");
});

服务启动后,本机的9000端口就被test.js占用,如果有程序向该端口发送报文,就会触发createServer中的回调函数
如何向该端口发报文:使用浏览器,输入网址http://127.0.0.1:9000/http://localhost:9000即可
具体的报文内容:
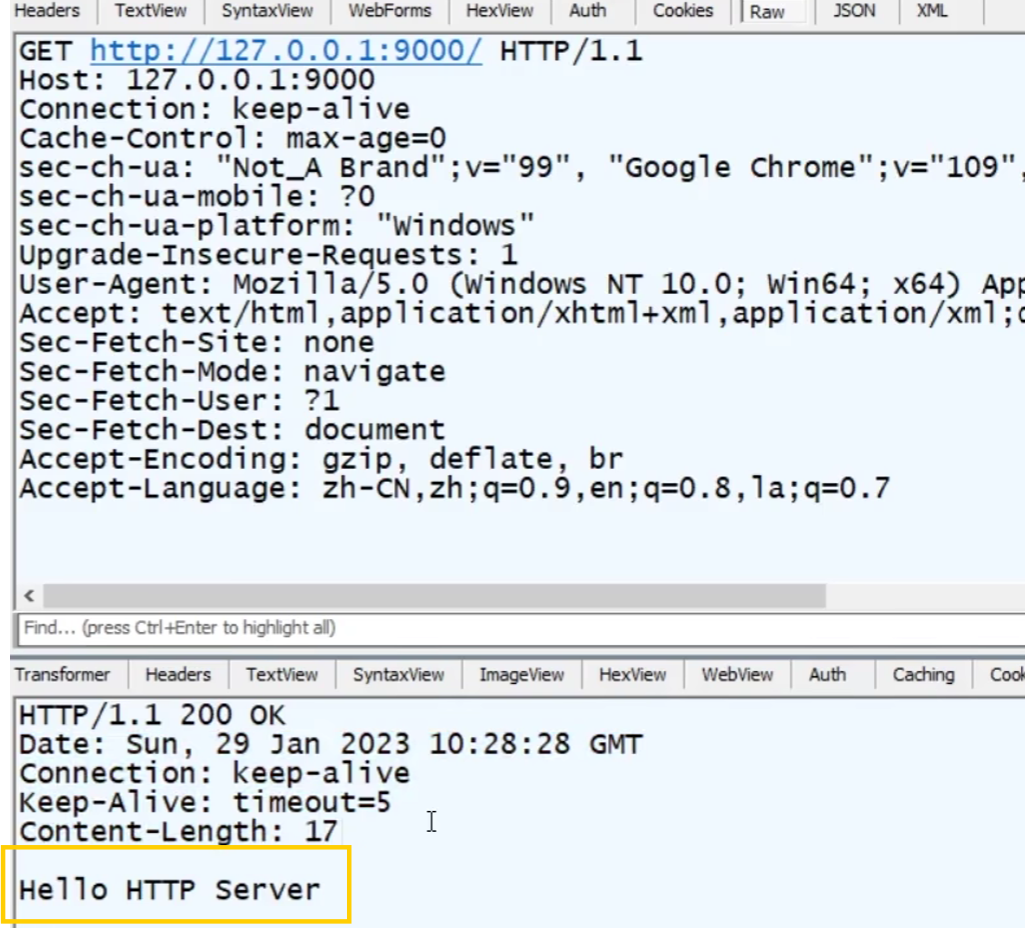
其中响应行/响应体部分是http模块自己默认配置的
注意事项:
-
停止服务:命令行中按
CTRL+c -
当服务启动后,想要更新代码,必须要先停止服务,再重启之后才生效
-
响应体里面中文乱码解决:在设置响应体之前加上
response.setHeader('content-type', 'text/html;charset=utf-8'),它的含义是标识响应体是HTML格式,且字符集是utf-8const http = require('http'); const server = http.createServer((request, response) => { response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集 response.end('发送响应报文'); //设置响应体 }); server.listen(9000, () => { console.log("服务已经启动"); });
-
端口被占用”address already in use”
-
停止占用该端口的服务
-
换一个端口
-
-
HTTP协议的默认端口号是80,如果在该端口上启动服务,在使用浏览器发请求时,网址中就不必写上
:80,请求报文中也不会出现:80。其它常用端口:3000、8080、8090、9000等,https协议的默认端口号是443const http = require('http'); const server = http.createServer((request, response) => { response.setHeader('content-type', 'text/html;charset=utf-8'); response.end('发送响应报文'); }); server.listen(80, () => { console.log("服务已经启动"); });

-
如何找到占用某个端口的程序:开始菜单搜索“资源监视器”->
侦听端口,记住占用端口程序的PID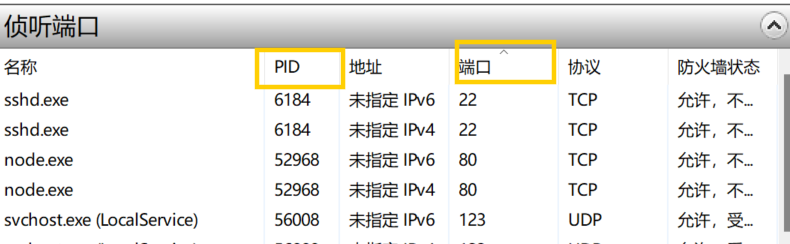
再到任务管理器中根据pid找到对应程序,右键->
结束任务即可关闭该程序
在浏览器中查看HTTP报文
启动服务->进入指定网址->f12打开控制台->网络->刷新页面
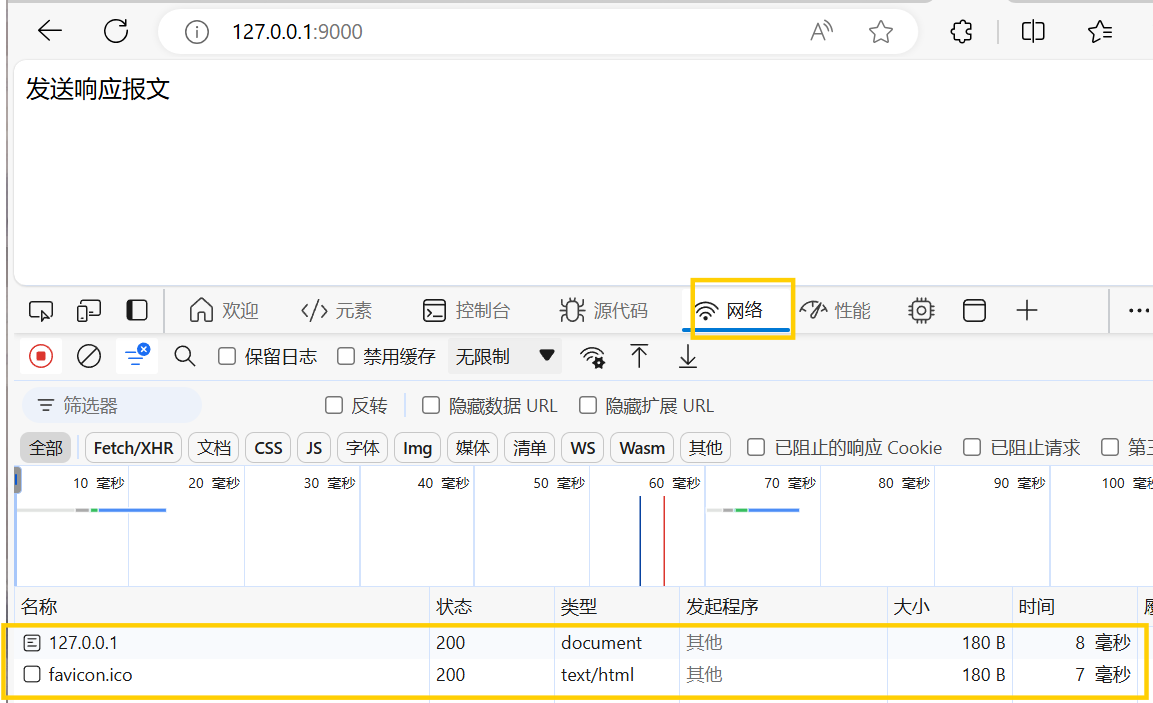
其中我们关注的是127.0.0.1这个我们发送的报文
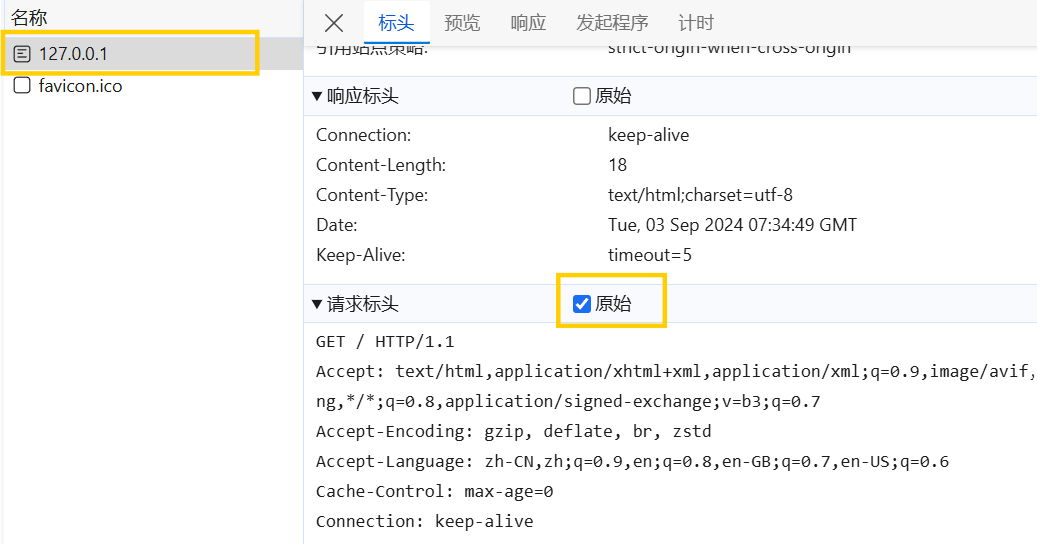
单击它,可以看到响应头/请求头,如果想看响应行/请求行,就点击原始/查看源代码
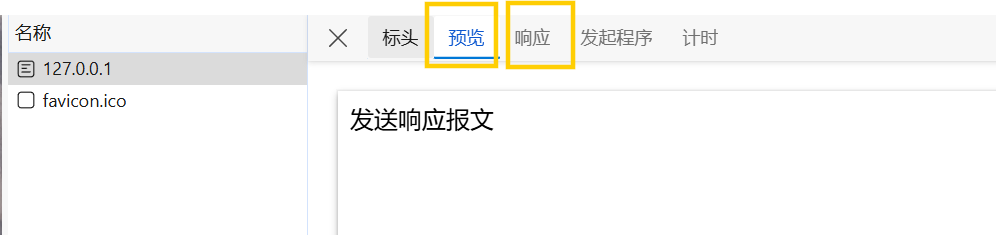
在预览/响应中可以看到响应体
查看请求体:因为上面都是get请求,一般没有请求体,这里我们新建一个post请求
新建一个HTML文件,创建一个表单
<form action="http://127.0.0.1:9000" method="post">
<input type="text" name="username">
<input type="text" name="password">
<input type="submit" value="提交">
</form>
在浏览器中打开,输入账号密码后点击提交
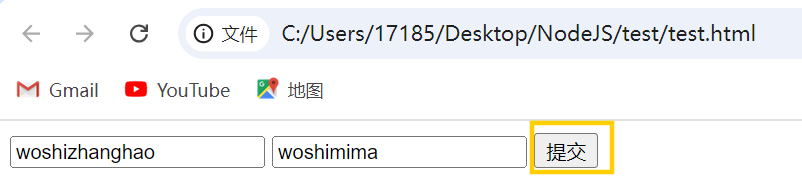
在跳转到的页面http://127.0.0.1:9000中查看127.0.0.1报文,发现多了一个载荷/负载,这就是请求体内容,点击查看源代码/查看源即可看到原始请求体
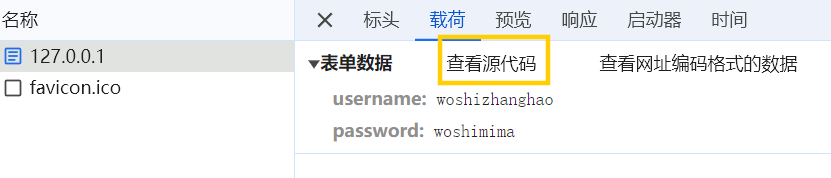
查询字符串:输入网址http://127.0.0.1:9000/search?keyword=h5&num=1
f12打开控制台->网络->search?keyword=h5&num=1->载荷
这样查看更加直观
获取请求报文
使用createServer的回调函数中的request对象
| 含义 | 语法 |
|---|---|
| 请求方法 | request.method(常用) |
| HTTP版本 | request.httpVersion |
| 请求路径 | request.url(常用) |
| url路径 | require('url').parse(request.url).pathname(常用) |
| url查询字符串 | require('url').parse(request.url, true).query(常用) |
| 请求头 | request.headers(常用) |
| 请求体 | request.on('data', chunk=>{})获取数据request.on('end',()=>{})获取数据完毕后触发 |
注:
-
request.url只包含路径以及查询字符串,无法获取URL中的域名、协议和端口 -
request.headers将请求信息转化成一个对象,并将属性名都转化成了小写 -
路径:如果访问网站的时候,只填写了IP地址或者是域名信息,此时请求的路径为
/ -
favicon.ico:是浏览器自动发送的请求
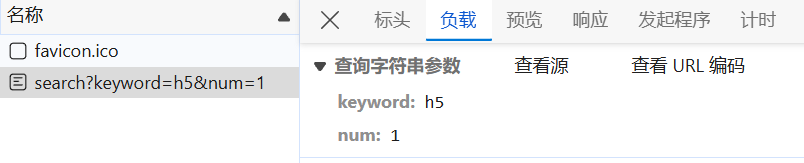
例:获取请求行/请求体
const http = require('http');
const server = http.createServer((request, response) => {
console.log("请求方法:" + request.method); //请求方法
console.log("请求url:" + request.url); //请求url
console.log("HTTP版本:" + request.httpVersion); //HTTP版本
console.log(request.headers); //请求头
response.end('createServer');
});
server.listen(9000, () => {
console.log("服务已经启动");
});
-
为什么输出了两组数据:因为有两个请求,每个请求都console一遍
-
为什么
request.headers结果中有的键加了引号:如果键名中用-进行连接,因为-不是标准标识符,所以加引号
例:获取请求体
const http = require('http');
const server = http.createServer((request, response) => {
let body = ''; //声明一个空字符串用于接收数据
request.on('data', chunk => { //绑定data事件
body += chunk; //将获取到的数据添加到结果中
});
request.on('end', () => { //绑定end事件
console.log(body); //获取完毕后输出body
response.end('createServer'); //进行响应
});
});
server.listen(9000, () => {
console.log("服务已经启动");
});
与在浏览器中查看HTTP报文的查看请求体相同,都需要一个post请求,创建HTML文件
<form action="http://127.0.0.1:9000" method="post">
<input type="text" name="username">
<input type="text" name="password">
<input type="submit" value="提交">
</form>
点击提交按钮,可看到输出结果
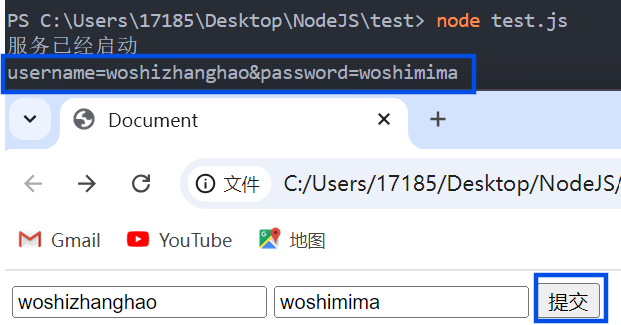
注意:chunk本质上是一个buffer,当其做加法运算时,会自动转为字符串,无需额外toString
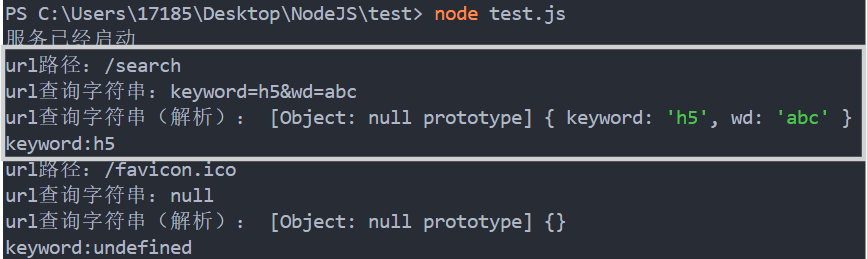
例:获取路径和查询字符串
const http = require('http');
const url = require('url'); //导入url模块
const server = http.createServer((request, response) => {
const path = url.parse(request.url); //解析后的url
console.log('url路径:' + path.pathname);
console.log('url查询字符串:' + path.query);
const query = url.parse(request.url, true).query; //经过解析后的路径
console.log('url查询字符串(解析):', query);
console.log('keyword:' + query.keyword);
response.end('createServer');
});
server.listen(9000, () => {
console.log("服务已经启动");
});
输入网址:http://127.0.0.1:9000/search?keyword=h5&wd=abc
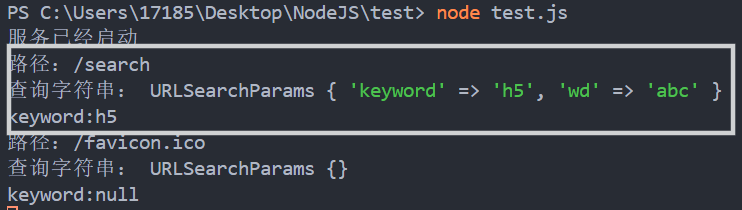
获取路径和查询字符串的另一种方法:使用URL对象
let url = new URL(request.url, 域名)
url.pathname //路径
url.searchParams //查询字符串
url.searchParams.get('keyword') //查询字符串keyword
注:
-
new URL(request.url, 域名)中的域名可以任意写,因为它的作用只是让request.url称为一个完整的网址,不影响路径和查询字符串解析 -
在较新版本中,使用url模块的方法被弃用,推荐使用这种方法
const http = require('http');
const server = http.createServer((request, response) => {
let url = new URL(request.url, 'http://1.1.1.1');
console.log("路径:" + url.pathname);
console.log("查询字符串:", url.searchParams);
console.log("keyword:" + url.searchParams.get('keyword'));
response.end('createServer');
});
server.listen(9000, () => {
console.log("服务已经启动");
});
练习:搭建HTTP服务
| 请求类型(方法) | 请求地址(路径) | 对应的响应体 |
|---|---|---|
| get | /login | 登录页面 |
| get | /reg | 注册页面 |
const http = require('http');
const server = http.createServer((request, response) => {
const { method } = request; //获取请求方法(解构赋值)
const { pathname } = new URL(request.url, 'http://127.0.0.1');
response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集
if (method === 'GET' && pathname === '/login') {
response.end('登录页面');
}
else if (method === 'GET' && pathname === '/reg') {
response.end('注册页面');
}
else {
response.end('Not Found');
}
});
server.listen(9000, () => {
console.log("服务已经启动");
});
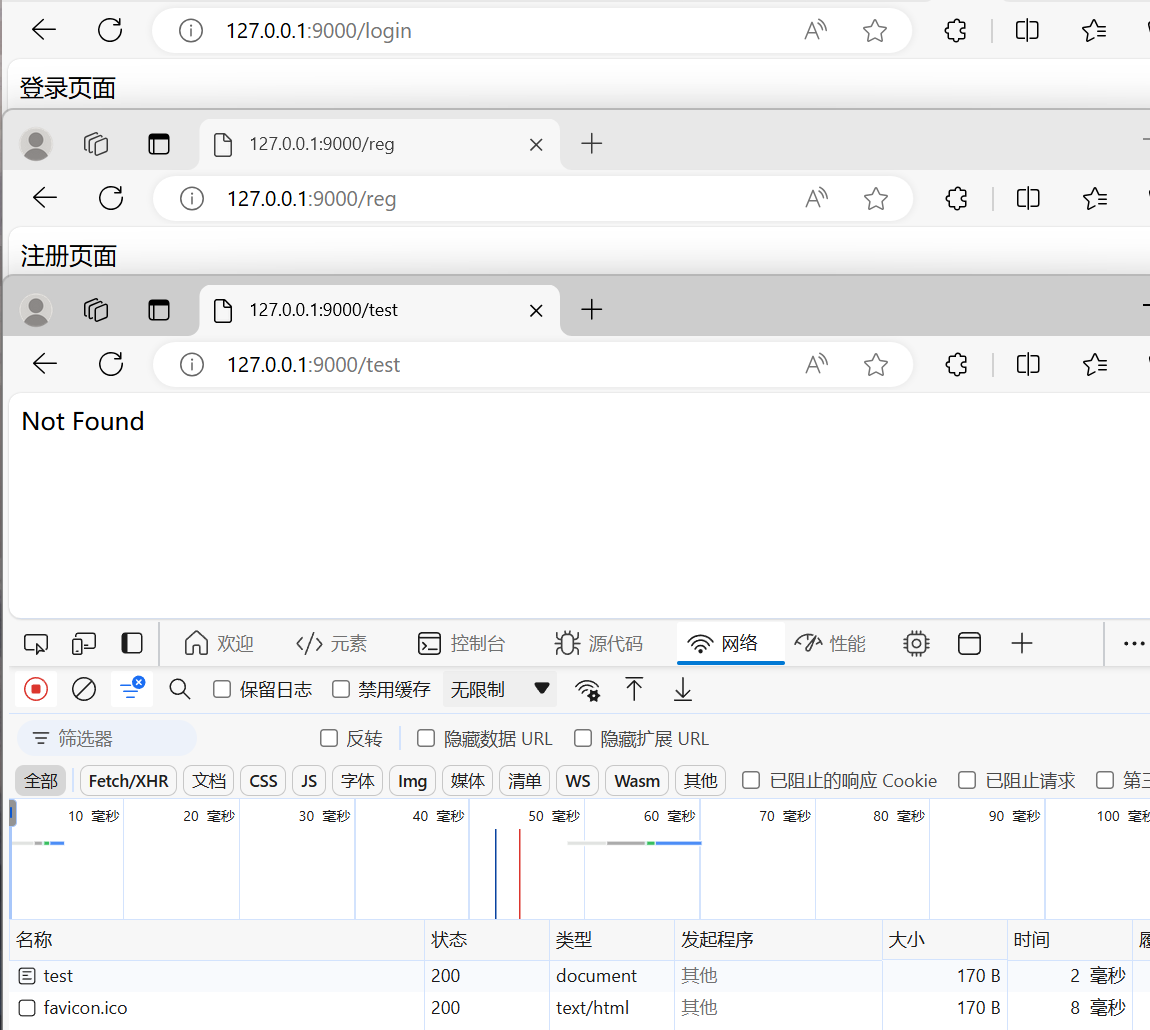
注意:
-
一次回调函数中只能执行一次
end函数(发送一次响应),如果发送多次会报错 -
如果不写最后的else,当路径不是login或reg时,因为一直不
end(返回响应内容),会卡住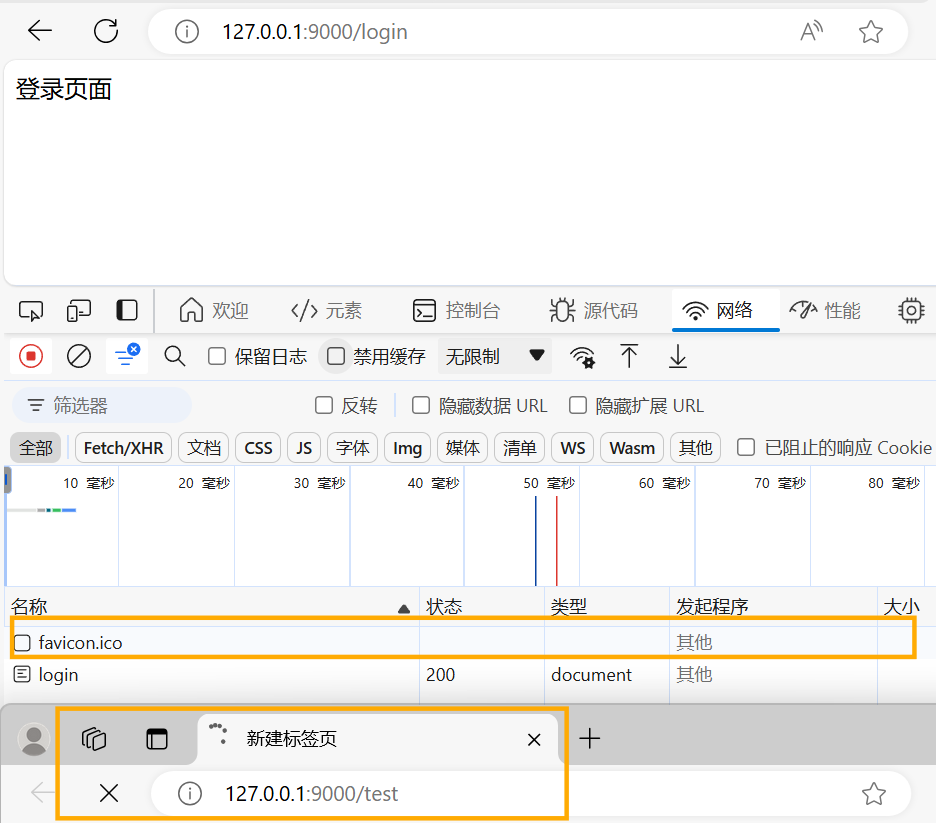
可以看到图标和其它路径都没有响应
设置响应报文
| 作用 | 语法 |
|---|---|
| 设置响应状态码 | response.statusCode = 状态码 |
| 设置响应状态描述 | response.statusMessage = 描述(很少使用) |
| 设置响应头信息 | response.setHeader('头名', '头值') |
| 设置响应体 | response.write('xxx')response.end('xxx') |
注:
-
响应状态描述一般与响应状态码对应,不会单独指定
-
设置响应体的write方法是追加写入,可以有多次write,它们的内容会拼接成最终的响应体;而end只能有且必须有一个,end之后不能再继续写入响应体;end中的内容也可与write中的进行拼接,但用write写入响应体时,end内容一般置为空,只作为响应体写入结束标识
例:
const http = require('http');
const server = http.createServer((request, response) => {
response.statusCode = 203; //响应状态码
response.statusCode = 404; //可以进行覆盖设置
response.statusMessage = 'message'; //响应状态描述
response.setHeader('content-type', 'text/html;charset=utf-8'); //响应头--字符集
response.setHeader('Server', 'Node.js'); //响应头--服务端名字
response.setHeader('myHeader', 'test'); //自定义响应头
response.setHeader('moreHeader', ['a', 'b', 'c']); //多个同名响应头
response.end();
});
server.listen(9000, () => {
console.log("服务已经启动");
});
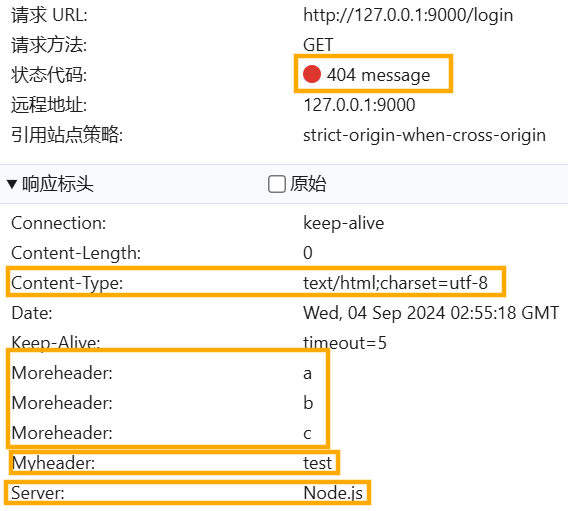
const http = require('http');
const server = http.createServer((request, response) => {
response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集
response.write('响应体1<br>');
response.write('响应体2<br>');
response.write('响应体3<br>');
response.end();
});
server.listen(9000, () => {
console.log("服务已经启动");
});
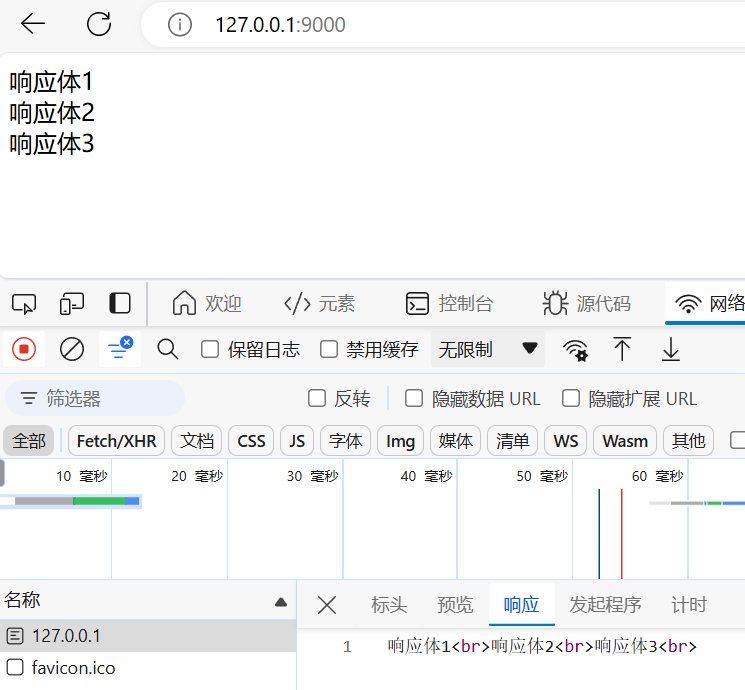
等效于:
const server = http.createServer((request, response) => {
response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集
response.write('响应体1<br>');
response.write('响应体2<br>');
response.end('响应体3<br>');
});
//也可以写成:
const server = http.createServer((request, response) => {
response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集
response.end('响应体1<br>响应体2<br>响应体3<br>');
});
练习:搭建HTTP服务,响应一个3行4列的表格,要求表格有隔行换色效果,且点击单元格能高亮显示
思路:先创建表格的html文件,实现上述功能,然后使用fs模块读取其文件内容,最后设置响应报文
相较于直接在响应报文中写html,这样不仅在编写过程中有自动补全,而且如果想更改html中的内容,直接修改html后刷新页面即可,无需重启服务
const http = require('http');
const fs = require('fs');
const path = require('path');
const server = http.createServer((request, response) => {
const file_path = path.resolve(__dirname, 'table.html'); //html文件绝对路径
const content = fs.readFileSync(file_path); //读取内容
response.setHeader('content-type', 'text/html;charset=utf-8'); //设置字符集
response.end(content); //写入
});
server.listen(9000, () => {
console.log("服务已经启动");
});
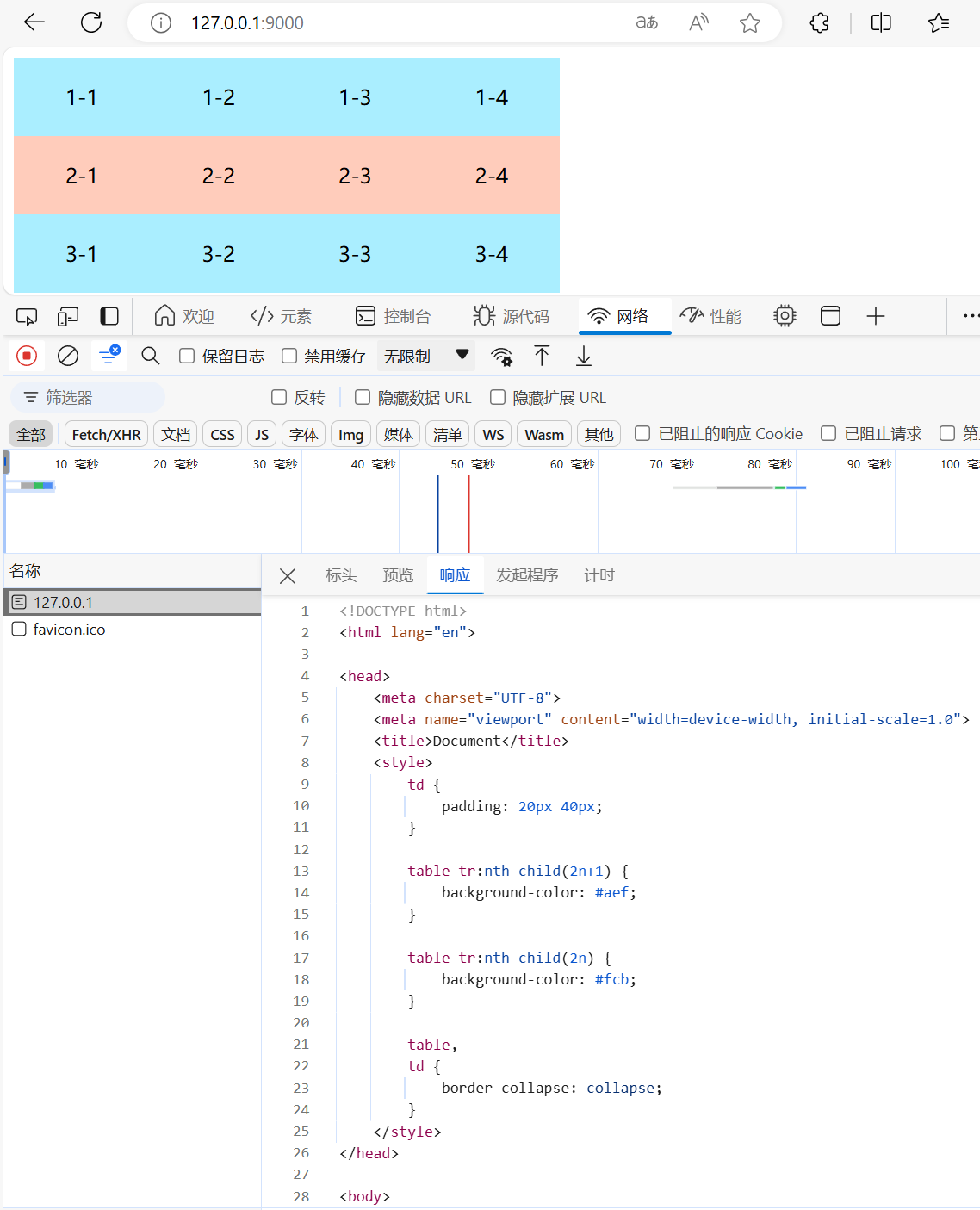
注:因为write和end方法可以接收buffer作为参数,无需手动toString转换
网页资源加载
网页资源加载的基本过程:假设有一个HTML文件,它引入了一个CSS文件和一个JS文件,HTML文件中还有一张图片。现在要把它们作为响应报文发送到网页上,服务器先响应HTML文件,网页对其进行解析
-
当读到
<title>时,网页的标题被更改 -
当读到
<link rel="stylesheet" href="index.css">时,网页向服务端发送请求,请求CSS文件,服务端将CSS文件响应给网页 -
当读到
<img src="pic.png">时网页向服务端发送请求,请求pic.png图片,服务端将图片响应给网页 -
当读到
<script src="index.js">时网页向服务端发送请求,请求JS文件,服务端将JS文件响应给网页
总结:这种复杂的页面,不是一次响应全部内容,而是不断的请求–响应,且这一过程是异步的,不用等上一个请求被响应后再发送下一个请求
实现方法:由于每次请求都触发createServer的回调函数,就需要在回调函数中添加条件判断,根据请求路径来响应指定的文件
-
对于第一次请求(打开页面/刷新页面)时,它的请求路径为
/,此时需要返回HTML文件 -
对于CSS文件请求,它的请求路径为
/xxx.css,此时需要返回CSS文件 -
依次类推,根据实际的请求路径来编写判断条件
例:对上一节中的表格响应进行拓展——将HTML/CSS/JS分别独立为一个文件
const http = require('http');
const fs = require('fs');
const path = require('path');
const server = http.createServer((request, response) => {
let { pathname } = new URL(request.url, 'http://1.1.1.1'); //获取请求路径
if (pathname === '/') {
let html = fs.readFileSync(path.resolve(__dirname, "table.html"));
response.end(html);
} else if (pathname === '/table.css') {
let css = fs.readFileSync(path.resolve(__dirname, "table.css"));
response.end(css);
} else if (pathname === '/table.js') {
let js = fs.readFileSync(path.resolve(__dirname, "table.js"));
response.end(js);
} else {
response.statusCode = 404;
response.end("<h1>404 NOT FOUND</h1>");
}
});
server.listen(9000, () => {
console.log("服务已经启动");
});
改进:直接将文件路径进行拼接,无需ifelse
const http = require('http');
const fs = require('fs');
const server = http.createServer((request, response) => {
const { pathname } = new URL(request.url, 'http://1.1.1.1'); //获取请求路径
const file_path = __dirname + pathname; //请求的文件路径
fs.readFile(file_path, (err, data) => { //同步读取
if (err) {
response.statusCode = 500;
response.end("文件读取失败");
return;
}
response.end(data);
})
});
server.listen(9000, () => {
console.log("服务已经启动");
});
输入http://127.0.0.1:9000/table.html即可访问
静态资源服务
静态资源:内容长时间不发生改变的资源,如图片、视频、CSS、JS、HTML、字体文件等。注意:这里的“不发生改变”指的是项目上线运行后不变,而不是开发阶段不变
动态资源:内容经常更新的资源,如网站首页、搜索列表等,这些内容根据时间、用户的输入等条件改变而变化
网站根目录/静态资源目录:HTTP服务在哪个文件夹中寻找静态资源。在编写服务端程序时,这个根目录可以进行自行指定(其实就是根据请求路径拼接文件路径),比如指定根目录为page文件夹:
...
const { pathname } = new URL(request.url, 'http://1.1.1.1'); //获取请求路径
const root = __dirname + '/page'; //根目录路径
const file_path = root + pathname; //请求的文件路径
...
补充:网页url
主要分为相对路径和绝对路径
绝对路径:可靠性强、易理解、使用较多
| 形式 | 特点 |
|---|---|
http://xxx.com/web |
直接向目标资源发送请求,通常用于网站的外部链接 |
//xxx.com/web |
省略协议,需拼接后发送请求,大型网站使用较多 |
/web |
省略协议、主机名、端口号,需拼接后发送请求,中小型网站使用较多 |
<a href="https://www.baidu.com">百度</a>
<a href="//jd.com">京东</a>
<a href="/search">搜索</a>
点击这三个链接后:
-
https://www.baidu.com直接跳转到该网址 -
//jd.com会自动补上当前网页的协议(这里是http)后跳转一个问题:正常应该跳转到
http://jd.com/,但实际显示的是https://www.jd.com/这时因为请求向
http://jd.com/发送后,它返回了一个301重定向状态,告诉浏览器这个网址没有资源,应向https://www.jd.com/获取
-
/search会自动补上当前网页的协议、主机名、端口号,跳转到http://127.0.0.1:9000/search
为什么这种方式使用较多:如果主机名更换,但只要路径不变,就无需更改a标签
相对路径:在发送请求时,需要与当前页面url进行计算,得到完整url后再发送请求
例如当前url为http://xxx.com/course/h5.html,则当前所在“文件夹”为http://xxx.com/course
| 形式 | 最终url |
|---|---|
./css/app.css |
http://xxx.com/course/css/app.css |
css/app.css |
http://xxx.com/course/css/app.css |
../img/logo.png |
http://xxx.com/img/logo.png |
前两种(./或省略不写)都是在当前文件夹下取文件,../是上一级目录。注意:如果已经在网页路径的最外层http://xxx.com,即使再../也不会跳出当前路径,比如上例中../../img/logo.png仍表示http://xxx.com/img/logo.png
相对路径在学习阶段使用较多,但在实际开发项目中不常用。这是因为相对路径依赖于当前页面url,不可靠,如果页面url不正常时,获取资源会出问题
页面中使用url的场景:a/link/script/img/video/audio标签、form标签中的action、AJAX请求的url
mime类型
媒体类型(Multipurpose Internet Mail Extensions/MIME):用于表示文档、文件或字节流的性质和格式
结构:[type]/[subType]即主类型/子类型
| 文件格式 | MIME类型 |
|---|---|
| html | text/html |
| css | text/css |
| js | text/javascript |
| png | image/png |
| jpg | image/jpeg |
| gif | image/gif |
| mp4 | video/mp4 |
| mp3 | audio/mpeg |
| json | application/json |
服务端可以设置响应体Content-Type表明响应体的MIME类型,浏览器据此决定如何处理响应内容
对于未知的资源类型,可以设置MIME类型为”application/octet-stream”,浏览器遇到该种响应时,会对其独立存储,也就是下载的效果
现在我们可以完善设置响应报文中的例子了:根据请求文件的后缀名设置Content-Type,并响应对应文件。这样可以让浏览器对不同文件进行不同处理,使响应的css/js生效
文件目录:
可以看到根目录为page文件夹
const http = require('http');
const fs = require('fs');
const path = require('path');
const mimes = { //一个字典,键是后缀,值是对应的mime
html: 'text/html',
css: 'text/css',
js: 'text/javascript',
png: 'image/png',
jpg: 'image/jpeg',
gif: 'image/gif',
mp4: 'video/mp4',
mp3: 'audio/mpeg',
json: 'application/json'
};
const server = http.createServer((request, response) => {
if (request.method !== 'GET') { //请求类型错误
request.statusCode = 405;
response.end('<h1>405 Method Not Allowed</h1>');
return;
}
const { pathname } = new URL(request.url, 'http://1.1.1.1'); //获取请求路径
const root = __dirname + '/page'; //网页根目录
const file_path = root + pathname; //请求的文件路径
fs.readFile(file_path, (err, data) => {
if (err) {
response.setHeader('content-type', 'text/html;charset=utf-8');
switch (err.code) { //错误类型判断
case "ENOENT":
response.statusCode = 404;
response.end('<h1>404 Not Found</h1>');
break;
case "EPERM":
response.statusCode = 403;
response.end('<h1>403 Forbidden</h1>');
break;
default:
response.statusCode = 500;
response.end('<h1>Internal Server Error</h1>');
break;
}
return;
}
const ext = path.extname(file_path).slice(1); //后缀名(去掉前面的.)
const mime = mimes[ext]; //获取对应的mime
if (mime) { //获取到了mime
if (ext === 'html') { //如果是HTML,加上charset
response.setHeader('content-type', mime + ';charset=utf-8');
} else { //其它格式不用加
response.setHeader('content-type', mime);
}
} else { //没获取到,设为application/octet-stream
response.setHeader('content-type', 'application/octet-stream');
}
response.end(data);
})
});
server.listen(9000, () => {
console.log("服务已经启动");
});
中文乱码问题:在Content-Type的mime后加上charset=utf-8
为什么HTML页面不加charset=utf-8也不乱码:因为HTML的head中设置了<meta charset="UTF-8">。这两种方式中,响应头Content-Type的设置优先级更高
在实际应用中,除了HTML,其它格式的响应都无需加charset=utf-8,因为浏览器会根据页面的字符集对这些文件进行解析,即使我们在网页中打开这些文件看到乱码,也不影响浏览器实际解析这些文件
完善错误处理:
-
如果请求方式不是GET,返回405状态码
-
根据
err对象中code属性值-
‘ENOENT’:资源不存在,此时应返回404状态码
-
‘EPERM’:不允许操作,响应的文件禁止访问(权限不够),此时应返回403状态码
-
错误的验证方式:
-
请求方式不是GET:使用表单——另建一个HTML文件
<form action="http://127.0.0.1:9000/table.html" method="post"> <input type="text" name="xxx"> <input type="submit" value="submit"> </form> -
资源不存在:输入错误的路径
-
不允许操作:更改文件读取权限(右键文件->属性->安全->编辑->读取和执行)
GET和POST请求
GET请求:
-
在地址栏直接输入网址访问
-
点击a链接跳转
-
link标签引入CSS
-
script标签引入JS
-
video和audio标签引入多媒体文件
-
img标签引入图片
-
form表单默认提交方法
-
Ajax中的get请求
POST请求:
-
form表单指定提交方式为post
-
Ajax中的post请求
区别:
-
作用:GET主要用于获取数据,POST主要用于提交数据
-
参数位置:GET的带参数请求是将参数放到url后,POST是将参数放到请求体中
-
安全性:POST相对安全一些,因为浏览器中参数会暴露在地址栏中。当然如果使用抓包的方式,仍可获取POST请求的参数
-
请求大小:GET请求大小有限制(一般为2K),POST无限制