使用我的GSE157827数据进行初步分析-6
other-other2026.4.8-2026.4.22研究进展
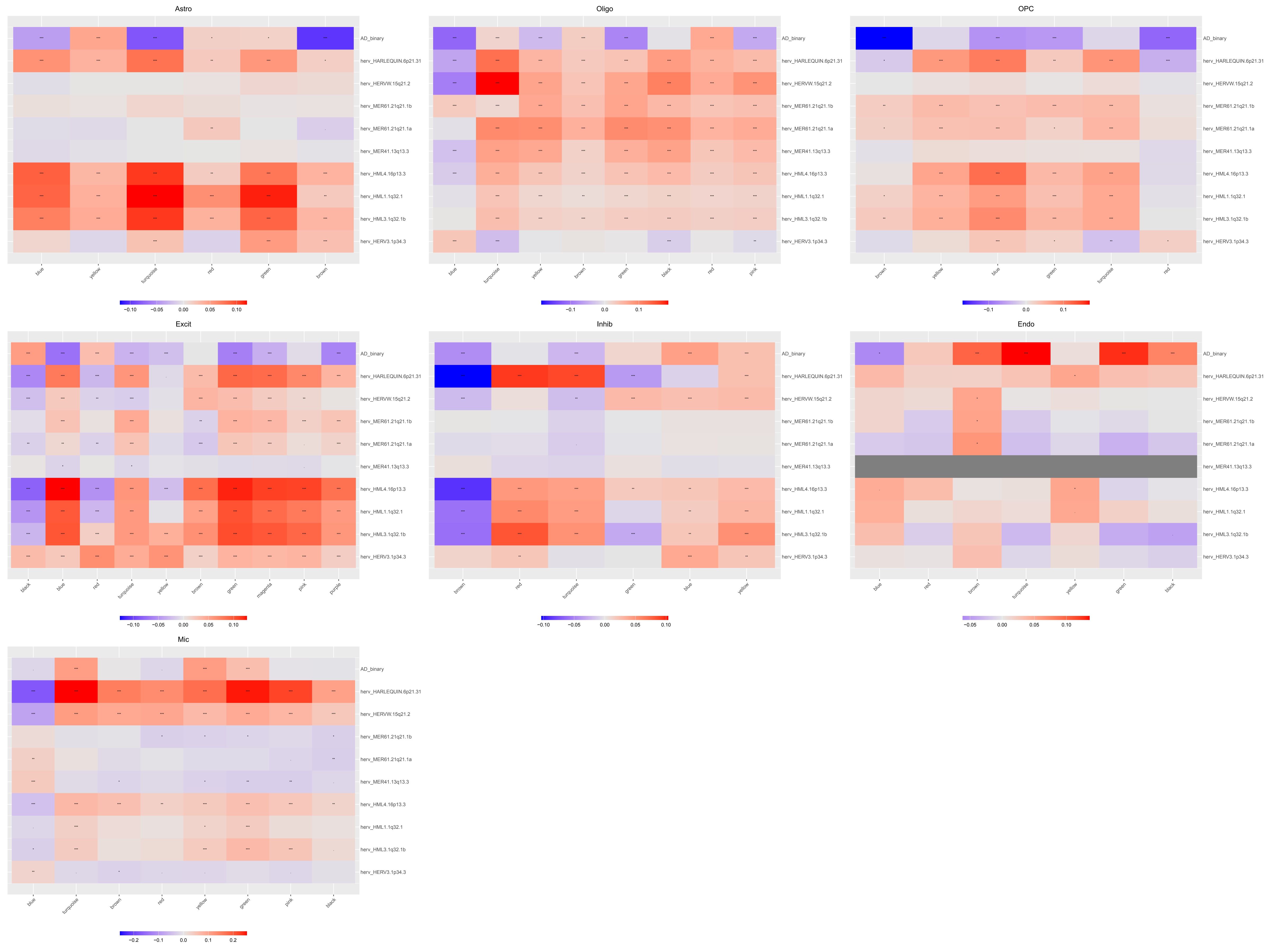
位点级分析
选表达高hERV位点(比如前10%),用MAST做差异表达分析,看哪些既表达量高又AD-NC差异大,将这些位点做共表达网络看相关性(就用之前得到的基因网络,跑一下ModuleTraitCorrelation)
位点的差异表达分析
设置表达比例阈值为1%(防止单个细胞拉高平均值),其它不设限:结果预览
表达量又高又在AD和NC中有差异的似乎不太多,而且都是下调
几个比较显著的:
- excit/inhib神经元内:HERV3-1p34.3这个位点logFC很大,细胞比例也是AD更多
- 多个细胞类型一致下调、效应量不小:
- HML3-1q32.1b
- HML1-1q32.1
- HML4-16p13.3
- Oligo内特异下调的位点比较多,不是零散几个位点变化,而是一组位点整体偏低,更像是一个系统性状态改变
- Mic和Inhib有一个上调的HARLEQUIN-6p21.31,而且它在所有细胞水平也上调,像是一个跨细胞类型但偏向非少突的上调位点
target_herv_locus <- c("HERV3-1p34.3", "HML3-1q32.1b", "HML1-1q32.1", "HML4-16p13.3", "MER41-13q13.3", "MER61-21q21.1a", "MER61-21q21.1b", "HERVW-15q21.2", "HARLEQUIN-6p21.31")
gene网络相关性(WGCNA)
- HML4-16p13.3/HML1-1q32.1/HML3-1q32.1b这3个位点经常一起动:在DE中,这几个位点本来就是跨多个细胞类型重复出现的;现在到了ModuleTraitCorrelation里,它们又在模块层面呈现相似相关模式
- HARLEQUIN-6p21.31:在Mic中特别突出
位点级hERV trait与gene module的关联显示,位点级hERV与gene network的关联明显细胞类型特异;不同hERV位点并非简单重复AD/NC差异,而是对应若干跨细胞类型共享或细胞类型特异的转录状态轴;其中HML4/HML1/HML3构成较稳定的共享位点程序,而HARLEQUIN-6p21.31在Mic等细胞中表现出更突出的状态关联
在与hERV位点相关性较大的模块中选hub gene,然后算样本水平上的位点~gene相关性,确定“该module里哪些具体基因和这个位点关系最稳定”
- 每个“细胞类型-位点”保留相关性绝对值最大的前2个module
- 提取这些module的hub gene
- 在对应celltype内、对应module里,找与该位点最相关的具体基因
- 找“既是hub gene,又和该位点显著相关”的交集基因,作为后面样本级相关性的输入
具体的基因相关性(线性拟合)
主要思路:
- 选一些关注的基因通路TLR2/STAT1等,将其作为一个基因集看整体表达量与hERV的关系,在细胞类型和亚群层面都试一试
- 之前在相关论文中看到说hERVK与TLR8表达相关,想看看我这里是不是也是这个情况,如果能得到类似的结果,就试一试位点级的分析(毕竟开题时候提的就是位点级分析)
herv_family_assay <- "HERV_family"
target_herv_family <- c("HERVK-int", "HERVK3-int", "HERVK9-int", "HERVK11-int", "HERVK13-int", "HERVK14-int", "HERVK22-int")
mic_gene_panel <- list(
innate_immune = c("TYROBP", "CD74", "HLA-DRA"),
inflammation_signal = c("TLR2", "MAP3K8", "EPSTI1"),
stress_immune = c("HSP90AA1", "HSPH1", "DNAJB1"),
homeostatic_microglia = c("P2RY12", "CX3CR1", "TMEM119"),
# IFN_STAT1 = c("STAT1", "ISG15", "IFIT3"),
IFN_STAT1 = c("STAT1"),
TLR8 = c("TLR8")
)
mic_res <- lapply(names(mic_gene_panel), function(sig) {
run_herv_geneset_coexpr_one_celltype(
seu_ct = mic,
herv_assay = herv_family_assay,
herv_features = target_herv_family,
gene_features = mic_gene_panel[[sig]],
agg = "mean"
) %>%
mutate(signature = sig, .before = 1)
}) %>% bind_rows()
write.csv(mic_res, file = file.path(res_dir, paste0("mic_geneset_hERV_family_corr.csv")))
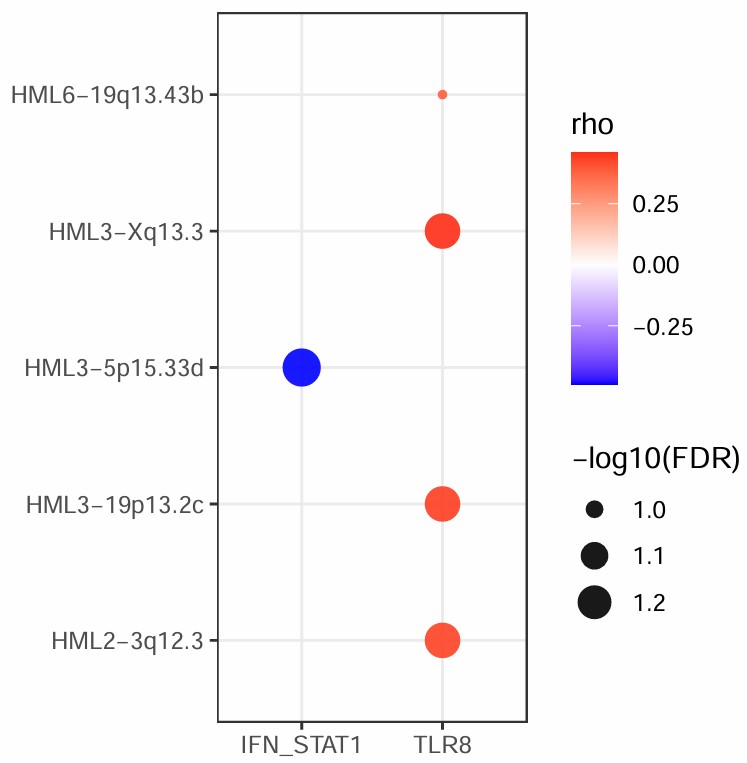
在所有Mic细胞中,只有IFN_STAT1和TLR8表现出了较大的相关性,其它的相关性都在0.1以下:结果预览
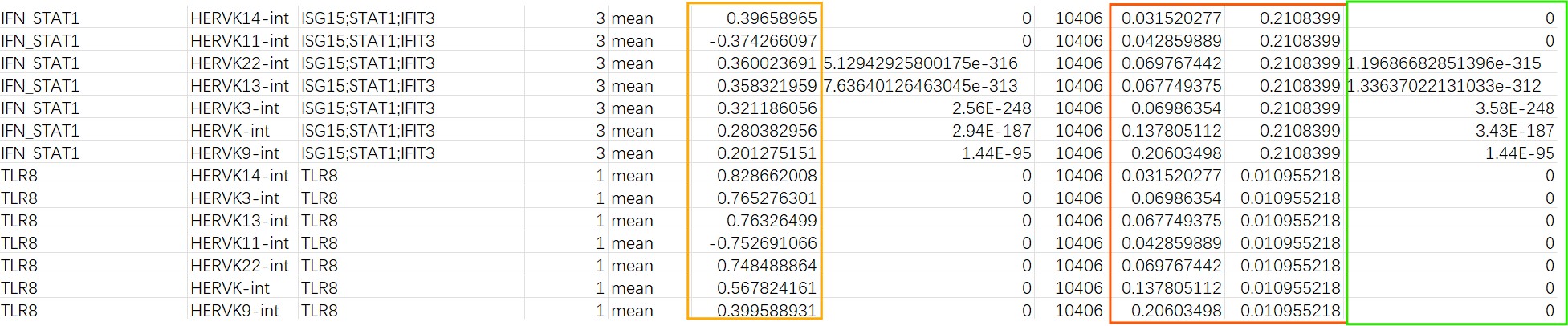
- 橙色是相关性,红色是hERV和基因集的表达比例(一组基因中有一个有表达就算),绿色是p_adj
看一看这些hERV家族和基因在AD/NC中是否差异表达
Idents(mic) <- "group"
res_gene <- FindMarkers(
mic,
ident.1 = "AD",
ident.2 = "NC",
test.use = "MAST",
assay = "RNA",
features = c(mic_gene_panel[["IFN_STAT1"]], mic_gene_panel[["TLR8"]]),
min.pct = 0,
logfc.threshold = 0
)
res_herv <- FindMarkers(
mic,
ident.1 = "AD",
ident.2 = "NC",
test.use = "MAST",
assay = herv_family_assay,
features = target_herv_family,
min.pct = 0,
logfc.threshold = 0
)
Mic:
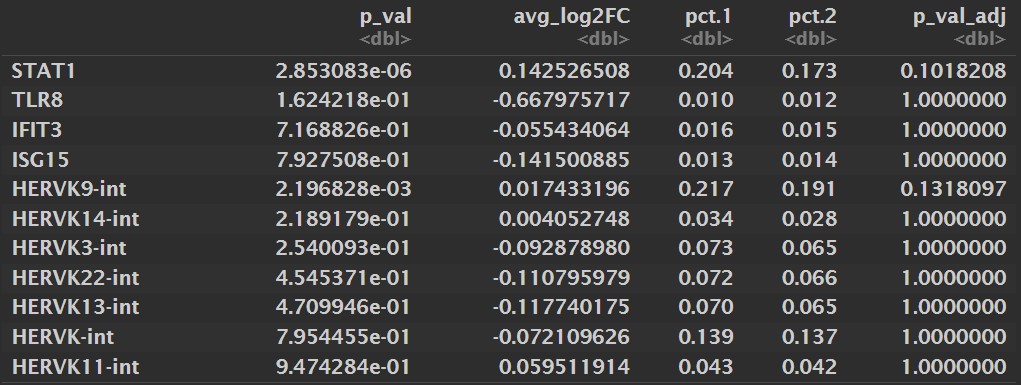
- 似乎只有STAT1的表达比例高一点,其它都是1%左右,感觉可以只对STAT1来分析
- 少量TLR8阳性细胞贡献了大部分相关性(TLR8阳性细胞刚好和某些HERVK家族的阳性细胞高度重叠,于是Spearman rho会很高)
- 差异表达分析中TLR8和其它基因在AD中都下调,是否与相关性结果矛盾?差异表达解释“AD组整体平均表达是否比NC更高”,而相关分析解释“某个hERV高的细胞,是否也更倾向于IFN/STAT1或TLR8高”
- 总体来说STAT1的结果比较显著,但无论是哪一种,都没法把AD和hERV联系起来,只能说HERVK与STAT1有中等强度相关,但没法说HERVK/STAT1与AD相关
看看UMAP图:高表达的细胞是否均匀分布
calc_gene_set_score <- function(seu_ct, gene_features, agg = c("mean", "sum")) {
gene_use <- intersect(rownames(seu_ct[["RNA"]]), gene_features)
rna_mat <- GetAssayData(seu_ct, assay = "RNA", slot = "data")[gene_use, , drop = FALSE]
if (agg == "mean") {
score <- Matrix::colMeans(rna_mat)
} else {
score <- Matrix::colSums(rna_mat)
}
score
}
mic$IFN_STAT1_score <- calc_gene_set_score(mic, mic_gene_panel[["IFN_STAT1"]], agg = "mean")
mic$TLR8_score <- calc_gene_set_score(mic, mic_gene_panel[["TLR8"]], agg = "mean")
FeaturePlot(mic, features = "IFN_STAT1_score", reduction = "umap")
FeaturePlot(mic, features = "TLR8_score", reduction = "umap")
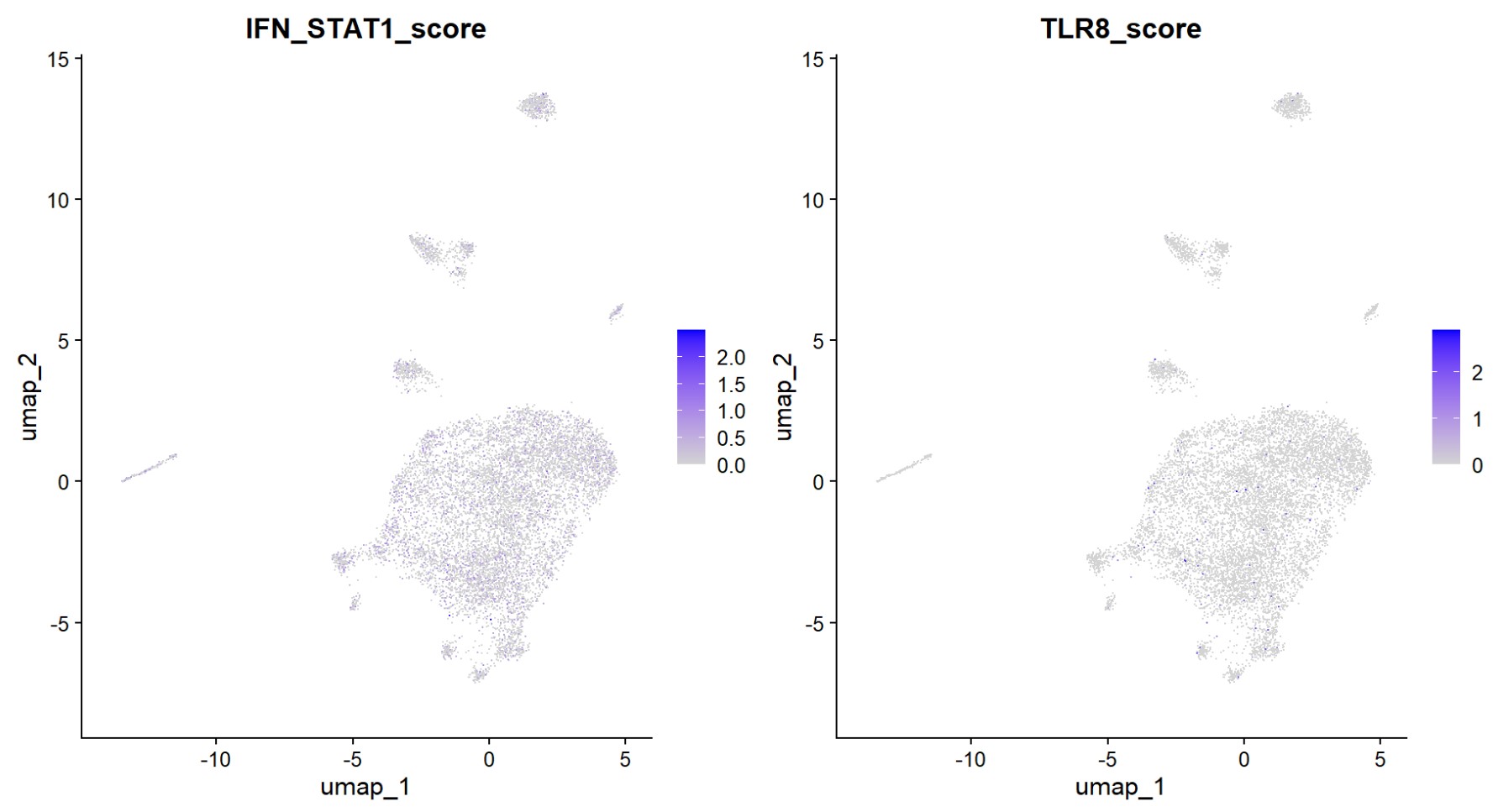
- 两者至少在UMAP图上分布没有特别集中
- TLR8在UMAP图上很稀疏,而且有颜色点的值很高,相比之下STAT1看起来就均匀一些
散点+线性拟合组合图
plot_herv_vs_gene_combo <- function(seu_ct, herv_assay = "HERV_family", pairs) {
meta <- seu_ct@meta.data %>%
mutate(log10_nCount_RNA = log10(nCount_RNA + 1))
herv_mat <- GetAssayData(seu_ct, assay = herv_assay, slot = "data")
rna_mat <- GetAssayData(seu_ct, assay = "RNA", slot = "data")
p_list <- lapply(seq_len(nrow(pairs)), function(i) {
gene_i <- pairs$gene[i]
herv_i <- pairs$subfamily[i]
y_raw <- seu_ct@meta.data[[gene_i]]
x_raw <- as.numeric(herv_mat[herv_i, ])
x <- residualize_vec(x_raw, meta)
y <- residualize_vec(y_raw, meta)
df_plot <- data.frame(herv = x, gene = y)
ct_res <- suppressWarnings(cor.test(df_plot$herv, df_plot$gene, method = "spearman", exact = FALSE))
rho_txt <- round(unname(ct_res$estimate), 3)
p_txt <- signif(ct_res$p.value, 3)
ggplot(df_plot, aes(x = herv, y = gene)) +
geom_point(size = 0.3, alpha = 0.35) +
geom_smooth(method = "lm", se = FALSE, color = "red", linewidth = 0.6) +
theme_bw() +
labs(
title = paste0(gene_i, " ~ ", herv_i),
subtitle = paste0("rho=", rho_txt, ", p=", p_txt),
x = herv_i,
y = gene_i
)
})
wrap_plots(p_list, ncol = 2)
}
plot_herv_vs_gene_combo(
mic, "HERV_family",
pairs = data.frame(
gene = c("TLR8_score", "TLR8_score", "TLR8_score", "TLR8_score"),
subfamily = c("HERVK14-int", "HERVK3-int", "HERVK-int", "HERVK11-int")
)
)
plot_herv_vs_gene_combo(
mic, "HERV_family",
pairs = data.frame(
gene = c("IFN_STAT1_score", "IFN_STAT1_score", "IFN_STAT1_score", "IFN_STAT1_score"),
subfamily = c("HERVK14-int", "HERVK-int", "HERVK9-int", "HERVK11-int")
)
)
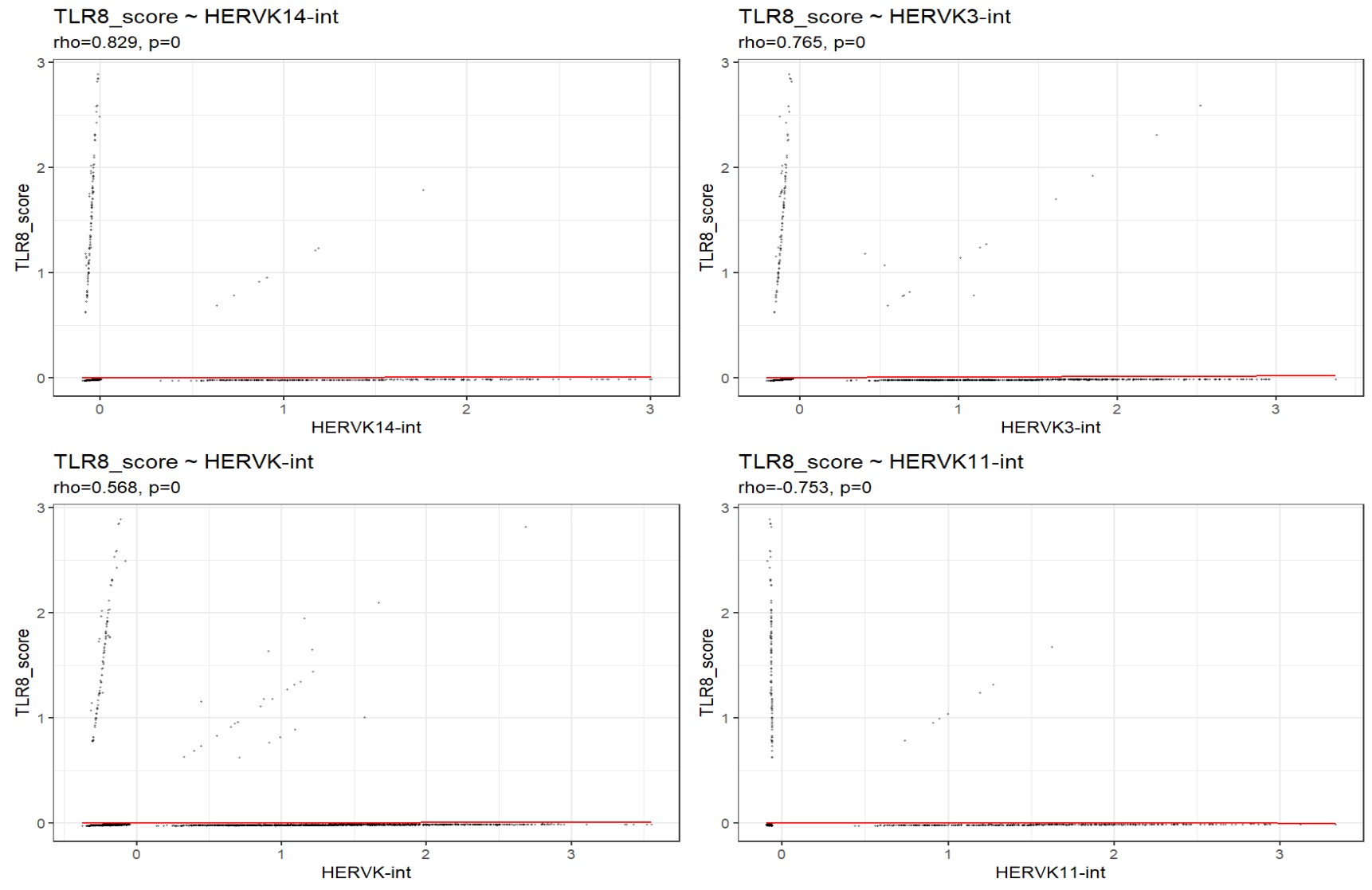
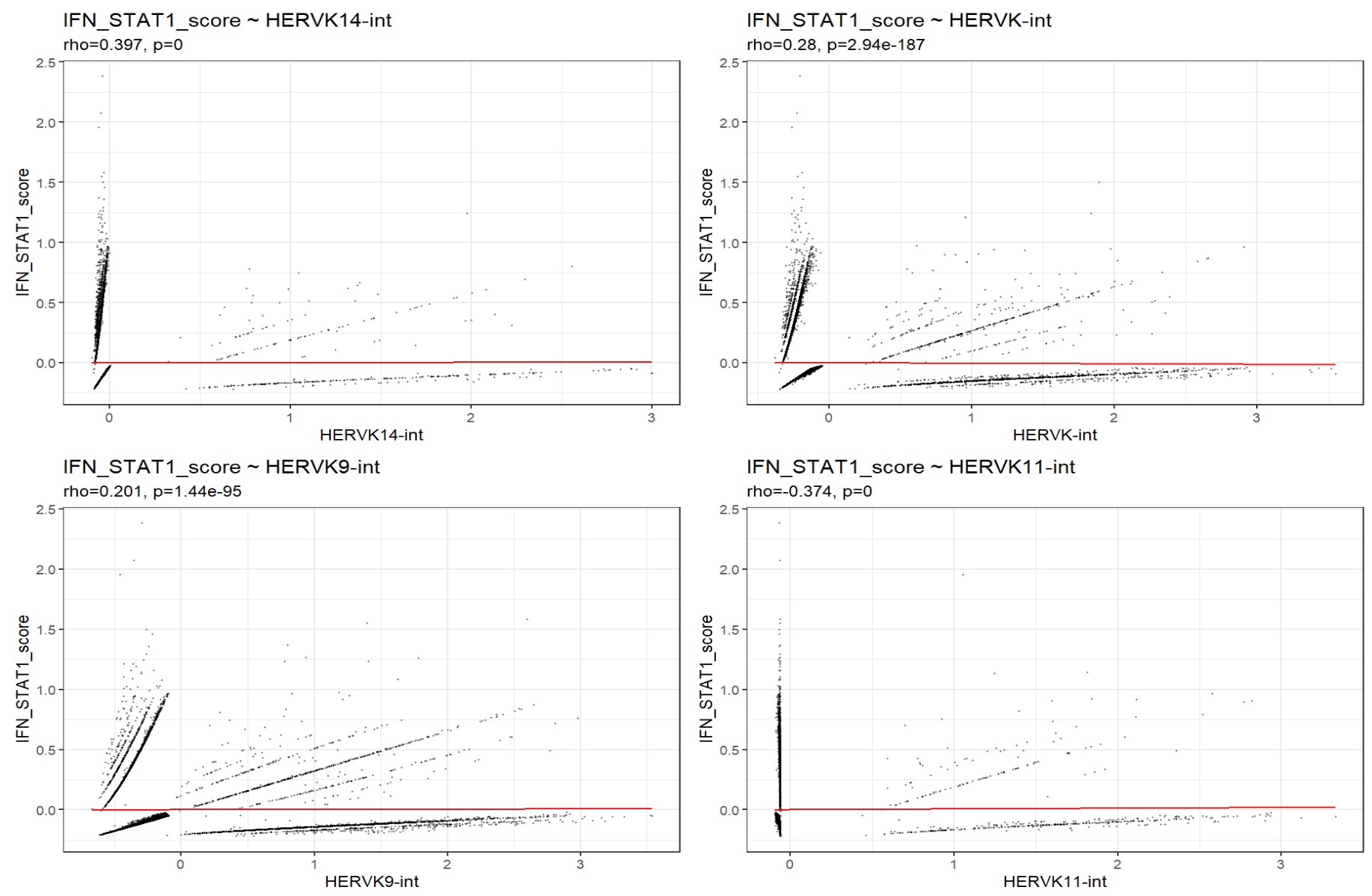
- 红线是可视化用的lm线,不是根据rho值画的,Spearman相关应该比lm有意义
- 结论byGPT:
- 在microglia中,由ISG15/STAT1/IFIT3构成的IFN/STAT1样得分与多个HERVK家族呈中等强度相关,其中HERVK14-int、HERVK-int、HERVK9-int为正相关,而HERVK11-int为负相关,提示不同HERVK家族可能对应不同的免疫相关细胞状态
- TLR8与若干HERVK家族呈现极强相关,但由于TLR8表达极为稀疏且主要集中于少数细胞,该结果更可能反映一个稀有TLR8阳性microglia亚群与特定HERVK家族的共现,而不一定代表整个microglia群体中的连续共表达轴
关于STAT1和TLR8在AD中的重调:
- STAT1:hTau积累可激活JAK2/STAT1通路,促进STAT1磷酸化、二聚化和核转位;human microglial state dynamics研究把STAT1列为AD相关微胶质状态的候选调控因子之一,是某些炎症/IFN样微胶质状态中的上调因子,而不是一定会在所有AD样本、所有细胞里都显著升高
- STAT1可能只在少数微胶质状态里升高
- 它的活化可能比它的mRNA平均值更明显
- TLR8:在AD temporal cortex里,HERV-K和TLR8都上调,且TLR8是和HERV-K相关性最高的TLR,位点级的那个分析只说一部分HERV-K loci和TLR8相关,且family-level的HERV-K总和并不显著相关,也许不同脑区会导致结果的差异?
所有细胞:
mic的cluster2:
- 把范围缩小到cluster2后,相关性效应更强,且STAT1和所有目标HERVK家族都是正相关;但TLR8的表达比例还是比较低,所以结论可能不太稳定
- 如果在所有细胞层面,TLR8的rho就会翻转,说明TLR8~herv的相关性只集中于少数细胞中。这与之前DE时看到的AD/NC的TLR8和STAT1表达量差异不显著对应,说明在Mic内部某个特殊亚群/状态中,hERV和免疫基因一起变化
位点-样本级相关性分析:
- 筛选出HERVK几个主要家族的位点,将各位点按表达比例排序,选表达较多的位点
- 模仿论文中的方法,进行样本级分析,但不知道40个样本够不够,如果不够就细胞级
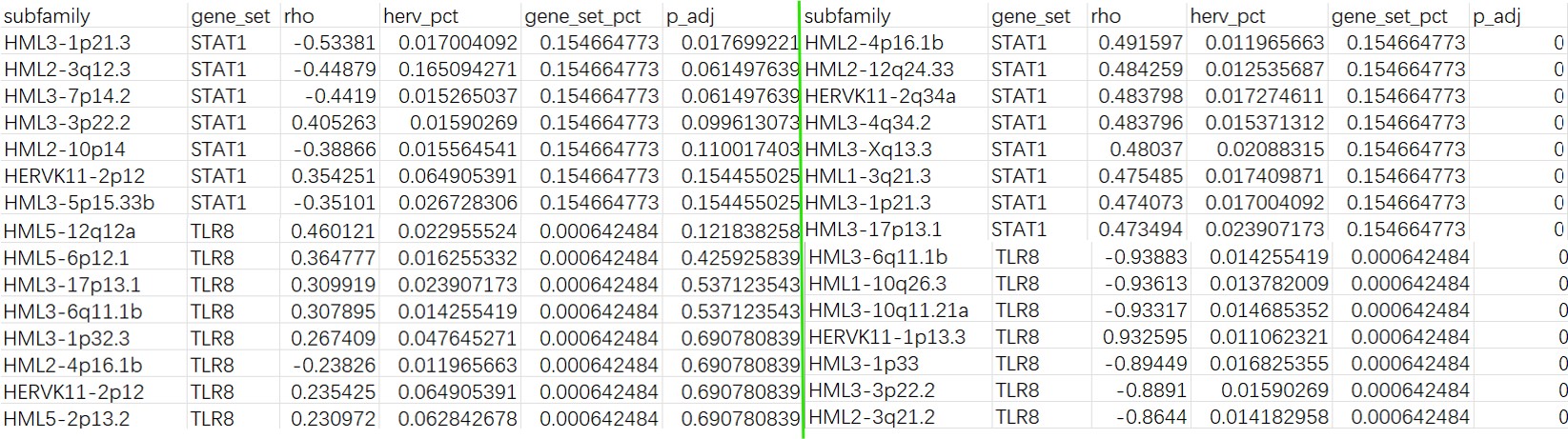
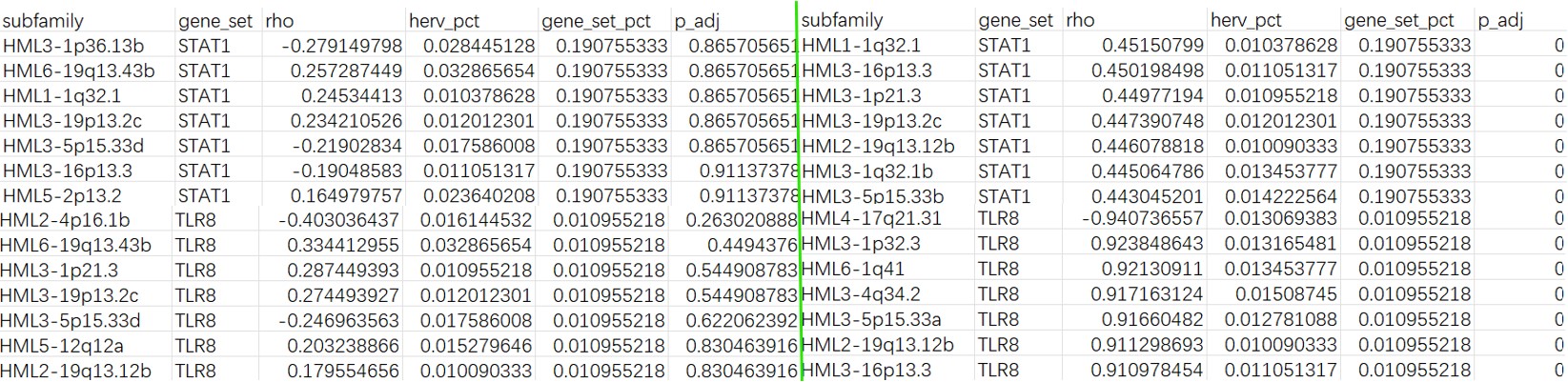
结果:左面为样本级,右面为细胞级
-
所有细胞:
-
Mic:
-
Mic cluster2:
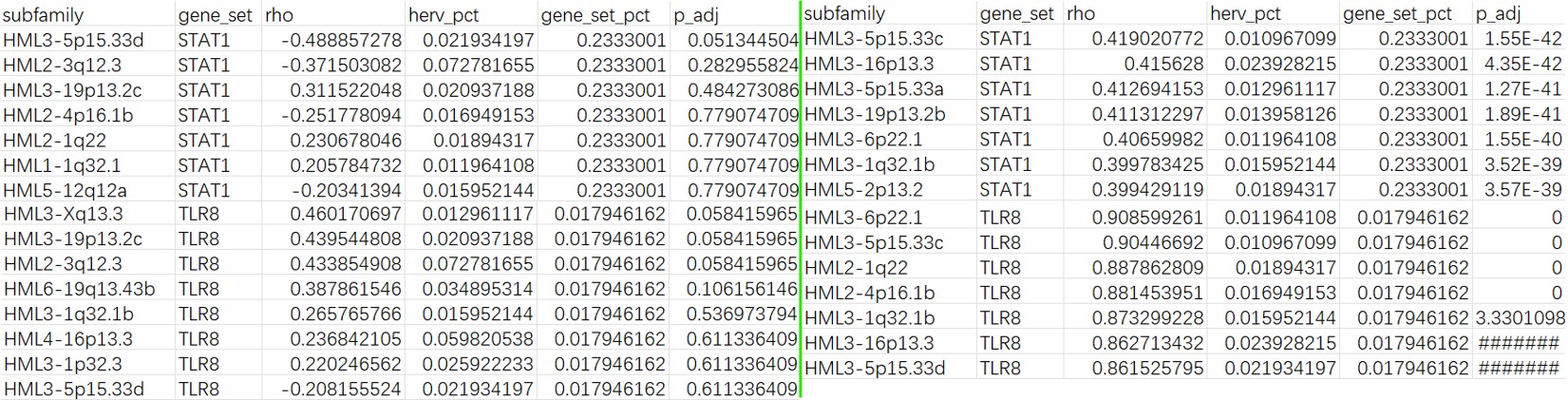
总体来说,Mic cluster2的结果比Mic和全体细胞更显著,样本级别的分析中显著的结果较少,符合之前样本级DE的结果趋势。
- 为什么把研究对象缩小到Mic cluster2才有较显著的结果:不是所有细胞都在统一地发生这种关系,可能只有某个更特定的亚群才有这个现象
- 相对于STAT1,TLR8在位点级上的相关性更显著,虽然它们的FDR没有正式<0.05,但有几个位点已经非常接近,这符合论文中“HERV-K family总和不显著,但部分loci与TLR8显著/接近显著相关”的结论
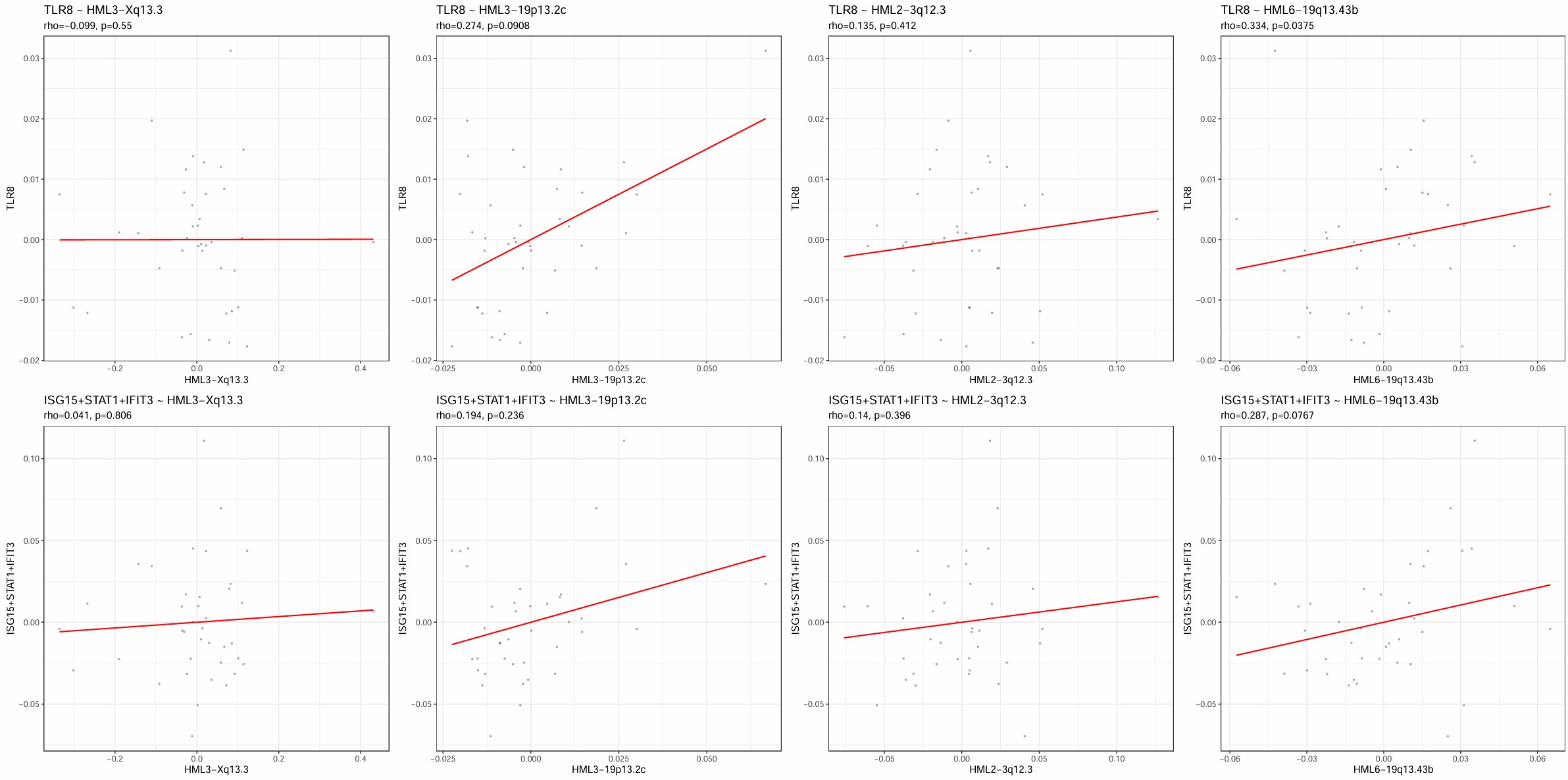
在选取最终的画图位点时,我同时计算了细胞水平和样本水平的herv~gene相关性,除了根据相关性和p值,我还考虑了细胞水平和样本水平的相关性方向是不是相同,比如有点位点在细胞水平是负相关、样本水平正相关,这种我就排除掉了。最后看了下Mic的cluster2中几个位点与TLR8的相关性,感觉位点级别可能效应比较小,可能还是家族级的比较好解释,所以位点这边就没用
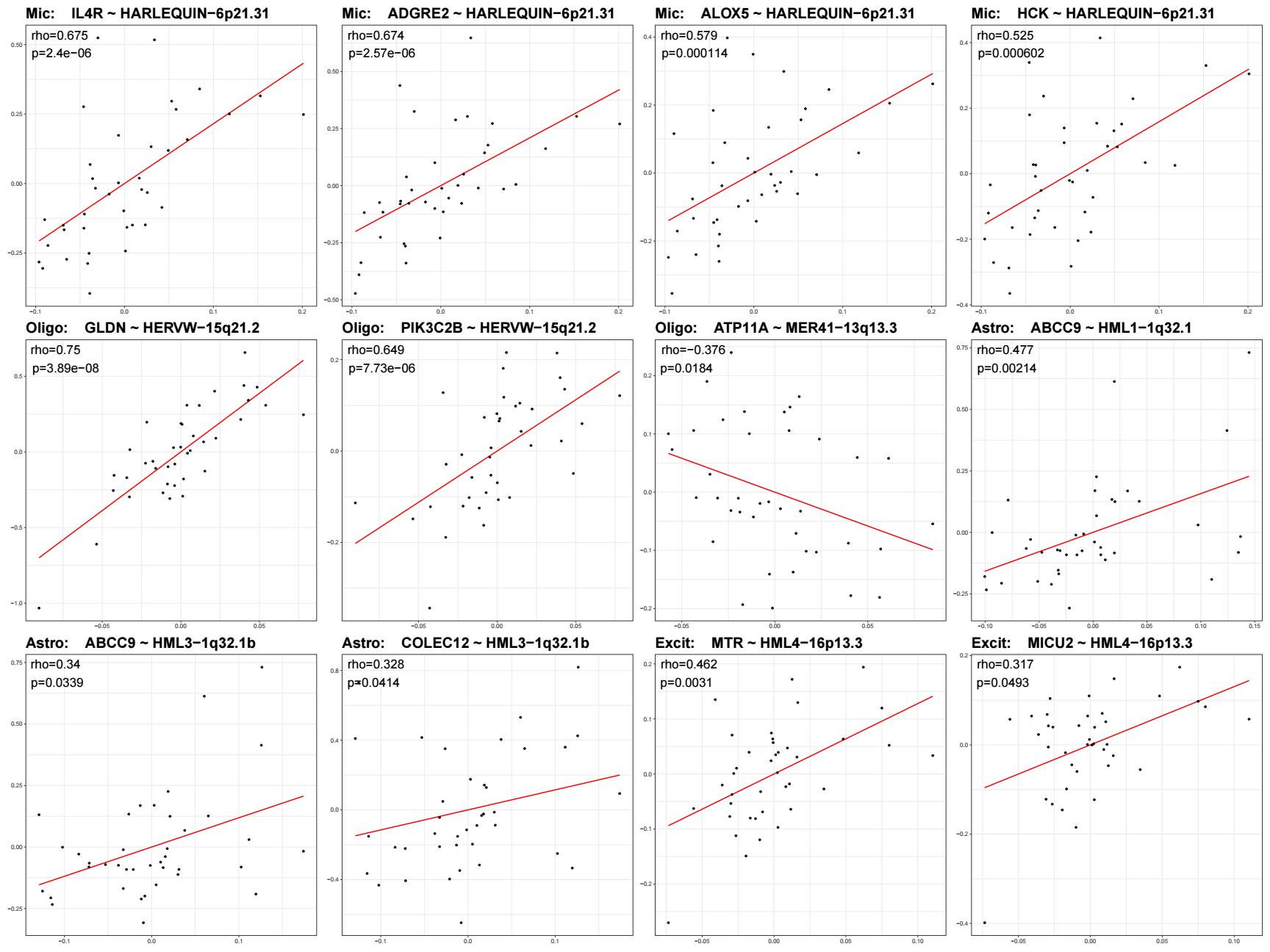
- 在mic中,HARLEQUIN-6p21.31与IL4R、ADGRE2、ALOX5和HCK等免疫相关基因呈稳定正相关,说明该位点更可能标记一条microglial免疫活化状态轴负相关
- 在oligo中,HERVW-15q21.2与GLDN及PIK3C2B呈正相关,提示该位点与少突细胞特定状态/结构程序相关;MER41-13q13.3与参与膜脂翻转和膜稳态维持的ATP11A呈负相关,提示Oligo中还存在一条与膜状态调节相关的反向位点-gene轴
- 在astro中,HML1-1q32.1和HML3-1q32.1b分别与ABCC9和COLEC12相关程序呈稳定正相关,其中ABCC9在两个位点上都得到支持,提示这两个HML位点属于同一条共享的astrocytic hERV状态轴
- 在excit中,HML4-16p13.3与MTR和MICU2呈稳定正相关,提示该位点可能关联神经元的一碳代谢及线粒体功能/钙稳态背景
- Inhib、OPC和Endo中虽可见一定cell-level位点-gene关联,但多数未在donor层面稳定复现,提示这些关联更可能反映细胞内局部异质性,而非稳健的样本级协同变化
位点级WGCNA分析显示,不同hERV位点与gene module的关联具有明显细胞类型特异性。进一步从显著module中提取key genes,并在样本层面对hERV-gene关系进行验证后发现,真正稳定的位点-gene关联主要集中于Mic、Oligo、Astro和Excit。其中特别突出的是,Mic中HARLEQUIN-6p21.31与IL4R、ADGRE2、ALOX5和HCK等免疫相关基因在cell-level与donor-level均呈一致正相关,提示该位点与microglial免疫活化程序相联系;Oligo中HERVW-15q21.2与GLDN和PIK3C2B呈正相关,提示该位点与少突细胞特定状态/结构程序相关,MER41-13q13.3与ATP11A呈负相关,提示Oligo中可能存在一条与膜状态调节相关的反向轴;Astro中HML1-1q32.1与HML3-1q32.1b共同指向ABCC9/COLEC12相关程序,支持存在共享的astrocytic hERV位点轴;Excit中则以HML4-16p13.3与MTR/MICU2的关联最为稳定,提示该位点可能关联神经元代谢及线粒体功能背景。总体来看,位点级hERV并非简单重复AD/NC差异,而是在不同细胞类型中对应若干相对独立的转录状态轴
共表达网络总结
hERV关联不是统一的,而是明显细胞类型依赖:
- Astro、Oligo、OPC、Excit的模块-hERV相关性幅度更大
- Mic相关性中等,但模块的生物学解释更明确,尤其集中在免疫/炎症相关方向
- Endo、Inhib整体较弱
AD和hERV不是简单同向变化:
- 很多模块里都能看到hERV和模块相关明显,但AD_binary相关很弱,甚至方向相反
- hERV更像是反映细胞状态轴的标志,而不是简单的AD/NC二分类标志
主线:
- Mic:在小胶质细胞中,hERV高表达状态更倾向于和广义先天免疫/炎症样激活相关,同时伴随翻译/神经互作相关程序的下降。整体上,以HERVK9/HERVL/HERVH为代表的家族与免疫相关模块的相关性最稳定
- cluster 2:AD偏多(比全部Mic中的AD比例多13%),HERVK相关家族表达较高。与hERV正相关的pink模块上调,而pink模块富集到defense response to virus/response to virus/defense response to symbiont相关,且DEG包括TLR2/MX2/MX1;与hERV负相关的blue模块下调,blue模块与learning/cognition/trans-synaptic signaling/neuron projection morphogenesis相关
- 除了pink和blue模块,在整体层面,Mic中HERVK9/HERVL/HERVH还与black模块(先天免疫/抗病原体)及yellow模块(蛋白折叠+免疫效应)相关,提示hERV-high的Mic状态不仅是炎症激活,也可能伴随抗原呈递和应激/蛋白稳态变化
支持性结果:
- Oligo:在少突胶质细胞中,不同hERV家族与少突状态的关系并不完全一致:目前最稳健的证据支持HERVK11与成熟髓鞘化/高代谢状态相关;而HERVK3更偏向结构重塑/黏附变化趋势;HERVK、HERVK3、HERV3、HERVH、HERVL等多个家族则更可能共同参与广义膜脂/信号重塑状态。需要注意的是,后两者主要来自表达模式与模块方向的一致性,其cluster-levelGO证据相对较弱
- cluster 9:最稳健、也是唯一真正显著的结果。只有HERVK11上调,其他hERV家族整体偏低,一个成熟髓鞘化、高代谢、高翻译活性的少突状态,并与HERVK11选择性相关
- cluster 3:GO结果不显著。HERVK3相关的结构重塑/黏附变化状态,对应细胞骨架、黏附及分化相关程序
- cluster 5:GO结果不显著。表现为更广泛的hERV上调,不仅包括HERVK/HERVK3,还包括HERV3/HERVH/HERVL等多个家族,因此更适合概括为一个多家族共同参与的广义hERV激活/重塑型亚群,其功能偏向脂质代谢、膜转运以及信号/修饰重塑
- Excit:提供了一个和神经胶质细胞不同的模式——在兴奋性神经元中,HERVL/HERVK9/HERVK升高更可能与突触传递程序减弱相联系;反过来,hERV较低的神经元状态保留了更强的突触传递和囊泡循环程序
- cluster 6的hERV表达量低,在red和black模块上调,而red和black的GO都是突触和信号传递相关的
- 这说明与胶质细胞中hERV更多关联于激活/重塑/炎症类状态不同,在神经元中,hERV更像和“突触功能下降”相联系
- astro:在星形胶质细胞中,hERV相关模块主要连接到gliogenesis、cell-cell signaling和synapse organization,提示其更可能反映胶质细胞参与神经支持和细胞间通讯的状态,也存在免疫/细胞因子响应方向的hERV关联,但强度和清晰度不如Mic,更像“胶质支持/分化+轻度炎症响应”的背景状态
总述:hERV重调在AD脑内具有明显的细胞类型和细胞状态依赖性。在不同细胞类型中,hERV并非统一对应同一种病理程序,而是分别耦联到不同的转录模块:在Mic中,以HERVK9/HERVL/HERVH为代表的家族主要与广义先天免疫/炎症样激活、抗原呈递样程序增强相关,并与稳态和翻译程序下降相联系;在oligo中,不同hERV家族分别对应结构重塑、广义膜脂/信号重塑以及成熟髓鞘化/高代谢状态,其中HERVK3更偏向结构重塑,HERVK/HERVK3/HERV3/HERVH/HERVL更偏向广义激活/重塑,HERVK11则更可能与成熟髓鞘化-高代谢状态选择性相关;在Astro中,HERV更多关联于胶质分化、神经支持与轻度细胞因子响应;而在Excit中,HERVL/HERVK9/HERVK升高则更可能与突触传递程序减弱相联系。除此之外,在OPC中也存在一定STAT1/外源刺激响应线索,在Inhib中与突触功能和蛋白折叠/应激有关,在Endo中与DNA合成/细胞分裂、神经和蛋白质相关功能有关,但与hERV的相关性较弱或者GO富集结果不显著,还需要更多验证
总结性的结果图选哪些
- oligo/mic作为主要分析对象:各亚群的模块分数热图+各亚群的hERV家族平均表达量热图+关键模块的hERV~module热图+关键亚群的GO分析结果
- 展示所有结果:气泡图?比如y轴是7大细胞类型,x轴是GO富集结果的功能标签,气泡大小/颜色代表相关程度(或者加上p值这种),最后再给气泡加个标签写上代表hERV家族(哪个家族和这个功能最相关)
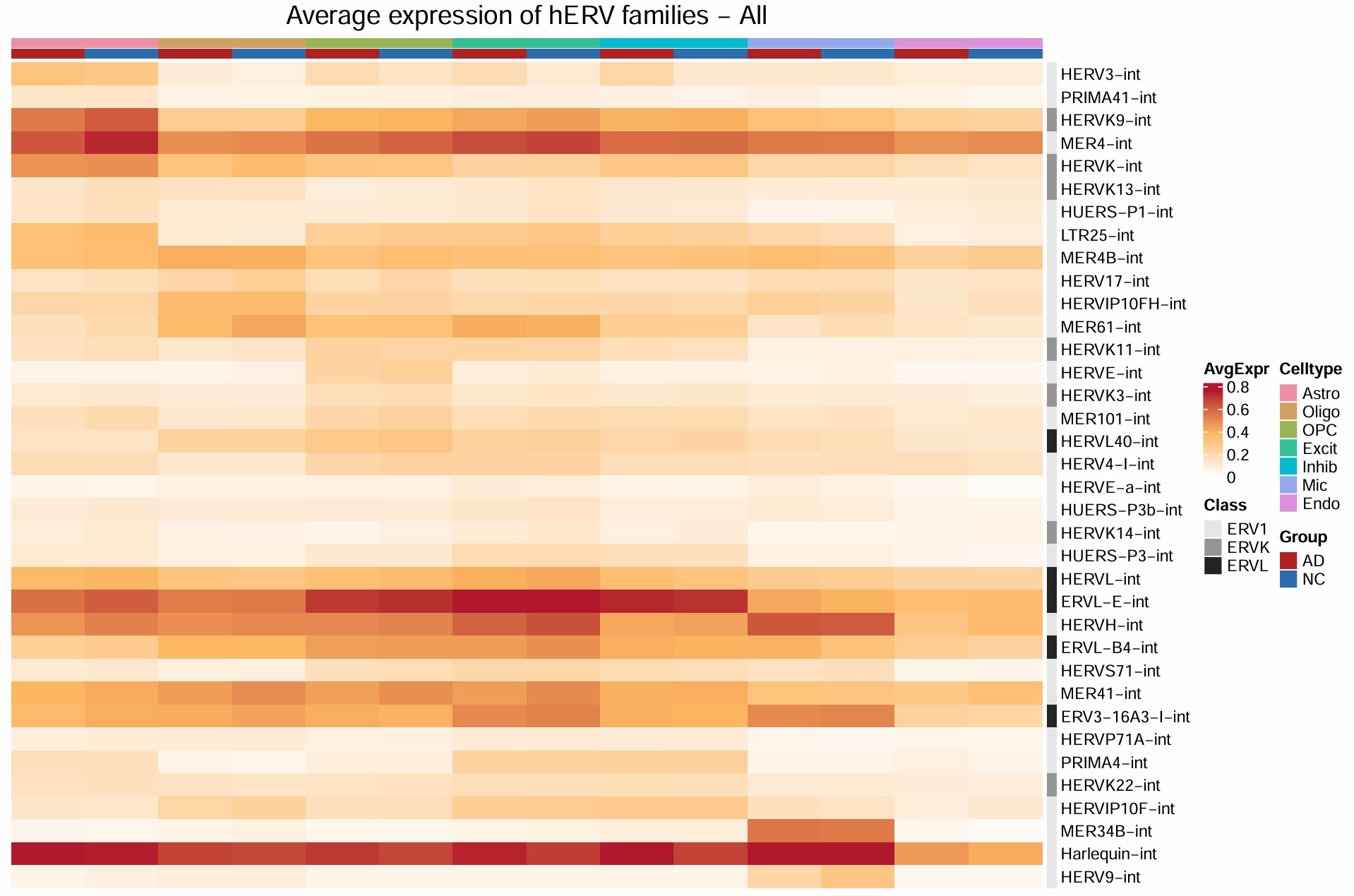
hERV表达量热图test2
原值热图:设置最大值截取(表达量大于一定值的都归为同一种颜色)
# 从 plot_mat_z <- plot_mat_z[ord, , drop = FALSE] 开始
plot_mat_raw <- plot_mat[ord, , drop = FALSE]
lim <- quantile(plot_mat_raw, 0.99, na.rm = TRUE)
lim <- max(lim, 0.1)
col_fun_raw <- colorRamp2(
c(0, lim / 2, lim),
c("white", "#FDB863", "#B2182B")
)
family_anno <- read.csv(herv_map_path)
family_anno$subfamily_raw <- gsub("_", "-", family_anno$subfamily_raw)
row_class <- family_anno$class[match(rownames(plot_mat_z), family_anno$subfamily_raw)]
row_class[is.na(row_class)] <- "Unknown"
class_cols <- c(
"ERV1" = "#E6E6E6",
"ERVK" = "#969696",
"ERVL" = "#252525",
"Unknown" = "#BDBDBD"
)
right_anno <- rowAnnotation(
Class = row_class,
col = list(Class = class_cols),
show_annotation_name = TRUE,
annotation_name_gp = gpar(fontsize = 0),
simple_anno_size = unit(2, "mm")
)
celltype_cols <- setNames(hcl.colors(length(celltype_order), "Set 2"), celltype_order)
group_cols <- c("NC" = "#2B6CB0", "AD" = "#B22222")
col_order$celltype <- factor(col_order$celltype, levels = celltype_order)
col_order$group <- factor(col_order$group, levels = group_order)
top_anno <- HeatmapAnnotation(
Celltype = col_order$celltype,
Group = col_order$group,
col = list(
Celltype = celltype_cols,
Group = group_cols
),
annotation_legend_param = list(
Celltype = list(
at = celltype_order
),
Group = list(
at = group_order
)
),
annotation_name_gp = gpar(fontsize = 0),
simple_anno_size = unit(2, "mm")
)
ht_raw <- Heatmap(
plot_mat_raw,
name = "AvgExpr",
col = col_fun_raw,
top_annotation = top_anno,
right_annotation = right_anno,
cluster_rows = FALSE,
cluster_columns = FALSE,
show_row_names = TRUE,
show_column_names = FALSE,
row_names_gp = gpar(fontsize = 10),
column_names_gp = gpar(fontsize = 12),
column_names_rot = 45,
border = FALSE,
column_title = paste0("Average expression of hERV families - ", dataset),
column_title_gp = gpar(fontsize = 16),
rect_gp = gpar(col = NA)
)
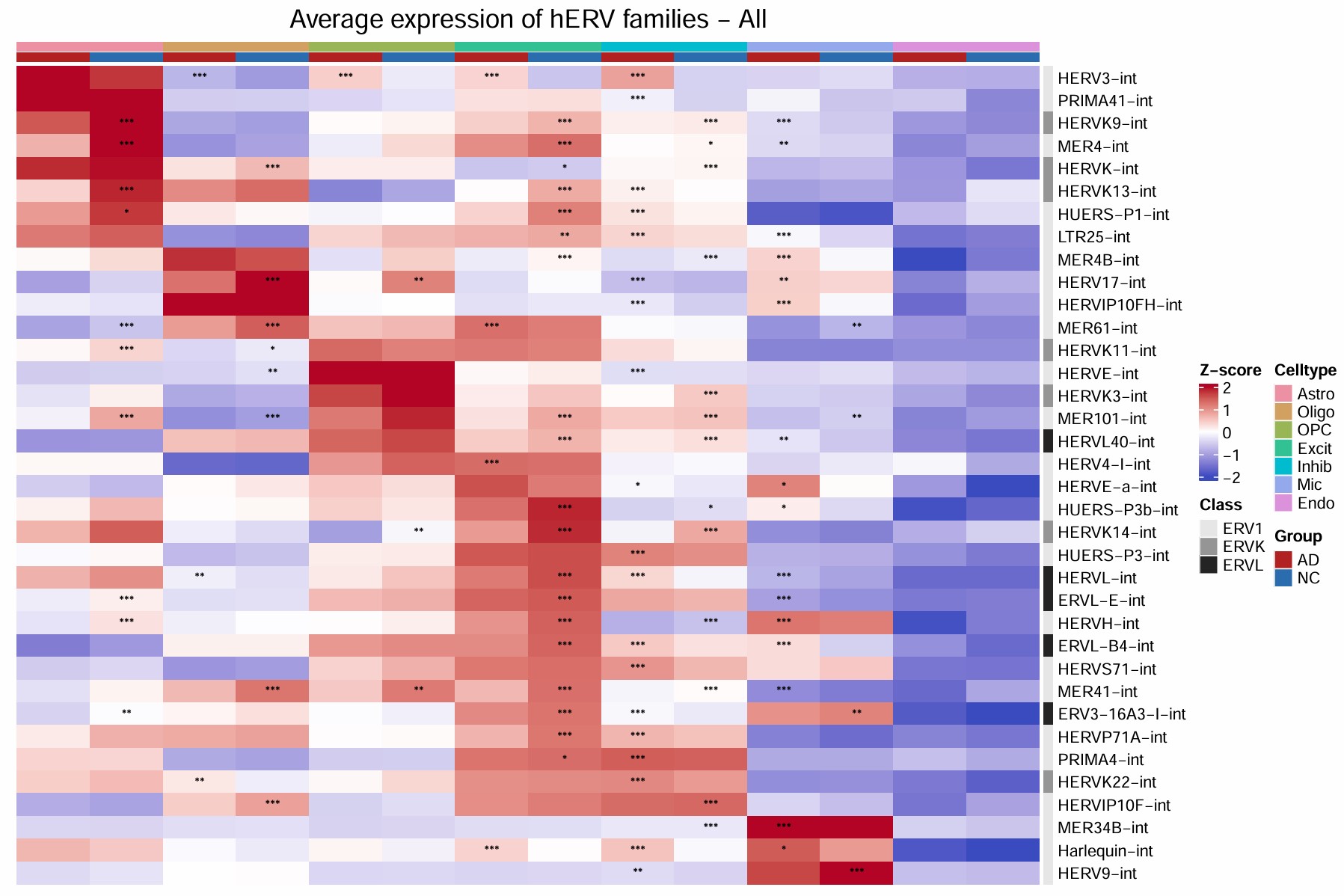
加上显著性标记:对于同一细胞类型同一hERV家族的AD-NC格子,哪个表达量更高,就把星号标在哪个格子
scTE
筛选hERV相关位点
在scTE构建参考基因组的时候,发现它是用hg38+rmsk.txt一起构建的,因此计数结果中会包括基因和TE。最后得到的feature共5.8w多个:
- HERV/ERV开头的共73个
- LTR开头的共253个
features <- read.table("C:\\Users\\17185\\Desktop\\fsdownload\\features.txt")[, 1]
herv_features <- grep("^(HERV|ERV)", features, value = T)
ltr_features <- grep("^LTR", features, value = T)
如果在rmsk.txt中根据repName/repClass/repFamily来筛选:
rmsk_file <- "rmsk.txt"
rmsk <- fread(
rmsk_file,
select = c(11, 12, 13),
col.names = c("repName", "repClass", "repFamily")
) %>% distinct(repName, repClass, repFamily)
filter_repClass <- rmsk %>%
filter(repClass %in% "LTR")
filter_repFamily <- rmsk %>%
filter(grepl("ERV", repFamily, ignore.case = TRUE))
filter_repName <- rmsk %>%
filter(grepl("^(HERV|ERV)", repName, ignore.case = TRUE))
- 按
repFamily以ERV开头来筛选,会得到500多个条目,这些条目的repFamily除了经典的ERVL/ERVK/ERV1,还会有ERVL-MaLR/ERVL?/ERV1?这种看起来很奇怪的,repName除了经典的HERV/LTR/MERxxx,还有MLT/MST/…开头的- MaLR是哺乳动物LTR逆转座子,ERVL-MaLR是和ERVL谱系关系很近的一类MaLR元素
- ERVL?/ERV1?:分类不确定/边界不清楚/暂定归类,越老的LTR/ERV片段越难精确分类
MLT1K MLT1A MLT1J2 MLT1E1A-int MLT1E1A LTR16C ERV3-16A3_I-int LTR12F LTR89 LTR103b_Mam MLT1H2 MER4D1 MER4CL34 MLT1H MLT1I LTR33 MSTB1 MLT1C MLT1F2 LTR33B MER65D MLT1D THE1C MER21C LTR41 LTR37A MER11C MSTD MLT1J MLT2B3 MER31-int MER92-int MER34A MSTA1 MER4A1 MER4A MER31B MER39B LTR9B MER4E1 MLT1E3 LTR37B MLT1O MSTA LTR39 LTR22C2 ERVL-int MLT1H1 THE1B THE1B-int MLT1H1-int LTR64 THE1D MLT1F1 LTR7 MER67C LTR67B LTR79 MER41D MLT1A1 LTR78 MLT1B LTR2C LOR1-int LTR57-int LTR49-int HERVK9-int MER9a2 MER67A HERV16-int MER4A1_ MLT1G1 LTR12C LTR13A MER49 MER50 MER41B LTR46 MER9a1 LTR13 LTR13_ MER54A MER68 MER4B MER4B-int MER66C MER66-int MER74B LTR5_Hs LTR2B Harlequin-int LTR75 LTR10A HERV9N-int HERVIP10F-int MLT1A0 LTR7B MER65A MER65-int MER52A MER52C MER83 LTR26B LTR42 MER4D MER65B LTR16E1 ERV3-16A3_LTR MLT2D MER31A MSTB ERVL-E-int LTR18B LTR40a MER74A LTR52 MLT-int MLT2C1 MLT2B1 THE1A MER66B LTR41C MER34C_ LTR26 LTR40c MER34 LTR19A MER89 MSTA-int HERVL-int LTR27B LTR27C MLT1H-int MLT2B4 MER51A LTR40b MLT1E2 ERVL-B4-int THE1C-int LTR16A1 MSTB-int LTR10B2 LTR21C LTR62 THE1D-int MER34C2 MER39 LTR5B LTR45C LTR8A LTR38 LTR38-int HERVK13-int LTR3B_ MLT1E1 LTR78B MER77 LTR3A MER77B LTR33C LTR105_Mam MLT2B2 LTR40A1 HERVL40-int MER92B LTR10E LTR16E2 MER21B LTR24C MSTC MLT1J1 MER21A MSTB2 MLT2A2 MER48 HERVH-int LTR7A LTR53B MER61B MLT1A0-int LOR1a LTR33A_ MER57B1 LTR16A2 LTR53 MER90a LTR50 LTR1A2 MER11A LTR1B1 MER61D MER61A LTR8 LTR101_Mam MLT1G MER110 MLT1N2 LTR66 HERVL66-int MER54B MER70A MLT1E LTR16D MLT1F LTR24 LTR24B MER57A1 LTR10C MLT1J-int MLT2A1 LTR48B MER34-int MER70B LTR23 ERV24_Prim-int LTR23-int MER34B LTR54 MER34C LTR16A MER34A1 MLT1L LTR16B2 LTR33A MER41A LTR8B MER4E MLT1C-int LTR16D2 LTR16B1 MLT1G1-int LTR1C THE1A-int LTR41B MLT1B-int LTR19B LTR71B LTR16D1 MER51E LTR86A1 LTR75_1 MER72 MLT1D-int MER52D LTR12E LTR21B HERVFH21-int LTR14B LTR12 MER101 LTR36 MLT1M LTR71A LTR86A2 MLT2C2 MLT1G3 LTR1F MER84 MER84-int LTR9D LTR29 LTR86C MER51B HERV9-int LTR47A MER9a3 LTR82A LTR21A LTR77 LTR61 LTR56 MER4C MER41E HERVFH19-int MER110A MER11D LTR26E MLT2B5 LTR9 LTR60B LTR2 MER57C1 MER21-int LTR83 LTR1D1 LTR51 HUERS-P1-int LTR84a MLT2F LTR84b LTR26C LTR16 LTR43B HERVIP10FH-int LTR103_Mam LTR47B2 ERV24B_Prim-int MER34B-int LTR75B LTR1C1 MER67B MLT2E LTR65 MER52-int LTR22B1 MER68-int MER70C LTR102_Mam LTR10F PRIMA4-int HERVK-int MER41G LTR44 LTR45B MER57A-int LTR45 MER101-int LTR57 HERV3-int HERVE-int LTR1C3 LTR7Y HERV9NC-int LTR12D LOR1b LTR10B LTR14A LTR22A MST-int LTR80A LTR86B1 LTR82B MLT1F-int LTR55 MLT1I-int LTR9A1 HERVL74-int LTR32 LTR16B LTR10D PRIMA4_LTR MER57E2 MER57F MLT1J1-int MER90 LTR4 MER87 LTR49 MER51D PRIMA41-int LTR39-int MER57B2 LTR54B LTR76 MER50C PABL_B LTR15 LTR38B HERV-Fc2_LTR MER61-int LTR1F1 MER4D0 HUERS-P3-int HERV35I-int LTR37-int LTR28B LTR14 HERVK14C-int MER66A MLT1A1-int LTR46-int MER4-int LTR26D MLT1A-int LTR7C MER73 LTR06 LTR48 MER41-int MLT1E3-int PABL_A LTR28C MLT1K-int MER57-int LTR47A2 MER50-int PABL_B-int MER66D LTR87 HERV1_LTRd LTR80B MLT1E2-int MER57E1 MER41C MSTD-int LTR22B2 LTR6A MER51C LTR35A HERV4_I-int MLT1J2-int MER34D MER51-int MER65C LTR12B MER57D LTR35 MER50B LTR1D MSTA1-int MLT1G-int LTR31 LTR1E HERVK22-int LTR17 MER83B PrimLTR79 LTR27 HERV30-int MER74C LTR1 HUERS-P3b-int LTR6B LTR38A1 HERVS71-int HERVK11-int MLT1F2-int THE1-int LTR86B2 LTR69 MLT1H2-int LTR1F2 MER89-int LTR2752 LTR1B0 LTR43 MLT1N2-int MER70-int LTR5A LTR34 HERV17-int MSTB1-int PABL_A-int MER68C LTR91 LTR3B MER76 MLT1L-int LTR47B4 LTR19-int MER11B HERVIP10B3-int LTR108a_Mam MSTC-int MER83B-int MER61F LTR1A1 MLT1F1-int MLT1-int LTR72B LTR27E LTR22C0 LTR68 LTR12_ PRIMAX-int LTR28 MER68B MER95 MER61C HERVK14-int MER92A MER61E LTR18A HERVL18-int MLT1O-int MER72B LTR47B3 LTR1B LTR9C HUERS-P2-int MER92D MER110-int MER83C LTR53-int HERVP71A-int MER101B HERVL32-int LTR58 LTR22E LTR73 MLT1E-int MER57C2 LTR35B LTR22B LTR27D LTR5 LTR19C LTR25-int HERVH48-int LTR30 LTR52-int MSTB2-int HERVKC4-int HERVE_a-int LTR22 MER67D MER87B MLT1G3-int MER88 LTR108e_Mam MER92C HERVI-int LTR10B1 LTR25 LTR60 LTR3 HERVK3-int LTR108d_Mam LTR18C MER83A-int LTR72 MER76-int LTR14C LTR47B LTR38C HERV1_LTRa LTR10G LTR108c_Mam LTR108b_Mam ERVL47-int LTR59 MER57E3 LTR70 HERVK11D-int MLT1E1-int HERV1_I-int MER9B LTR43-int HERV1_LTRe HERV-Fc1_LTR1 HERV-Fc1_LTR2 HERV-Fc2-int HERV-Fc1-int HERV1_LTRc HERV15-int HERV-Fc1_LTR3 HERV1_LTRb LTR109A2 LTR22C MLT1M-int MLT1C2 EUTREP7 Eutr10 LTR89B MLT1C2-int EUTREP15 LTR103b_Mam Eutr10 LTR55 ERV3-16A3_I LTR89B LTR89 LTR103_Mam MER34C_v MER4A1_v LTR33A_v LTR13_v LTR87 LTR12_v LTR3B_v HERV4_I -
按
repName以HERV/ERV开头来筛选,这回结果就比较统一,它们的repClass都是LTR,repFamily都是ERVL/ERVK/ERV1。基本都有-int后缀(像stellarscope的repName),也有少部分是_LTR的后缀ERV3-16A3_I-int ERVL-int HERVK9-int HERV16-int HERV9N-int HERVIP10F-int ERV3-16A3_LTR ERVL-E-int HERVL-int ERVL-B4-int HERVK13-int HERVL40-int HERVH-int HERVL66-int ERV24_Prim-int HERVFH21-int HERV9-int HERVFH19-int HERVIP10FH-int ERV24B_Prim-int HERVK-int HERV3-int HERVE-int HERV9NC-int HERVL74-int HERV-Fc2_LTR HERV35I-int HERVK14C-int HERV1_LTRd HERV4_I-int HERVK22-int HERV30-int HERVS71-int HERVK11-int HERV17-int HERVIP10B3-int HERVK14-int HERVL18-int HERVP71A-int HERVL32-int HERVH48-int HERVKC4-int HERVE_a-int HERVI-int HERVK3-int HERV1_LTRa ERVL47-int HERVK11D-int HERV1_I-int HERV1_LTRe HERV-Fc1_LTR1 HERV-Fc1_LTR2 HERV-Fc2-int HERV-Fc1-int HERV1_LTRc HERV15-int HERV-Fc1_LTR3 HERV1_LTRb ERV3-16A3_I HERV4_I- 注意:上面的feature直接按
HERV/ERV开头来筛选,可能会得到一些不属于rmsk范畴的feature(不在rmsk的repName里),而是属于gene的范畴,因此后面筛选feature时应与rmsk的repName取交集
ERV3-1 ERVE-1 ERVFRD-1 ERVFRD-3 ERVH-1 ERVH48-1 ERVK-28 ERVK13-1 ERVK3-1 ERVK9-11 ERVMER34-1 ERVMER61-1 ERVV-1 ERVV-2 ERVW-1 - 注意:上面的feature直接按
LTR/MER开头的这种,是否应该归入具体某类hERV中:参考stellarscope作者提供的hERV的subfamily-group映射families.tsv,stellarscope作者给出的gtf文件应该就是把LTR归入了具体某类hERV之后的(也因此根据这个gtf得到的family-level的feature只有几个特殊的LTRxxx,而不是像rmsk里面有数百个),所以严格来说家族名的-int后缀其实不能表示“这个家族的计数都是internal区域的计数”,只是因为这个gtf注释“以internal model为主名,LTR作为组成部分”的习惯性设计
rmsk_map <- fread(
rmsk_file,
select = c(11, 12, 13),
col.names = c("repName", "repClass", "repFamily")
) %>% distinct(repName, repClass, repFamily)
collapse_erv_family <- function(x) {
x <- toupper(x)
case_when(
grepl("^ERVK", x) ~ "ERVK",
grepl("^ERVL", x) ~ "ERVL",
grepl("^ERV1", x) ~ "ERV1",
TRUE ~ NA_character_
)
}
tab <- rmsk_map %>%
transmute(
repName = repName,
repClass = collapse_erv_family(repFamily)
) %>%
filter(!is.na(repClass)) %>%
distinct()
最后决定把scTE的计数分成3个层次:
HERV_subfamily_scTE:提取以HERV/ERV开头的repNameHERV_subfamily_LTR_scTE:在HERV_subfamily_scTE的基础上,根据families.tsv把一些LTR也归入到部分HERV中HERV_class_scTE:提取以ERV开头的repFamily,得到ERVL/ERVK/ERV1级别的计数
最后得到的HERV:
-
原始的不含LTR的、以
^ERV|HERV筛选得到的结果:ERV24B-Prim-int ERV24-Prim-int ERV3-16A3-I-int ERV3-16A3-LTR ERVL47-int ERVL-B4-int ERVL-E-int ERVL-int HERV15-int HERV16-int HERV17-int HERV1-I-int HERV1-LTRa HERV1-LTRb HERV1-LTRc HERV1-LTRd HERV1-LTRe HERV30-int HERV35I-int HERV3-int HERV4-I-int HERV9-int HERV9NC-int HERV9N-int HERVE-a-int HERVE-int HERV-Fc1-int HERV-Fc1-LTR1 HERV-Fc1-LTR2 HERV-Fc1-LTR3 HERV-Fc2-int HERV-Fc2-LTR HERVFH19-int HERVFH21-int HERVH48-int HERVH-int HERVI-int HERVIP10B3-int HERVIP10FH-int HERVIP10F-int HERVK11D-int HERVK11-int HERVK13-int HERVK14C-int HERVK14-int HERVK22-int HERVK3-int HERVK9-int HERVKC4-int HERVK-int HERVL18-int HERVL32-int HERVL40-int HERVL66-int HERVL74-int HERVL-int HERVP71A-int HERVS71-int -
把LTR合并进去的结果:
ERV3-16A3-I ERVL ERVL-B4 ERVL-E Harlequin HERV17 HERV3 HERV30 HERV4-I HERV9 HERVE HERVE-a HERV-Fc1 HERV-Fc2 HERVFH19 HERVFH21 HERVH HERVH48 HERVI HERVIP10F HERVIP10FH HERVK HERVK11 HERVK11D HERVK13 HERVK14 HERVK14C HERVK22 HERVK3 HERVK9 HERVKC4 HERVL HERVL18 HERVL32 HERVL40 HERVL66 HERVL74 HERVP71A HERVS71 HUERS-P1 HUERS-P2 HUERS-P3 HUERS-P3b LTR19 LTR23 LTR25 LTR46 LTR57 MER101 MER34B MER4 MER41 MER4B MER50 MER61 PABL-A PABL-B PRIMA4 PRIMA41 PRIMAX
与stellarscope计数的差异
就从后面频繁使用的几个hERV家族开始看起
fam_use <- c("HERVK", "HERVK3", "HERVK9", "HERVK11", "HERVK13", "HERVK14", "HERVK22", "HERVH", "HERVE", "HERV3", "HERV-Fc1", "HERV17", "HERVL")
mat_ref <- GetAssayData(seu, assay = "HERV_family", slot = "data")
mat_sct <- GetAssayData(seu, assay = "HERV_subfamily_LTR_scTE", slot = "data")
cnt_ref <- GetAssayData(seu, assay = "HERV_family", slot = "counts")
cnt_sct <- GetAssayData(seu, assay = "HERV_subfamily_LTR_scTE", slot = "counts")
rownames(mat_ref) <- gsub("-int", "", rownames(mat_ref))
rownames(cnt_ref) <- gsub("-int", "", rownames(cnt_sct))
fam_use <- intersect(fam_use, rownames(mat_ref))
fam_use <- intersect(fam_use, rownames(mat_sct))
mat_ref <- mat_ref[fam_use, , drop = FALSE]
mat_sct <- mat_sct[fam_use, colnames(mat_ref), drop = FALSE]
cnt_ref <- cnt_ref[fam_use, , drop = FALSE]
cnt_sct <- cnt_sct[fam_use, colnames(cnt_ref), drop = FALSE]
相关性:
res_list <- list()
plot_list <- list()
for (fam in fam_use) {
x <- as.numeric(mat_ref[fam, ])
y <- as.numeric(mat_sct[fam, ])
x_cnt <- as.numeric(cnt_ref[fam, ])
y_cnt <- as.numeric(cnt_sct[fam, ])
diff_xy <- y - x
mean_xy <- (x + y) / 2
pearson_r <- cor(x, y, method = "pearson")
spearman_rho <- cor(x, y, method = "spearman")
vx <- var(x)
vy <- var(y)
cxy <- cov(x, y)
mx <- mean(x)
my <- mean(y)
ccc <- 2 * cxy / (vx + vy + (mx - my)^2)
bias <- mean(diff_xy)
sd_diff <- sd(diff_xy)
mae <- mean(abs(diff_xy))
rmse <- sqrt(mean(diff_xy^2))
loa_low <- bias - 1.96 * sd_diff
loa_high <- bias + 1.96 * sd_diff
loa_width <- loa_high - loa_low
det_ref <- x_cnt > 0
det_sct <- y_cnt > 0
det_rate_ref <- mean(det_ref)
det_rate_sct <- mean(det_sct)
det_overlap <- mean(det_ref & det_sct)
det_jaccard <- sum(det_ref & det_sct) / sum(det_ref | det_sct)
res_list[[fam]] <- data.frame(
family = fam,
pearson_r = pearson_r,
spearman_rho = spearman_rho,
CCC = ccc,
bias = bias,
MAE = mae,
RMSE = rmse,
LOA_low = loa_low,
LOA_high = loa_high,
LOA_width = loa_width,
detect_rate_HERV_family = det_rate_ref,
detect_rate_scTE = det_rate_sct,
detect_overlap = det_overlap,
detect_jaccard = det_jaccard
)
plot_list[[fam]] <- data.frame(
family = fam,
ref = x,
scte = y,
mean_xy = mean_xy,
diff_xy = diff_xy,
ref_detect = det_ref,
scte_detect = det_sct
)
}
cmp_res <- bind_rows(res_list)
cmp_plot_df <- bind_rows(plot_list)
View(select(cmp_res, family, pearson_r, spearman_rho, CCC, bias, MAE, RMSE, LOA_width, detect_jaccard))
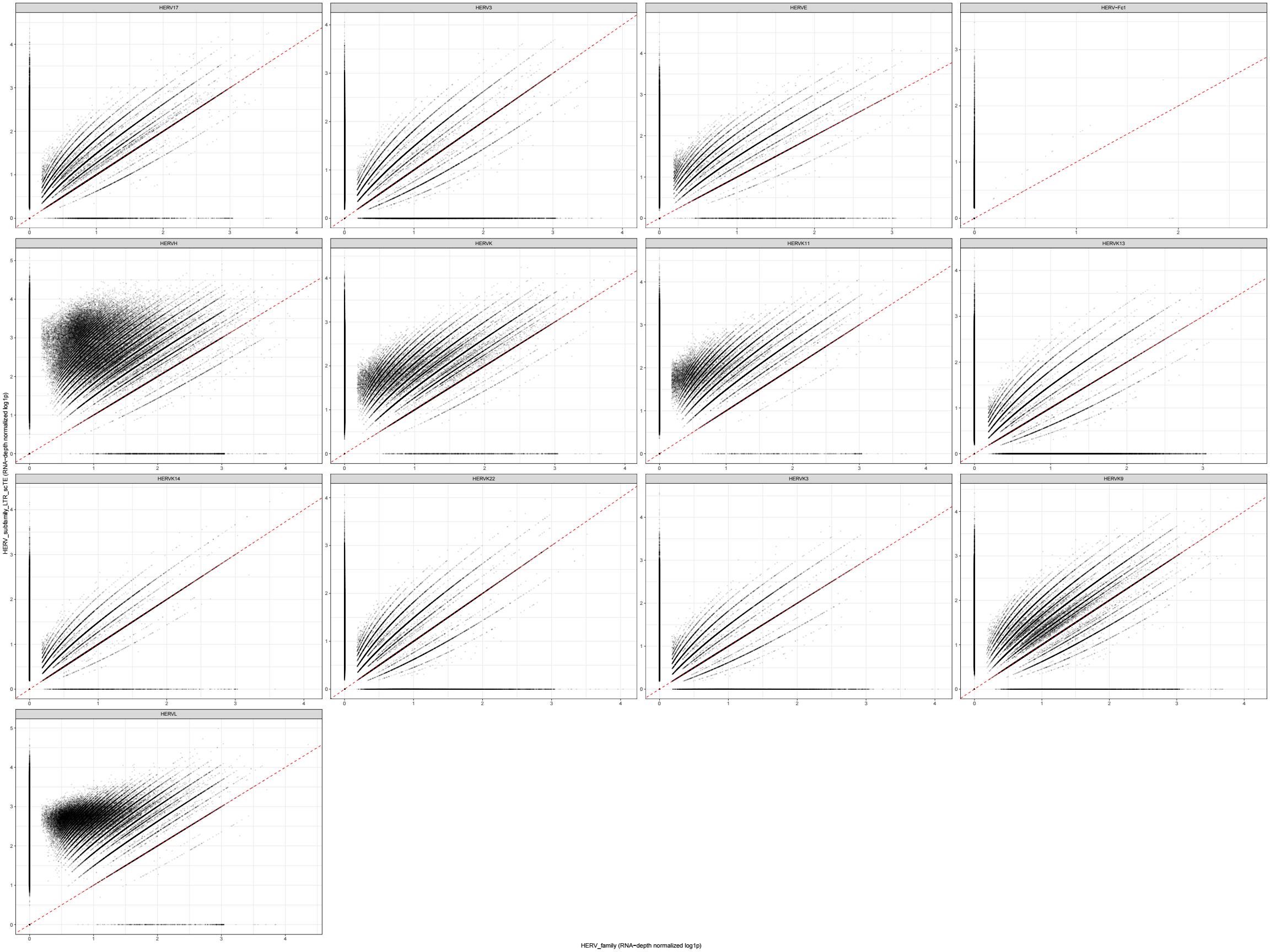
ggplot(cmp_plot_df, aes(x = ref, y = scte)) +
geom_point(size = 0.2, alpha = 0.15) +
geom_abline(slope = 1, intercept = 0, linetype = 2, color = "red") +
facet_wrap(~ family, scales = "free") +
labs(
x = "HERV_family (RNA-depth normalized log1p)",
y = "HERV_subfamily_LTR_scTE (RNA-depth normalized log1p)"
) +
theme_bw()
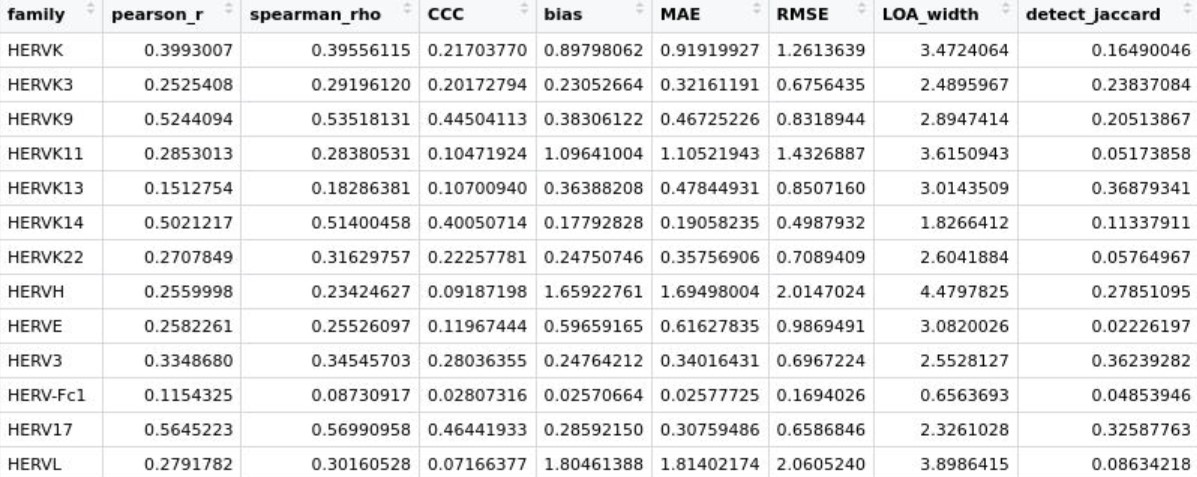
- pearson_r/spearman_rho:相关性
- CCC:一致性,最关键
- bias:是否系统性偏高/偏低
- MAE/RMSE:单细胞差异到底有多大
- LOA_width:细胞间误差波动有多大
- detect_jaccard:两者检测到的细胞是否一致
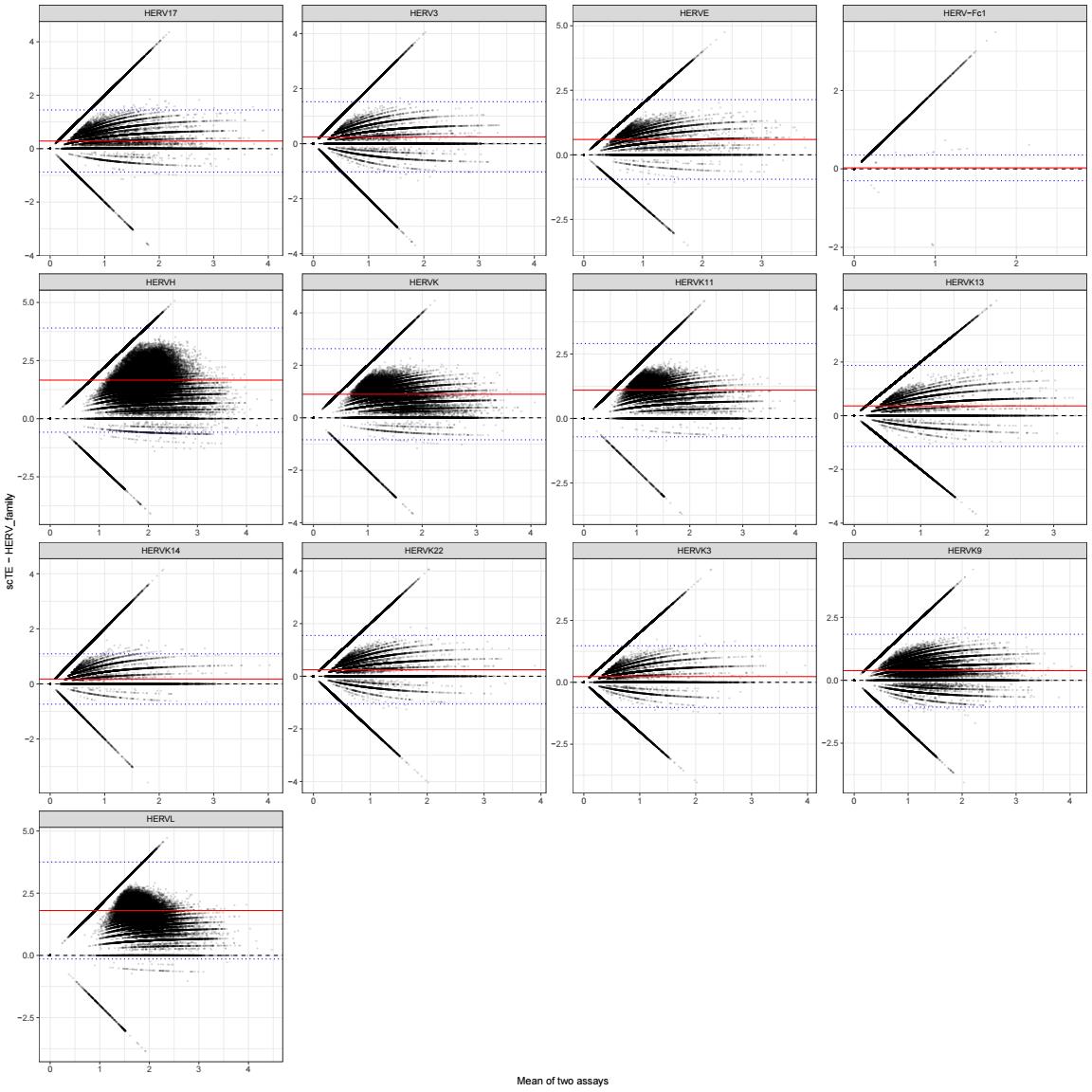
差异大小:
ba_line_df <- cmp_res %>%
select(family, bias, LOA_low, LOA_high)
ggplot(cmp_plot_df, aes(x = mean_xy, y = diff_xy)) +
geom_point(size = 0.2, alpha = 0.15) +
geom_hline(yintercept = 0, linetype = 2) +
geom_hline(data = ba_line_df, aes(yintercept = bias), color = "red") +
geom_hline(data = ba_line_df, aes(yintercept = LOA_low), color = "blue", linetype = 3) +
geom_hline(data = ba_line_df, aes(yintercept = LOA_high), color = "blue", linetype = 3) +
facet_wrap(~ family, scales = "free") +
labs(
x = "Mean of two assays",
y = "scTE - HERV_family"
) +
theme_bw()
- 横轴是两者平均值,纵轴是两者差值
scTE - HERV_family - 红线是平均偏差
bias,蓝线是95% limits of agreement(差值的95%分布范围)- 蓝线越宽,说明单细胞差异越大
- 红线离0越远,说明系统偏移越明显
- 如果点云整体围绕0对称,说明两者一致性好;如果整体偏上/偏下,说明有系统性偏移
看一下HERV_subfamily_scTE(未把LTR加到hERV里)的情况
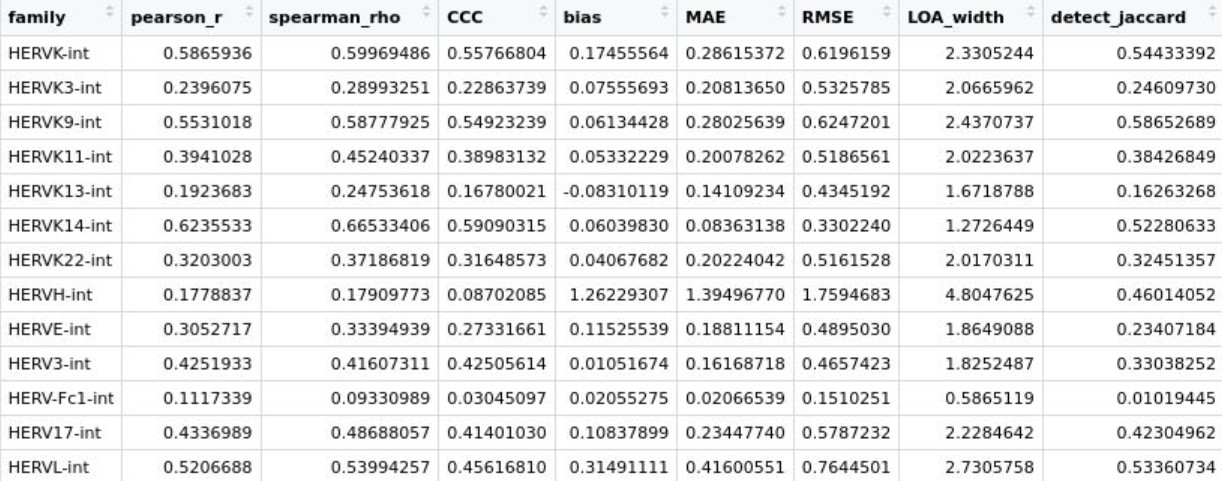

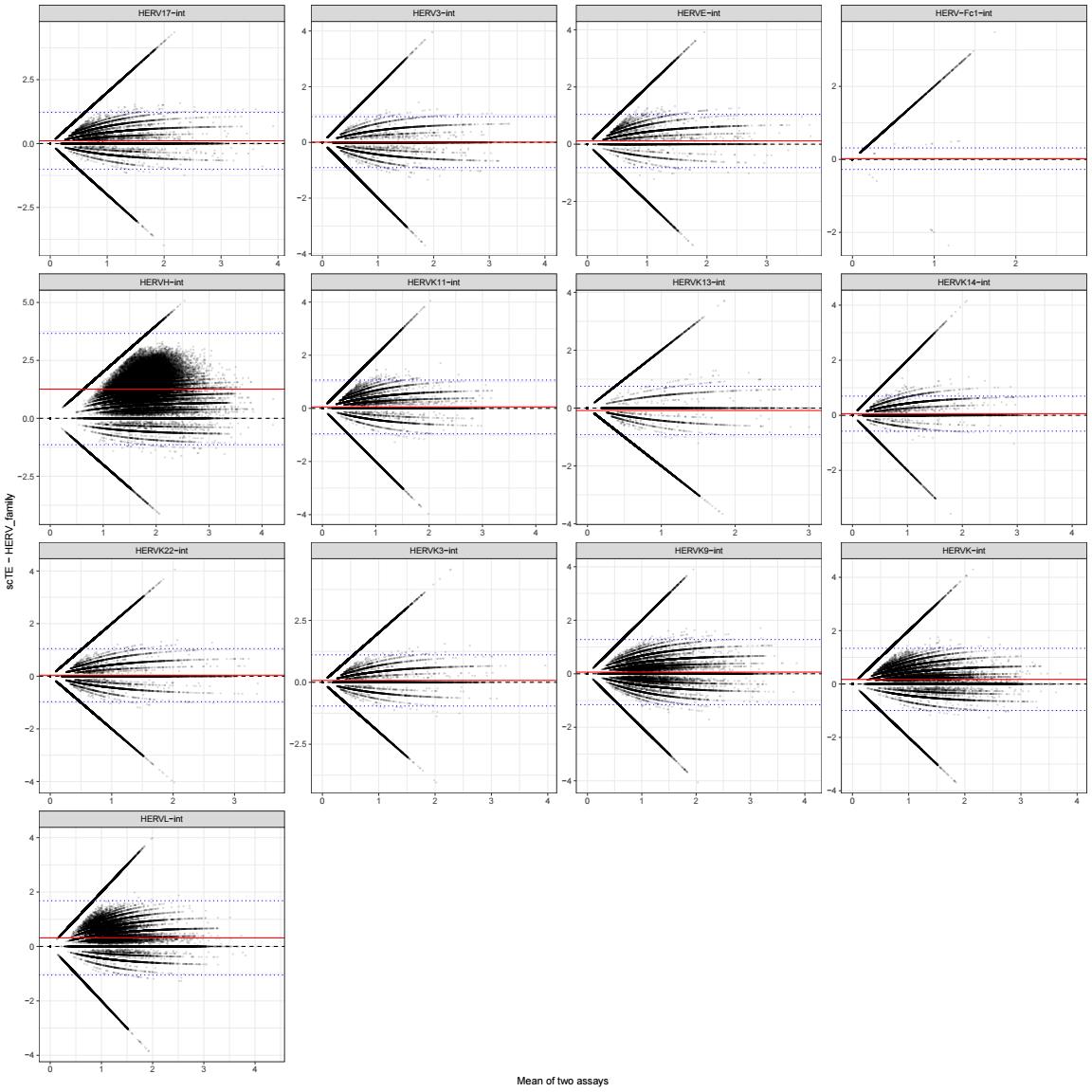
综上所述,总体上scTE得到的计数更大,HERV_subfamily_scTE这个assay的相关性更高、偏差更小,虽然前面说stellarscope的计数似乎是把LTR融到了HERV里,但根据上面的结果图,实际上似乎还是取的int序列,也许作者的gtf文件里还是在hERVx后面加上了-int就是这个意思?
- 大多数hERV family相关性都比较高,只有HERVH这个无论是算LTR还是不算,计数都明显比stellarscope高
位点解释
- GWAS:看“某个遗传变异”和“疾病/性状”是否相关。它告诉你这个区域可能和AD风险有关,但不直接告诉你是哪个基因、也不直接告诉你和hERV转录有没有关系
- eQTL:看“某个遗传变异”和“某个基因表达量”是否相关。它更接近“调控”这一层。公开资源里最实用的是GTEx、MetaBrain、eQTL Catalogue
- genome browser图:看这个hERV位点在基因组里的位置关系,比如在不在某个基因内部、是不是同链、附近有没有ncRNA注释、有没有候选调控元件。这一步是结构解释,不是遗传统计
主要思路:
- genome browser展示locus周围基因组环境:判断这个hERV位点更像是宿主基因转录本的一部分/某个isoform相关信号,还是更像独立转录出来的hERV/ncRNA样信号
- 公开数据库做外部支持:我观察到的位点-gene关系,是否落在已有疾病遗传学/表达调控框架里
anno <- read.csv("C:/Users/17185/Desktop/fsdownload/locus_summary.csv", stringsAsFactors = FALSE) %>%
mutate(locus_id = gsub("_", "-", locus_id))
plot_loci <- c(
"HARLEQUIN-6p21.31",
"HERVW-15q21.2",
"MER41-13q13.3",
"HML1-1q32.1",
"HML3-1q32.1b",
"HML4-16p13.3"
)
bed <- anno %>%
filter(locus_id %in% plot_loci) %>%
separate(coord, into = c("chr", "pos"), sep = ":", remove = FALSE) %>%
separate(pos, into = c("start", "end"), sep = "-") %>%
mutate(
start = as.integer(start) - 1L,
end = as.integer(end),
score = 0L
) %>%
select(chr, start, end, locus_id, score, strand)
write.table(
bed,
"C:/Users/17185/Desktop/hERV_AD_snRNA-seq_analyze/res/herv_locus_anal/herv_browser.bed",
sep = "\t",
quote = FALSE,
row.names = FALSE,
col.names = FALSE
)
track_line <- 'track name="hERV_loci" description="locus-level hERVs" visibility=pack color=220,20,60'
writeLines(track_line, "C:/Users/17185/Desktop/hERV_AD_snRNA-seq_analyze/res/herv_locus_anal/herv_browser_ucsc.txt")
write.table(
bed,
"C:/Users/17185/Desktop/hERV_AD_snRNA-seq_analyze/res/herv_locus_anal/herv_browser_ucsc.txt",
sep = "\t",
quote = FALSE,
row.names = FALSE,
col.names = FALSE,
append = TRUE
)
进入UCSC基因组浏览器。点击”Add custom tracks”,将txt文件导入,以chr13:38553326-39614475的形式搜索位点,可以看到我们导入的herv位点


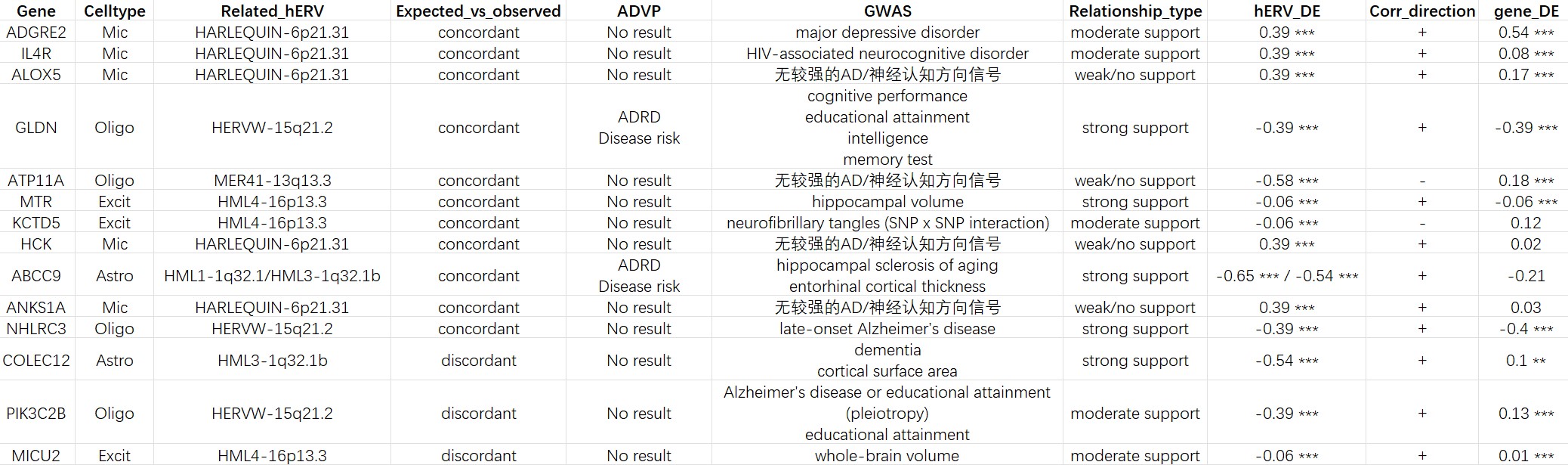
总结byGPT:结合genome browser局部注释与局部候选基因共表达分析,我们将代表性locus-level hERV位点大致分为三类。第一类为宿主基因相关型,包括HARLEQUIN-6p21.31和HERVW-15q21.2:前者位于ANKS1A基因内部并与ANKS1A呈显著正相关,后者则位于GLDN内部且与GLDN稳定正相关,提示其信号更可能与局部宿主转录本相关。第二类为共享非编码转录单元型,包括HML1-1q32.1和HML3-1q32.1b:二者位于同一局部区域,但均未获得PM20D1或SLC26A9的显著宿主支持,更可能共同代表一条astrocytic非编码hERV位点轴。第三类为独立转录/调控相关型,包括MER41-13q13.3和HML4-16p13.3:二者均缺乏典型宿主基因同链结构,其中MER41-13q13.3与NHLRC3呈区域性正相关,而HML4-16p13.3与KCTD5呈显著负相关,提示其更可能反映独立hERV转录或局部调控环境相关信号。进一步结合先前的trans共表达结果可见,这些位点并非简单重复AD/NC差异,而是在不同细胞类型中分别标记若干相对独立的转录状态轴
-
GLDN:browser上是典型宿主基因内同链位点,表达上又稳定正相关;GWAS侧虽然不是直接AD命中,但有cognitive performance、educational attainment、intelligence、memory test等多条认知相关记录,还碰到neurofibrillary tangles相关条目;ADVP中也有相关记录
有明确的认知/神经表型背景支持,提示HERVW-15q21.2相关的少突状态轴可能连接到更广义的脑功能/认知遗传背景
-
ABCC9:GWAS里虽然不是直接AD,但有hippocampal sclerosis of aging和entorhinal cortical thickness,这两个都和脑老化/神经退行背景很贴近;ADVP中也有相关记录
与astrocytic hERV轴稳定相关,同时具有脑老化相关遗传学线索
-
COLEC12:有dementia的直接命中,而且还有cortical surface area等脑结构相关条目
HML3这条astrocytic hERV轴并不是简单重复疾病均值差,而是落在更广义的神经退行/脑结构背景中
- NHLRC3:有late-onset Alzheimer’s disease直接条目;对MER41-13q13.3这条Oligo位点很有价值,因为MER41本来在browser上就更偏独立/局部区域耦联型,而NHLRC3正好可以作为“区域层面的AD相关支持”
- MTR:GWAS里有hippocampal volume,这对Excit来说是不错的神经相关支持;虽然不是AD直接条目,但和“神经元代谢/一碳代谢背景”这条解释不冲突
-
PIK3C2B:有Alzheimer’s disease or educational attainment (pleiotropy)以及educational attainment等遗传学线索,但和hERV方向discordant
该基因具有一定的认知/AD相关遗传学背景,但其AD/NC方向与HERVW-15q21.2不一致,提示该基因更可能参与少突细胞状态协同,而非简单作为该位点在AD中的直接输出
- MICU2:有whole-brain volume相关条目,更偏泛脑结构量化表型,而且DE效应很小
- KCTD5:有neurofibrillary tangles (SNP x SNP interaction),但不是最核心的基因,而是局部邻近基因,适合写成“局部调控环境的补充支持”,不适合当主轴
- ADGRE2:GWAS里有major depressive disorder条目,但它更偏精神疾病/免疫背景,不是AD特异
- IL4R:HIV-associated neurocognitive disorder,和神经免疫/认知损伤背景可能有点关系,但太间接了
几个总结点:
- ADVP结果整体偏少:挑出来的gene,大多数不是已经被AD领域反复确认的核心风险基因
- GWAS Catalog里能看到更多“脑结构/认知/衰老/痴呆相关”线索:挑出来的gene不是随机挑的,而是落在更广义的神经生物学遗传背景里
- 支持程度在不同细胞类型并不一样:Oligo/Astro这两条线的遗传学整合最好看,Excit次之,Mic更多还是靠免疫程序和共表达来支撑,而不是AD数据库直接命中
总结byGPT:进一步结合公开遗传学数据库可见,这些与位点级hERV稳定相关的候选基因,并不普遍对应经典AD核心风险基因。ADVP结果整体较少,而GWAS Catalog中则可见更多脑结构、认知表现、衰老和痴呆相关条目。例如,Oligo中的GLDN与认知表现、教育年限和记忆测试相关,Astro中的ABCC9与hippocampal sclerosis of aging及entorhinal cortical thickness相关,COLEC12则直接出现dementia相关记录,MER41-13q13.3邻近的NHLRC3还可见late-onset Alzheimer’s disease条目。相比之下,部分Mic相关基因如ADGRE2、IL4R和ALOX5虽有一定精神/免疫背景线索,但缺乏直接AD特异支持。总体而言,这些结果更支持位点级hERV所对应的是若干细胞类型特异的转录状态轴,这些状态轴与神经认知、脑结构和衰老遗传背景存在不同程度联系,而非简单重复AD/NC差异
- 公开GWAS数据库的证据表明,hERV相关候选基因的遗传学支持具有明显异质性。部分基因,如GLDN、ABCC9、COLEC12和NHLRC3,可在认知、脑结构、衰老或痴呆相关表型中找到支持;另一些基因则主要表现为局部状态轴或免疫背景关联,而缺乏直接AD特异条目。这提示本研究识别的位点级hERV-gene关系,更可能代表特定细胞状态在疾病背景中的组织方式,而不是单一的经典风险通路
部分基因的DE方向与预期相反(比如oligo的HERVW-15q21.2在AD下调,HERVW-15q21.2与PIK3C2B正相关,但PIK3C2B却在AD中上调):
- 相关性描述的是细胞类型内部的协同变化轴(“哪个donor/423/NC两组均值差异。两者可以一致,也可以不一致
- 这条hERV轴和AD/NC轴不是同一件事:HERVW-15q21.2 ~ PIK3C2B这条正相关,更多反映Oligo内部某种状态协同;但AD整体又额外推动了PIK3C2B往上走,所以最后组间均值方向和hERV不一致
- 基因同时受两股力量影响:一股是和hERV绑定的状态轴,另一股是AD背景下独立存在的疾病效应
-
组内协同很稳定,但组间平均差很小或很混杂:虽然统计显著,但你的avg_log2FC非常小,基本更像“大样本把一个极小差别检出来了”,生物学效应并不强
与HML4-16p13.3存在稳定协同变化,但其AD/NC组间差异幅度很小,提示该基因更可能反映局部状态协同,而不是该位点在AD中的主要输出方向
- 细胞组成/亚状态比例在组间变化:如果AD组里某个亚状态比例变化,会让gene的均值变化方向和hERV-state axis不完全一致
- 总结:多数代表性gene的AD/NC变化方向与对应hERV位点的相关方向总体一致,但也存在少数不一致的基因,如PIK3C2B、COLEC12和MICU2。这提示位点级hERV更可能对应细胞状态协同变化轴,而非简单等同于疾病组间均值变化
文献阅读
hERVK env上调
- 只有散发性AD(sAD)患者血液中的HERV-K env转录本升高,其它检测到的HERV转录本在散发性/遗传性AD和FTD中都没有达到显著上调
- 做的主要是DNA甲基化分析,发现一些与HERV调控相关的基因出现高甲基化
- 提示“HERV-K env在sAD外周血中可能是一个特异信号”,而不是证明“AD中hERV整体广泛激活”
在这篇文章中,hERV的重调情况是怎样的,这篇文章用了什么数据。文章中上调的是HERVK的env,env和其它hERV片段很不一样吗?
-
env和一般“片段”最大的不同,在于它更可能对应一个有功能含义的编码区。在ERV的组成中,LTR是调控元件,gag/pol/env编码病毒核心,env编码包膜蛋白。env蛋白主要负责识别宿主细胞表面的受体,同时促进膜融合,让病毒进入细胞,所以是一种“直接和宿主界面接触”的蛋白,可能影响免疫识别、炎症反应等待
不过这里作者检测的是env的RNA,而不是env蛋白,因为大多数hERV都不能产生完整翻译产物,不过确实要比只说“某个hERV片段上调”更有意义,因为病毒编码区上调更有可能意味着会翻译蛋白而影响宿主细胞
-
文章中用的是qRT-PCR这种检测方法,如果作者事先就设计了针对HERV-K env那一段的引物,那么PCR扩增出来的信号,本来就是“这段env有没有升高”。如果是bulk RNA-seq,如果注释中有env这个feature的话就也能测出来,如果是scRNA-seq,因为每个细胞的reads更少,覆盖很浅,所以难度更高。对于我这种注释以及短读长的测序数据,即便某个位点真的转录了包含env的RNA,也只能知道read在HERVK家族的某段internal区域,但env只是internal中的一个功能区,不一定能被单独拆出来
另一种hERV计数方法
The landscape of hervRNAs transcribed from human endogenous retroviruses across human body sites
- 使用bulk RNA-seq样本,研究正常人体中hervRNA表达图谱
- 主要结论:正常组织中存在大量位点特异、组织特异的hervRNA
- 总共鉴定了13889个locus-specific expressed HERVs,其中7566个是body site-specific
- 脑组织里hervRNA很多,尤其小脑很突出
这篇文章采用的技术路线和我用STAR+stellarscope的方法有什么不同?
- 先把疑似HERV相关reads提取出来→重建转录本→再贴回基因组→再用重建结果做定量
- 重建转录本:不是只看某个基因组位置上有没有reads落上去,而是要把这些reads尽量拼回成一条完整或较完整的RNA转录本
- 先把疑似来自HERV区域的RNA-seq reads提取出来
- 把这些短reads按重叠关系“拼接”起来
- 得到一条条候选转录本序列
- 再把这些候选转录本重新比对回人基因组,判断它们来自哪里、结构是什么样
相比“基于已有注释,把reads分配到已知HERV位点”的定量计数方法,重建转录本可以看到——这是不是一条真实存在的RNA、它的长度大概多长、它的边界在哪里、它是不是一个完整HERV转录本、它的具体状态和相邻结构是怎样的(是solo-LTR、截短HERV、嵌合转录本,还是与邻近基因连在一起)
不过这种方法需要更高覆盖度,因此更适合bulk RNA-seq
- 在重建过程中,多重比对的hervRNA转录本很难精确归位,在他们当前流程里会被舍弃,因此可能会漏掉一部分信号,也就是说,这篇文章更偏“高特异、低噪音”,而在我的scRNA-seq数据中,因为信号本来就稀疏,所以要尽量保留reads,也因此Stellarscope的重点就是在高度重复的位点间分配多重比对reads
- 筛选reads:找那些比对到了HERV数据库(HERVd)标注区域里、但又不属于常规基因转录本(Gencode注释)的reads。相当于保留“纯HERV来源”的reads,排除“成为宿主基因一部分的hERV/嵌在普通基因里面的hERV序列/和普通基因有重叠的hERV”
- 转录本QC:组装后转录本count>5、与参考基因组相似度≥96%、组装后长度≥200bp、至少在≥50%样本中出现、能唯一定位到某个HERV位点(无多重比对)。同时还做了实验验证,随机选取部分HERV做RT-PCR、Sanger测序和RT-qPCR,来证明流程确实能找出真实存在的转录本
- 单细胞内每个细胞的HERV reads太稀,可能无法组装
hERV位点和邻近基因/promoter
主要思路:把位点级别herv分成不同的功能类别(比如作为基因的alternative promoter/enhancer,或是作为一个alternative exon/ltr形成chimeric transcripts),再按类别具体分析
后续补充研究
gtf文件gene行染色体范围和基因的重叠,比较是不是重叠多的表达高
GO分析涵盖MF和CC
单个数据集是否可复现?
我的表达多的类别是不是别人也报道了,和total RNA的报道的是不是相同