毕设过程中的结果图汇总
other-other涉及到的各种结果图,并不一定都写在正文中
构建Seurat对象和数据预处理
构建Seurat对象
> seu
An object of class Seurat
93660 features across 243200 samples within 2 assays
Active assay: RNA (78691 features, 0 variable features)
1 layer present: counts
1 other assay present: HERV
> colnames(seu@meta.data)
[1] "orig.ident" "nCount_RNA" "nFeature_RNA" "nCount_HERV"
[5] "nFeature_HERV" "GSM" "group" "tissue"
[9] "age" "sex" "PMD" "hist.diagnosis"
[13] "diag.1" "diag.2" "diag.3" "age.related.plaque.score"
[17] "braak.tangle.stage" "APOE" "dataset" "PMI"
[21] "Neuropath.Dx.1" "Neuropath.Dx.2" "Clinical.Syndrome" "Plaque.Stage"
[25] "Plaques.Tangles" "Braak...Braak.Stage" "RIN" "sample_uid"
[29] "donor_uid" "percent_mito" "percent_ribo" "HERV_fraction"
> table(seu$dataset)
GSE157827 GSE174367
181653 61547
> table(seu$group)
NC AD
107420 135780
> table(seu$orig.ident)
100 17 19 22 27 33 37 43 45 46 47 50 52 58 66 82 90 96 AD1 AD10
4642 3804 3094 2776 3839 2685 3945 4887 4753 3472 3051 2690 2813 2714 2886 2481 2519 4496 6165 16437
AD13 AD19 AD2 AD20 AD21 AD4 AD5 AD6 AD8 AD9 NC11 NC12 NC14 NC15 NC16 NC17 NC18 NC3 NC7
1841 3898 15607 9430 8736 5895 12623 3204 2679 10269 3560 15727 10951 8492 6899 14572 11821 6439 6408
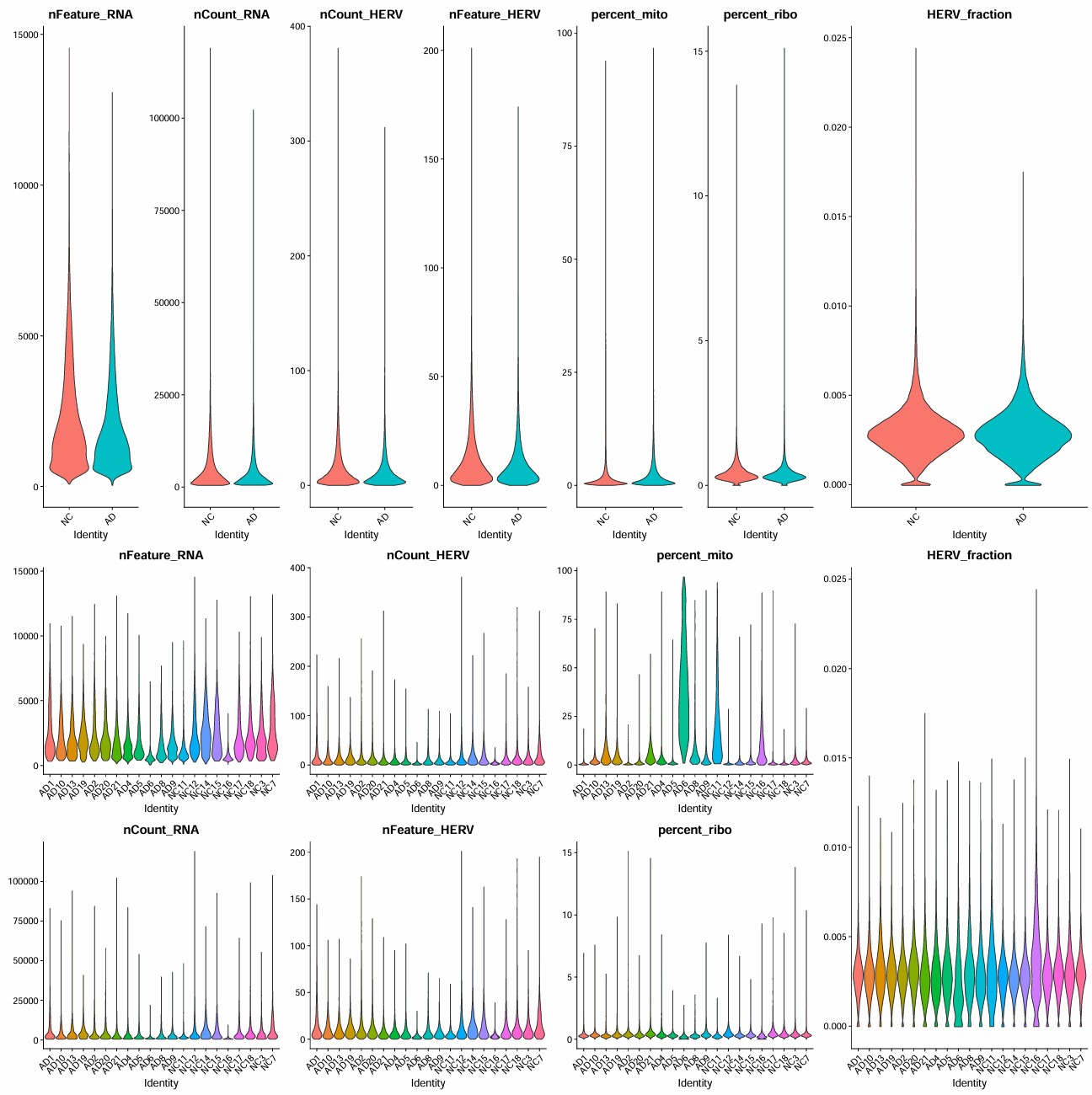
质控
过滤前:243200个细胞
> fivenum(filter(seu@meta.data, dataset=="GSE174367")$nFeature_RNA)
[1] 255 2065 2688 3642 15465
> fivenum(filter(seu@meta.data, dataset=="GSE174367")$nCount_RNA)
[1] 500.0 4697.0 7113.0 11324.5 227585.0
> fivenum(filter(seu@meta.data, dataset=="GSE174367")$percent_mito)
[1] 0.00000000 0.01251956 0.04296763 0.14577259 77.45019920
> fivenum(filter(seu@meta.data, dataset=="GSE174367")$percent_ribo)
[1] 0.0000000 0.1723774 0.2286834 0.3007169 10.2821317
> fivenum(filter(seu@meta.data, dataset=="GSE157827")$nFeature_RNA)
[1] 38 948 1618 2783 14543
> fivenum(filter(seu@meta.data, dataset=="GSE157827")$nCount_RNA)
[1] 450 1367 2697 5627 118970
> fivenum(filter(seu@meta.data, dataset=="GSE157827")$percent_mito)
[1] 0.0000000 0.4662729 1.0680017 2.6499303 96.6913580
> fivenum(filter(seu@meta.data, dataset=="GSE157827")$percent_ribo)
[1] 0.0000000 0.2367424 0.3400397 0.5042546 15.1050420
按细胞/基因阈值过滤后:229813个细胞+3.6w个基因
> scRNA_cells
An object of class Seurat
50657 features across 229813 samples within 2 assays
Active assay: RNA (35688 features, 0 variable features)
1 layer present: counts
1 other assay present: HERV
> table(scRNA_cells$dataset)
GSE157827 GSE174367
171377 58436
> table(scRNA_cells$group)
NC AD
101216 128597
> table(scRNA_cells$orig.ident)
100 17 19 22 27 33 37 43 45 46 47 50 52
4371 3612 2977 2607 3640 2589 3717 4570 4528 3229 2817 2599 2744
58 66 82 90 96 AD1 AD10 AD13 AD19 AD2 AD20 AD21 AD4
2633 2745 2344 2440 4274 6053 16292 1614 3699 15481 9382 8178 5776
AD5 AD6 AD8 AD9 NC11 NC12 NC14 NC15 NC16 NC17 NC18 NC3 NC7
12595 420 2416 9806 1704 15546 10883 8448 4501 14320 11666 6328 6269
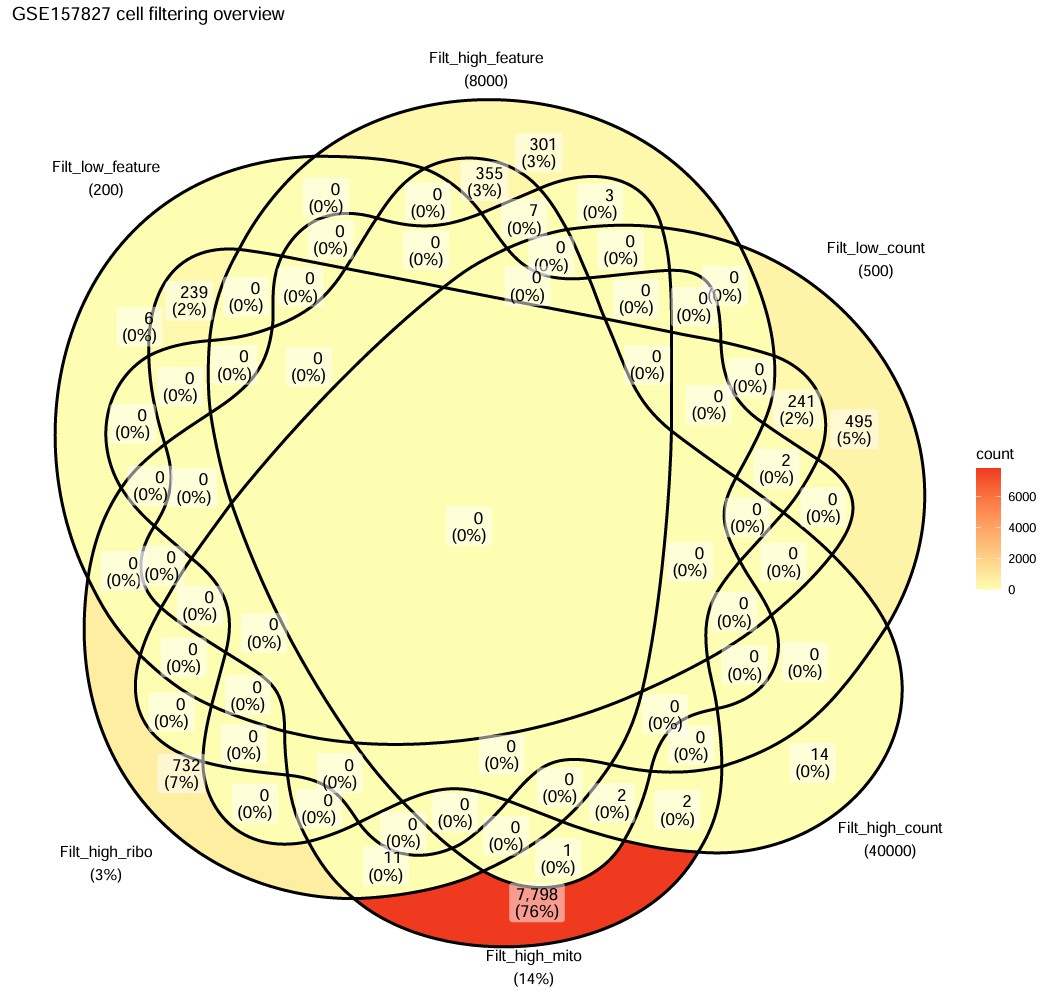
- GSE157827主要是依据线粒体比例过高过滤的
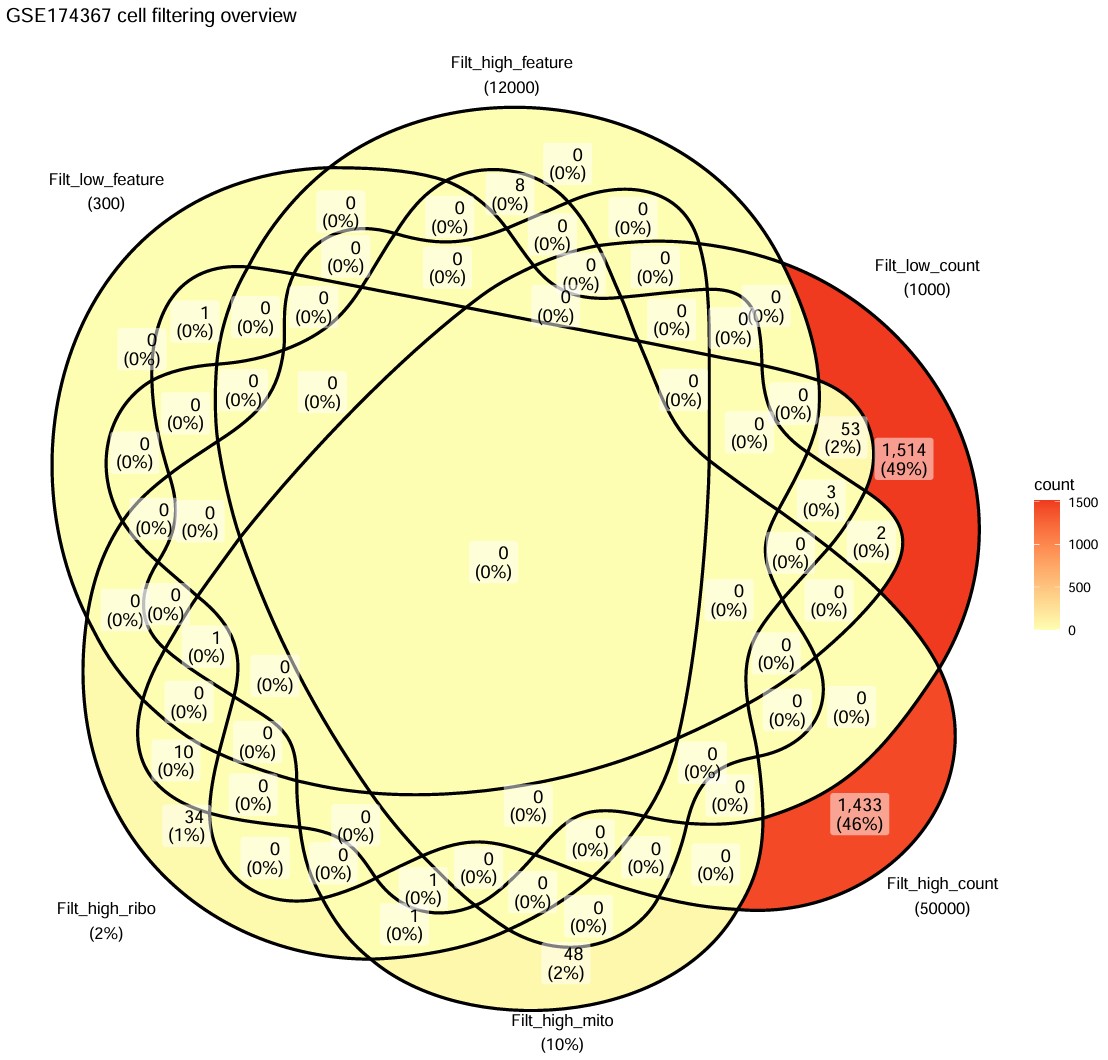
- GSE174367主要是依据nCount_RNA过滤的,且过滤的细胞较少
过滤双细胞后:207009个细胞
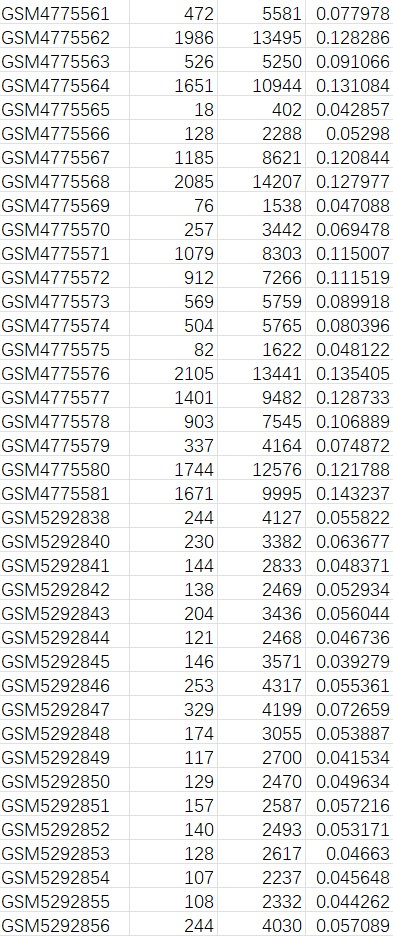
GSM477xxx是GSE157827的样本,双细胞比例较高(大多数在7%-13%)GSM529xxx是GSE174367的样本,双细胞比例较低(大多数在5%左右),与前面的Venn图对应,说明测序质量较好
> seu_filt
An object of class Seurat
50657 features across 207009 samples within 2 assays
Active assay: RNA (35688 features, 0 variable features)
1 layer present: counts
1 other assay present: HERV
> table(seu_filt$dataset)
GSE157827 GSE174367
151686 55323
> table(seu_filt$group)
NC AD
90772 116237
> table(seu_filt$orig.ident)
100 17 19 22 27 33 37 43 45 46 47 50 52
4127 3382 2833 2469 3436 2468 3571 4317 4199 3055 2700 2470 2587
58 66 82 90 96 AD1 AD10 AD13 AD19 AD2 AD20 AD21 AD4
2493 2617 2237 2332 4030 5581 14207 1538 3442 13495 8303 7266 5250
AD5 AD6 AD8 AD9 NC11 NC12 NC14 NC15 NC16 NC17 NC18 NC3 NC7
10944 402 2288 8621 1622 13441 9482 7545 4164 12576 9995 5759 5765
数据预处理+去批次效应
使用harmony去批次效应
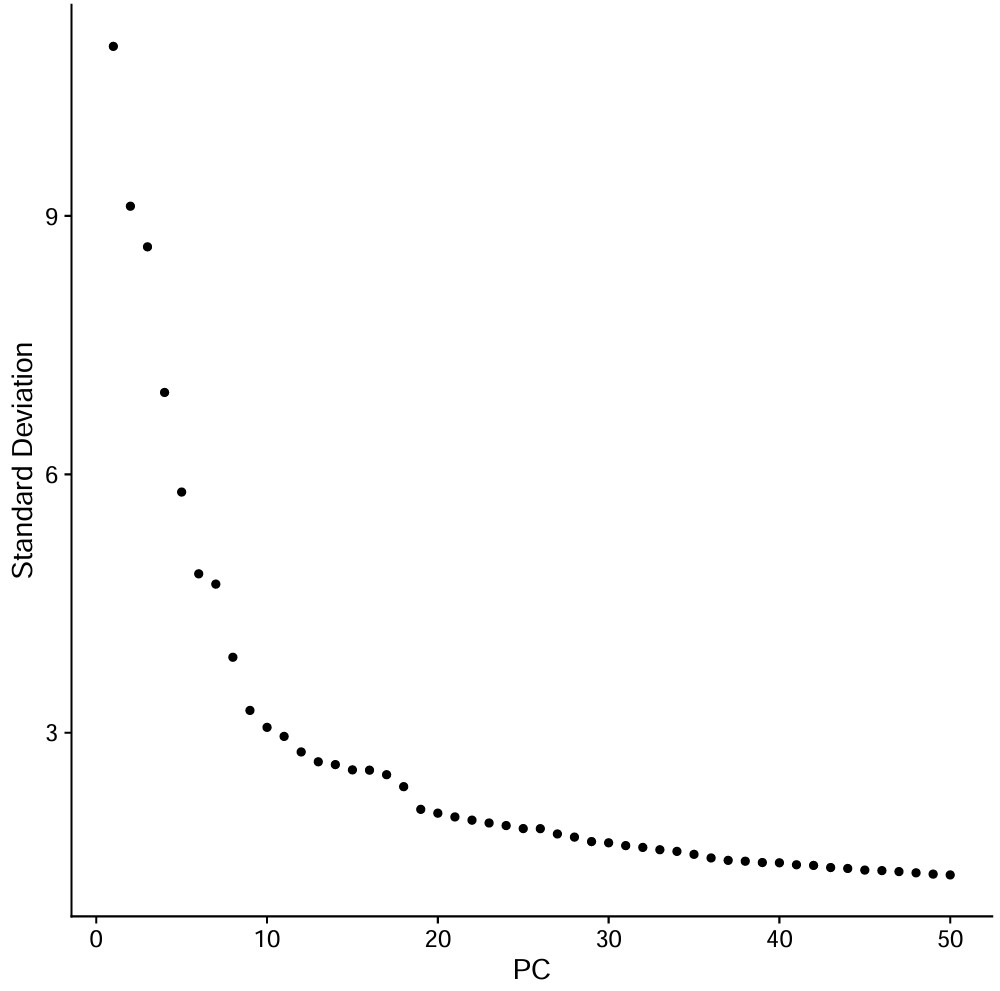
选前30个pc
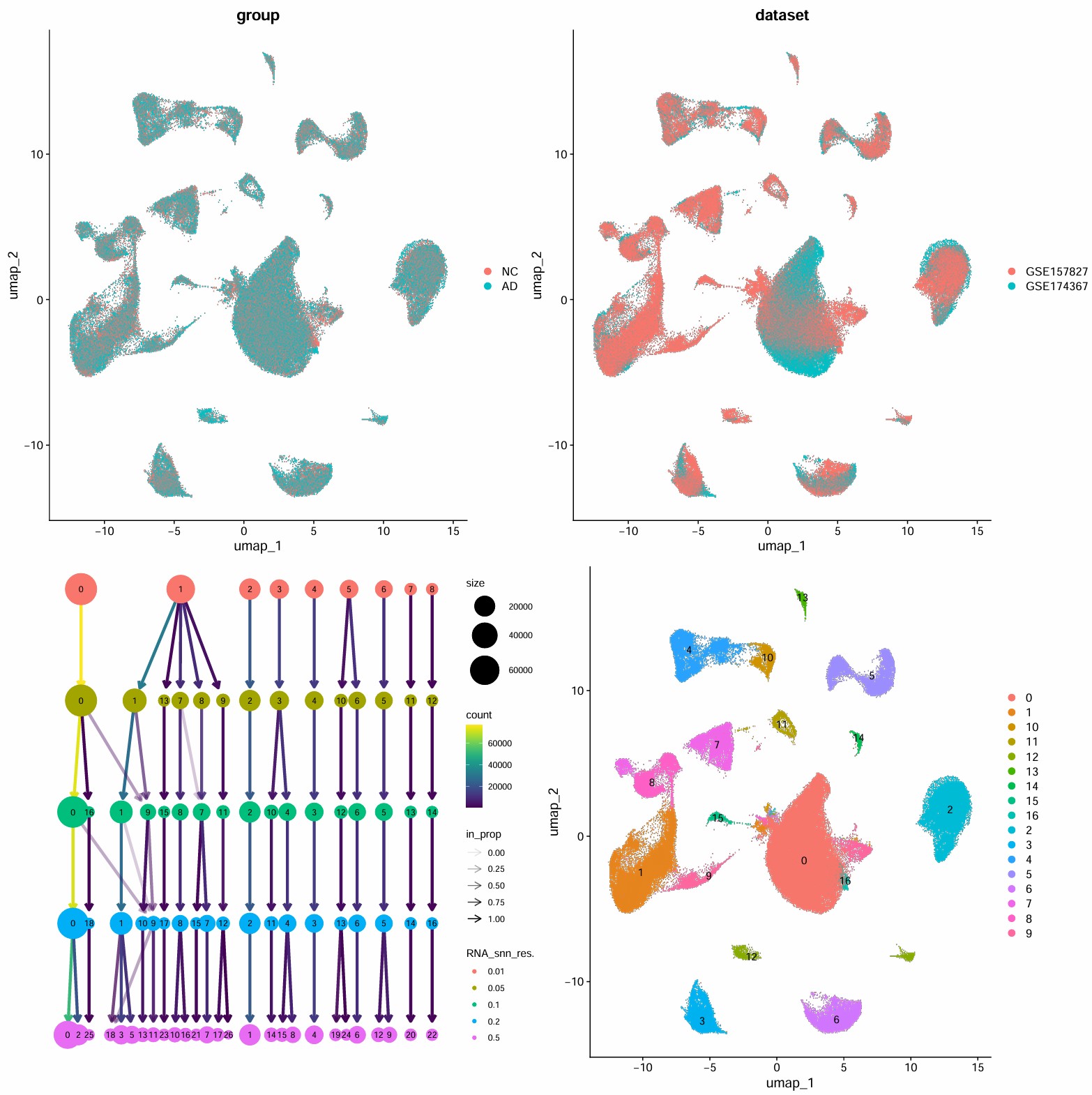
分辨率设置为0.1
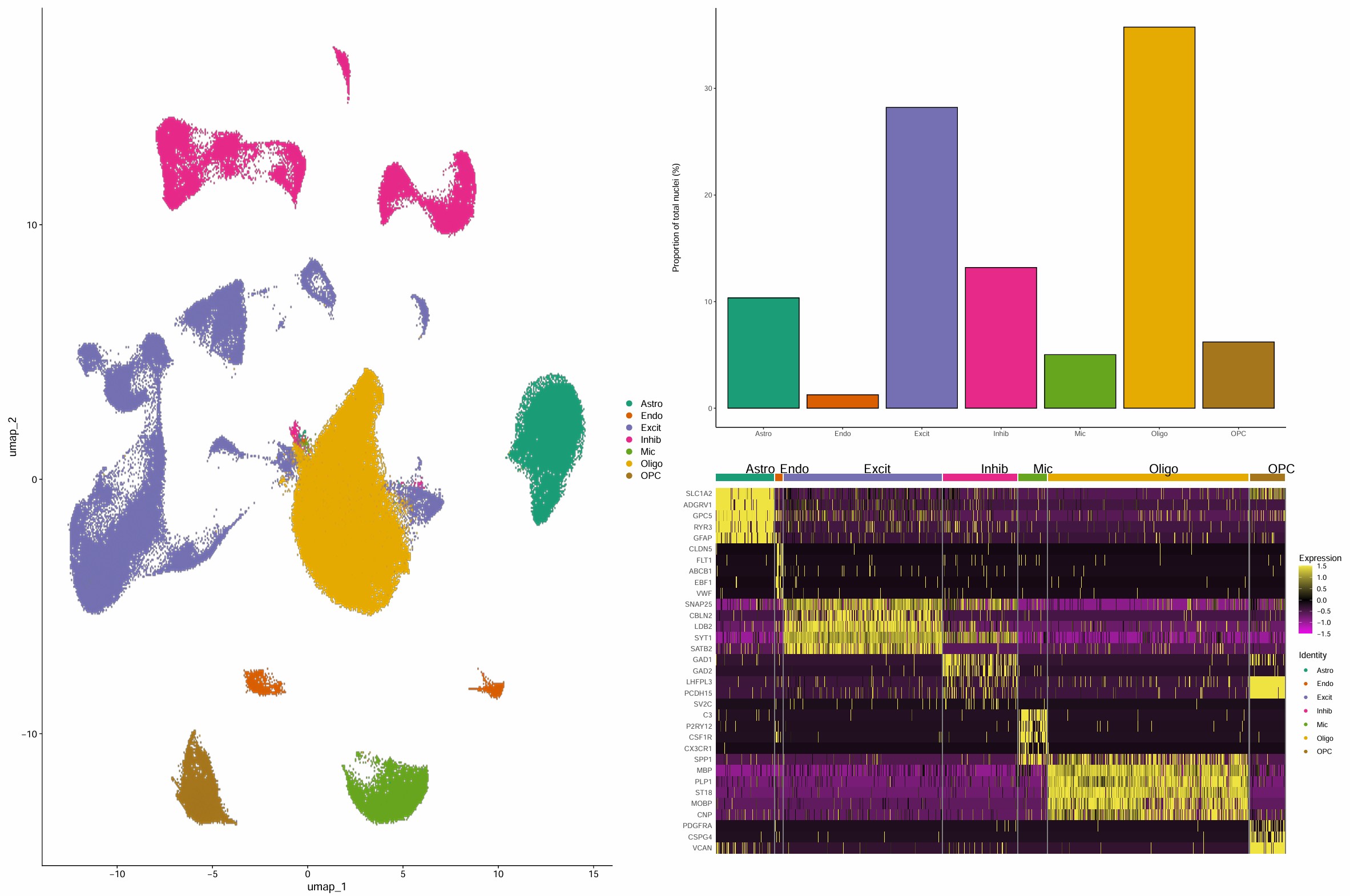
细胞类型注释
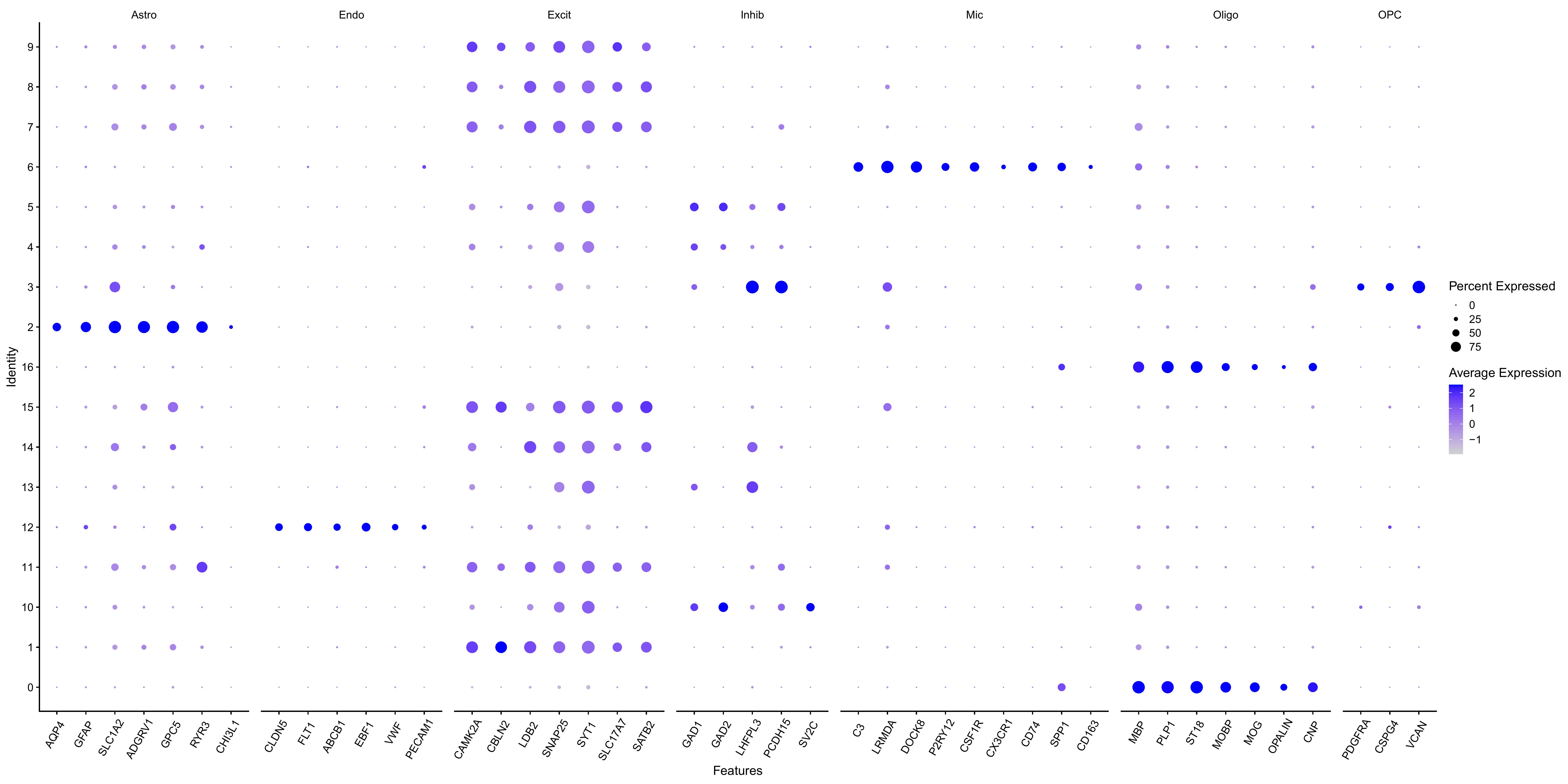
- astro:2
- endo:12
- mic:6
- oligo:0、16
- OPC:3
- inhib:4、5、10、13
- excit:1、7、8、9、11、14、15
> table(seu$celltype, seu$group)
NC AD
Astro 9388 12032
Endo 732 1884
Excit 26896 31494
Inhib 12254 15060
Mic 4346 6060
Oligo 31245 42753
OPC 5911 6954
> table(seu$celltype)
Astro Endo Excit Inhib Mic Oligo OPC
21420 2616 58390 27314 10406 73998 12865
hERV位点-家族映射
hERV总量/class重调情况
全体细胞
所有细胞:

GSE174367:

GSE157827:

scTE:

各细胞类型
所有细胞:
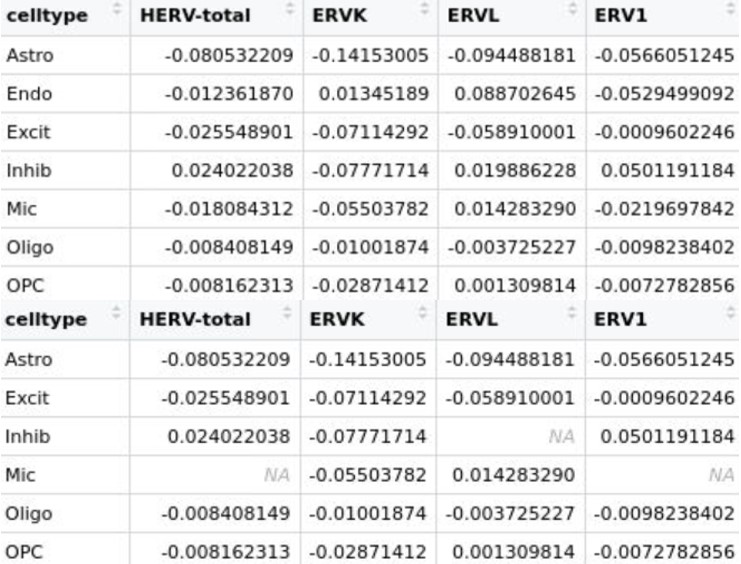
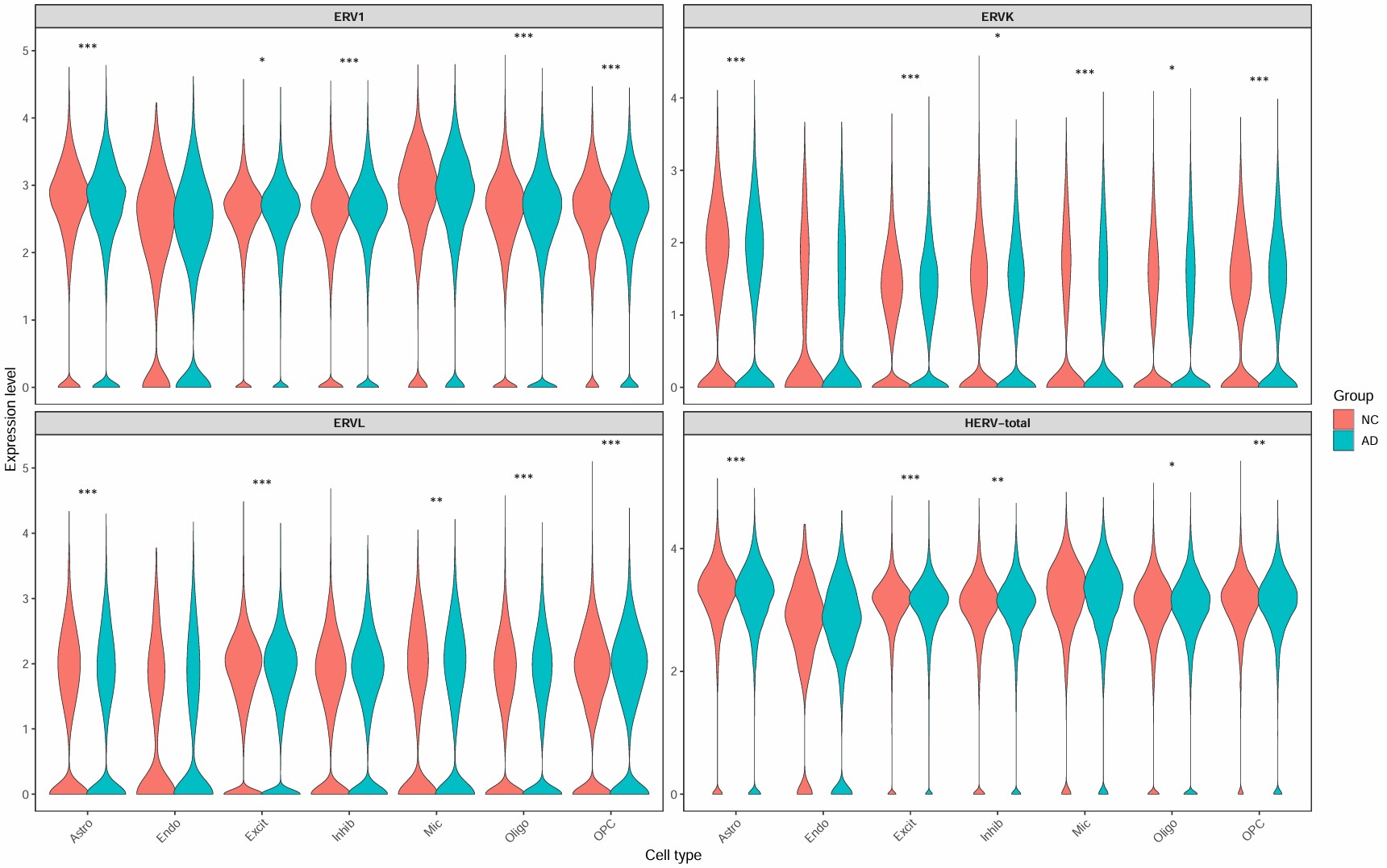
GSE174367:
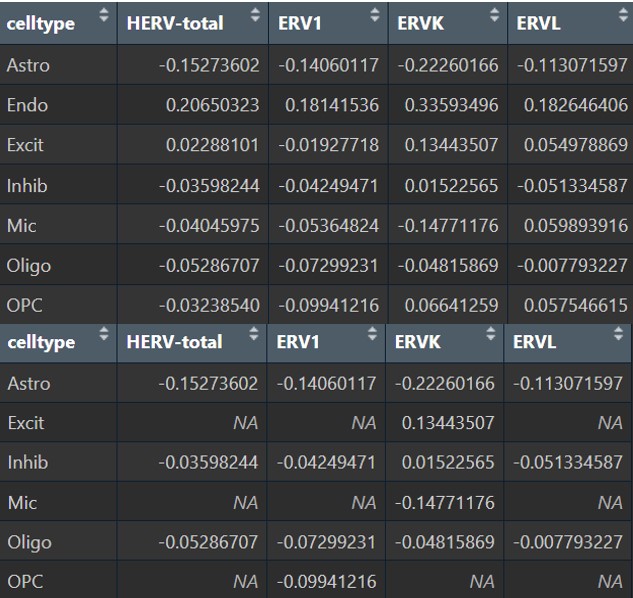
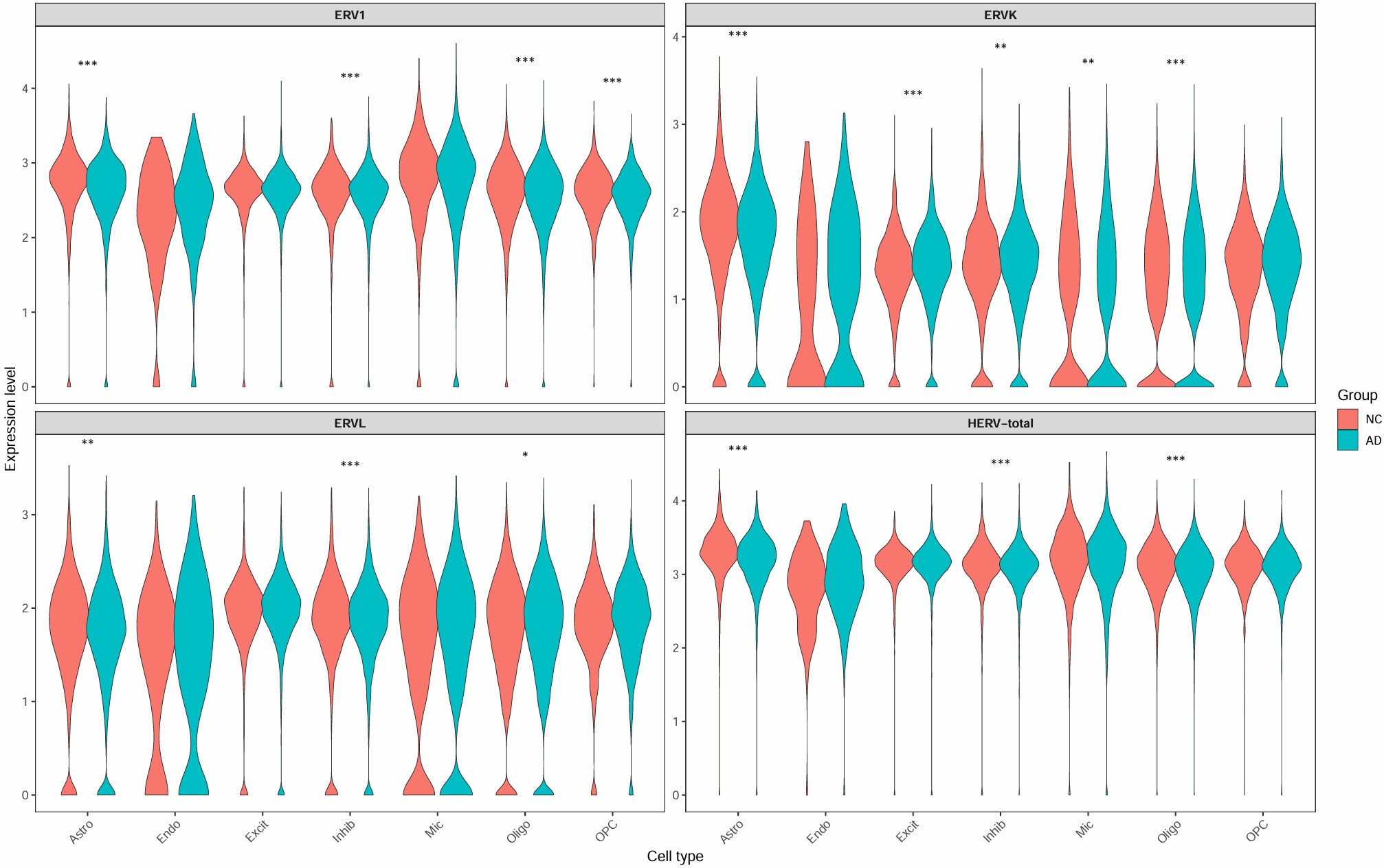
GSE157827:
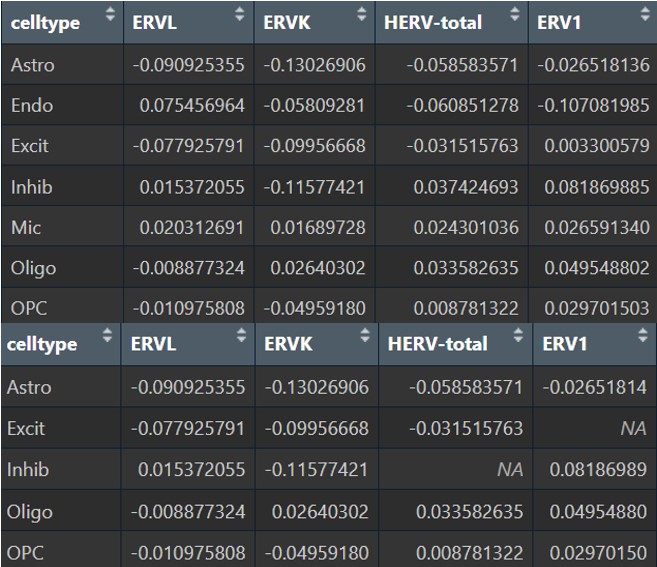
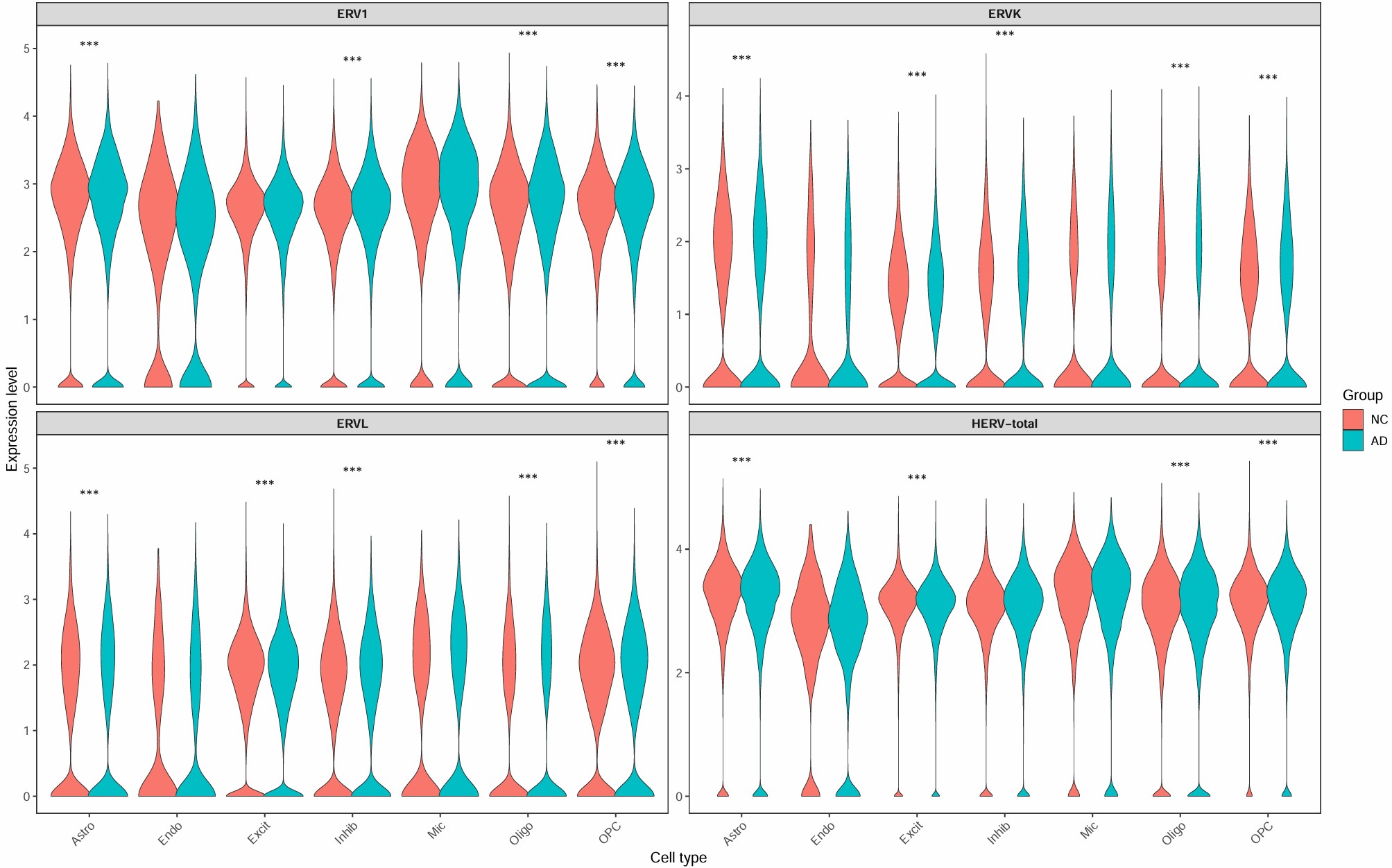
scTE:
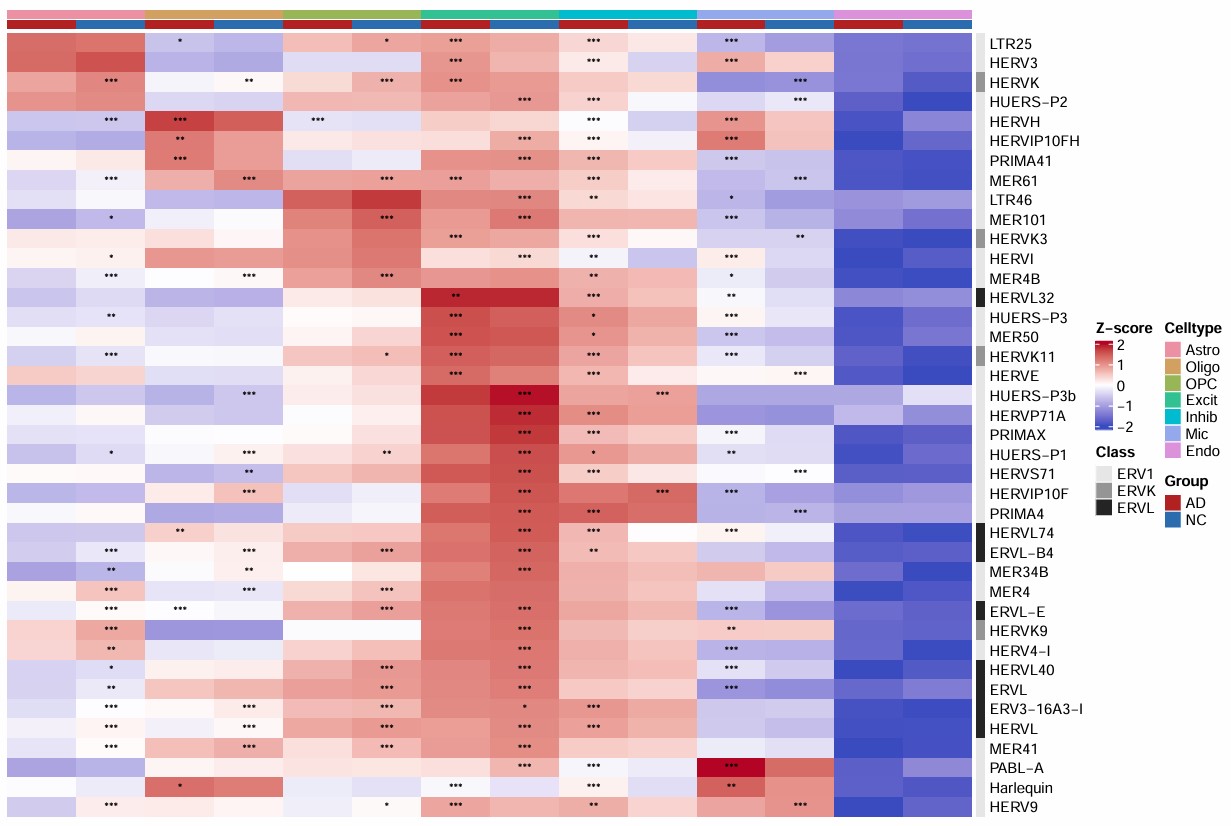
细胞大类中的hERV家族重调情况
所有细胞:
GSE174367:
GSE157827:
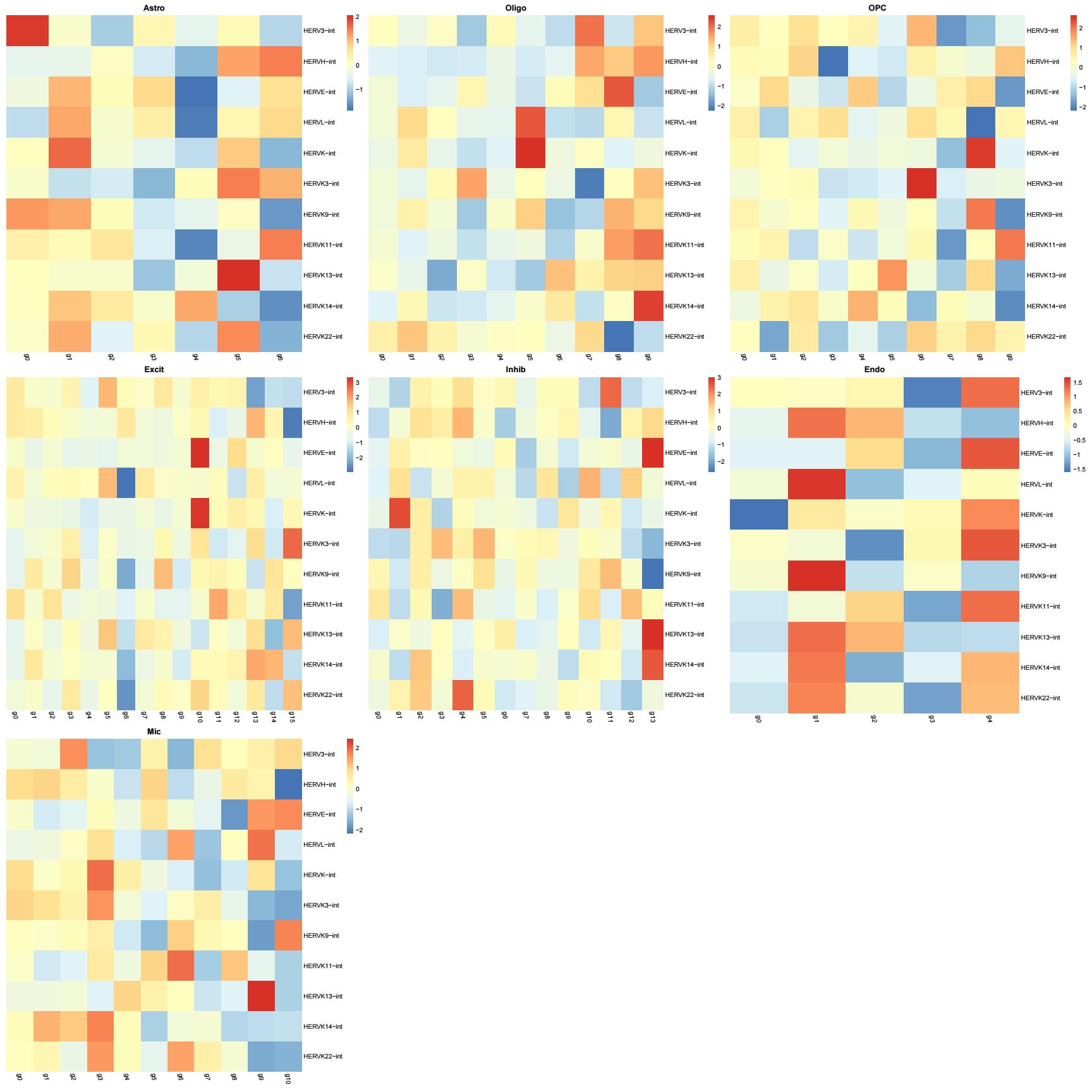
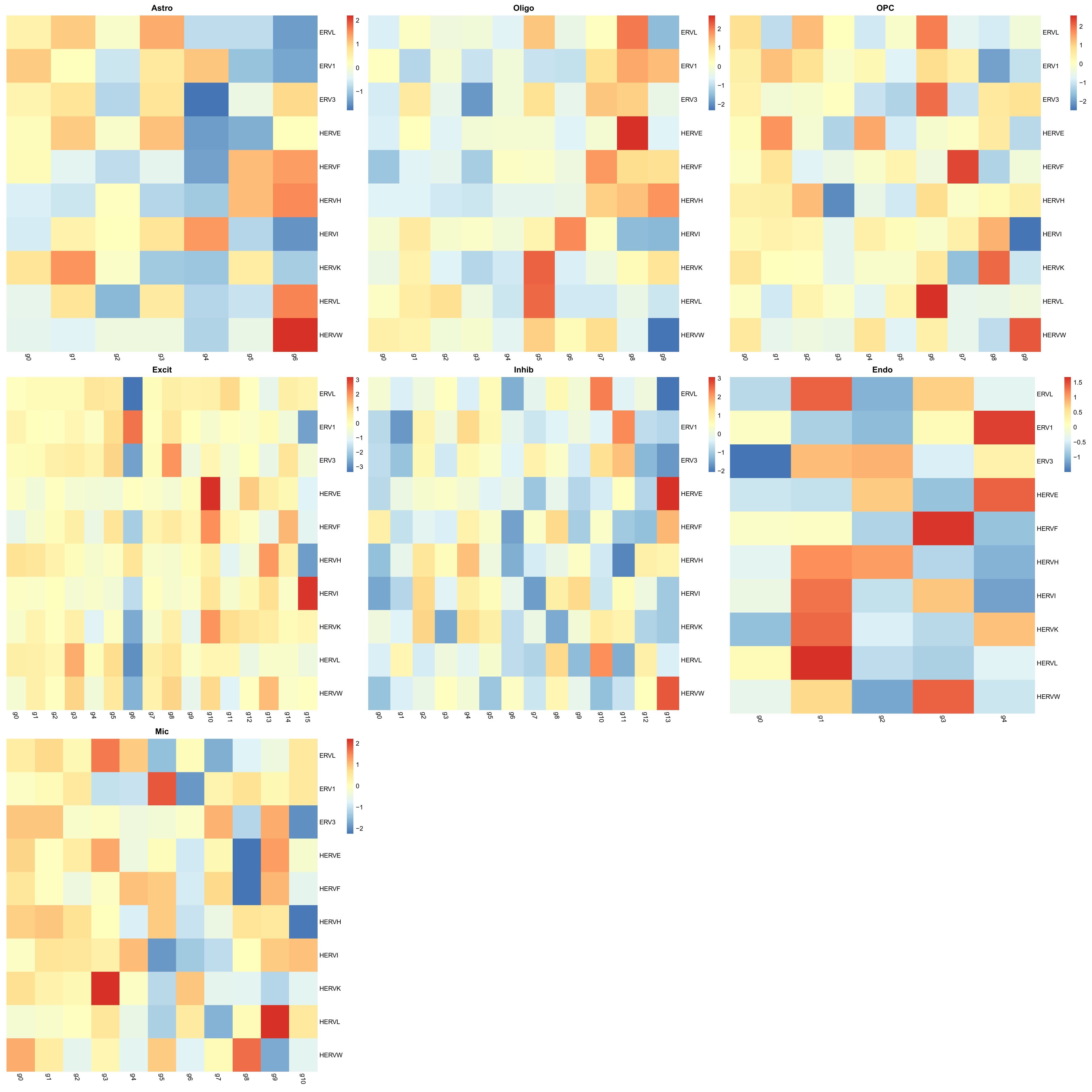
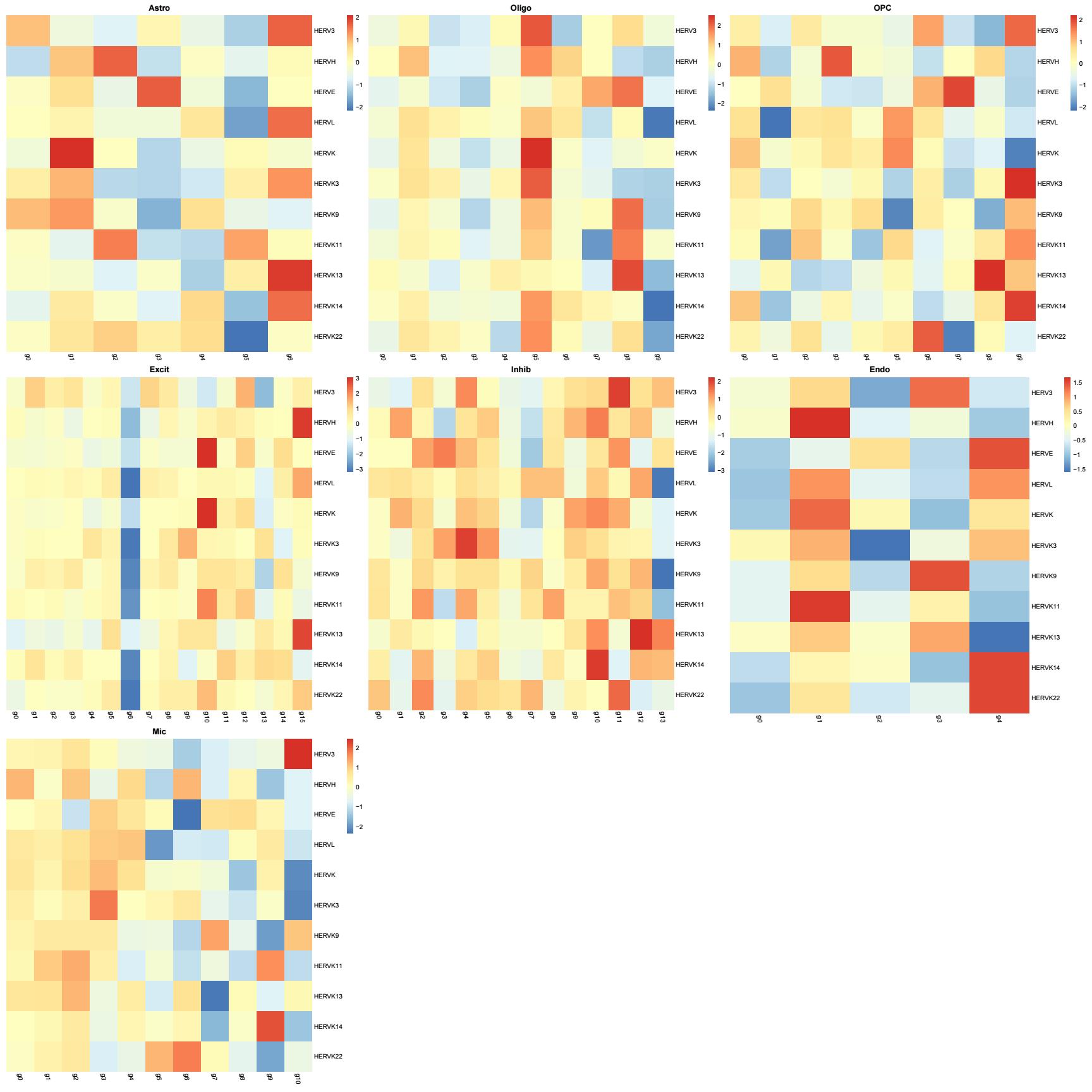
细胞亚群中的hERV家族表达情况
family:
group:
family_scTE:
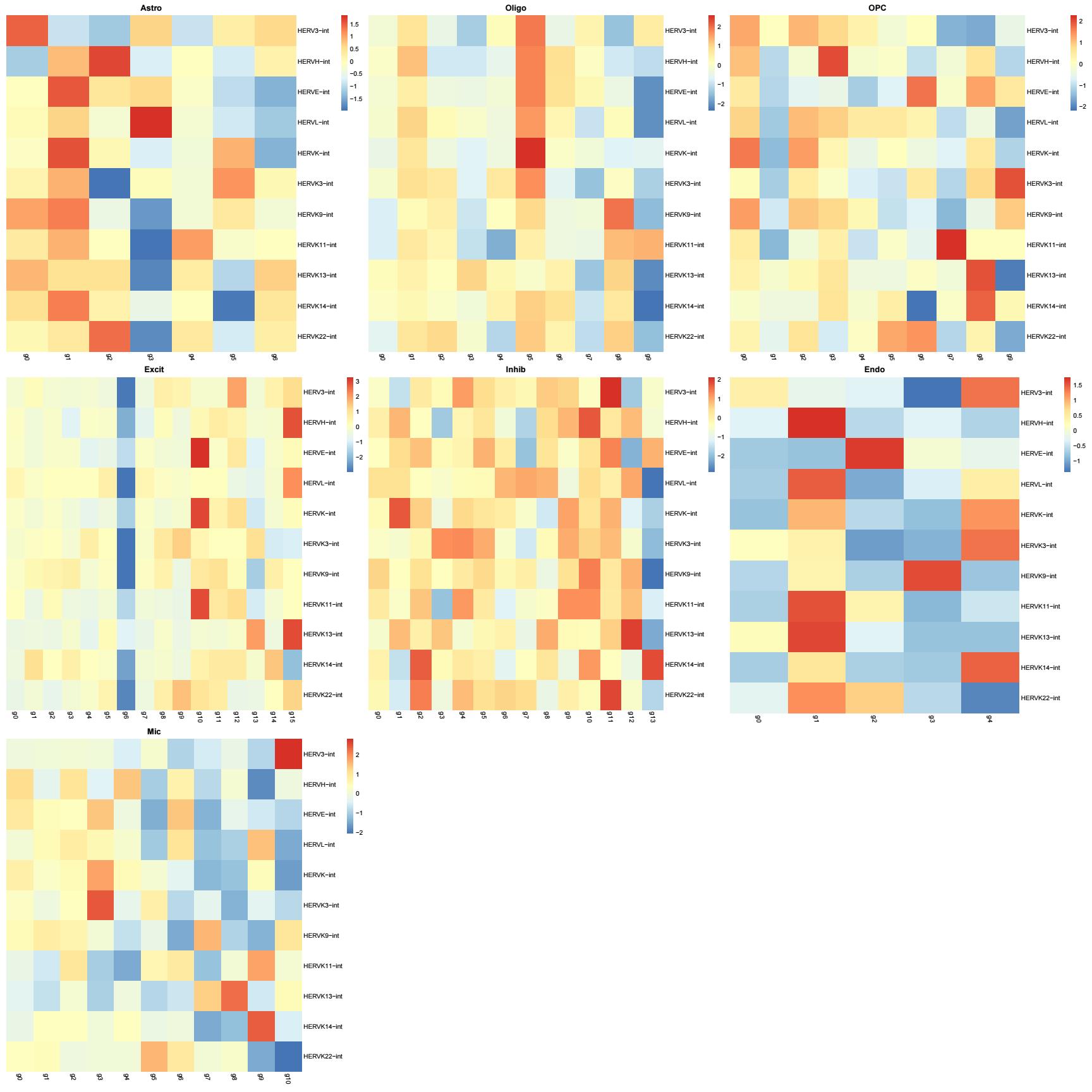
family_LTR_scTE:
hERV-gene共表达网络
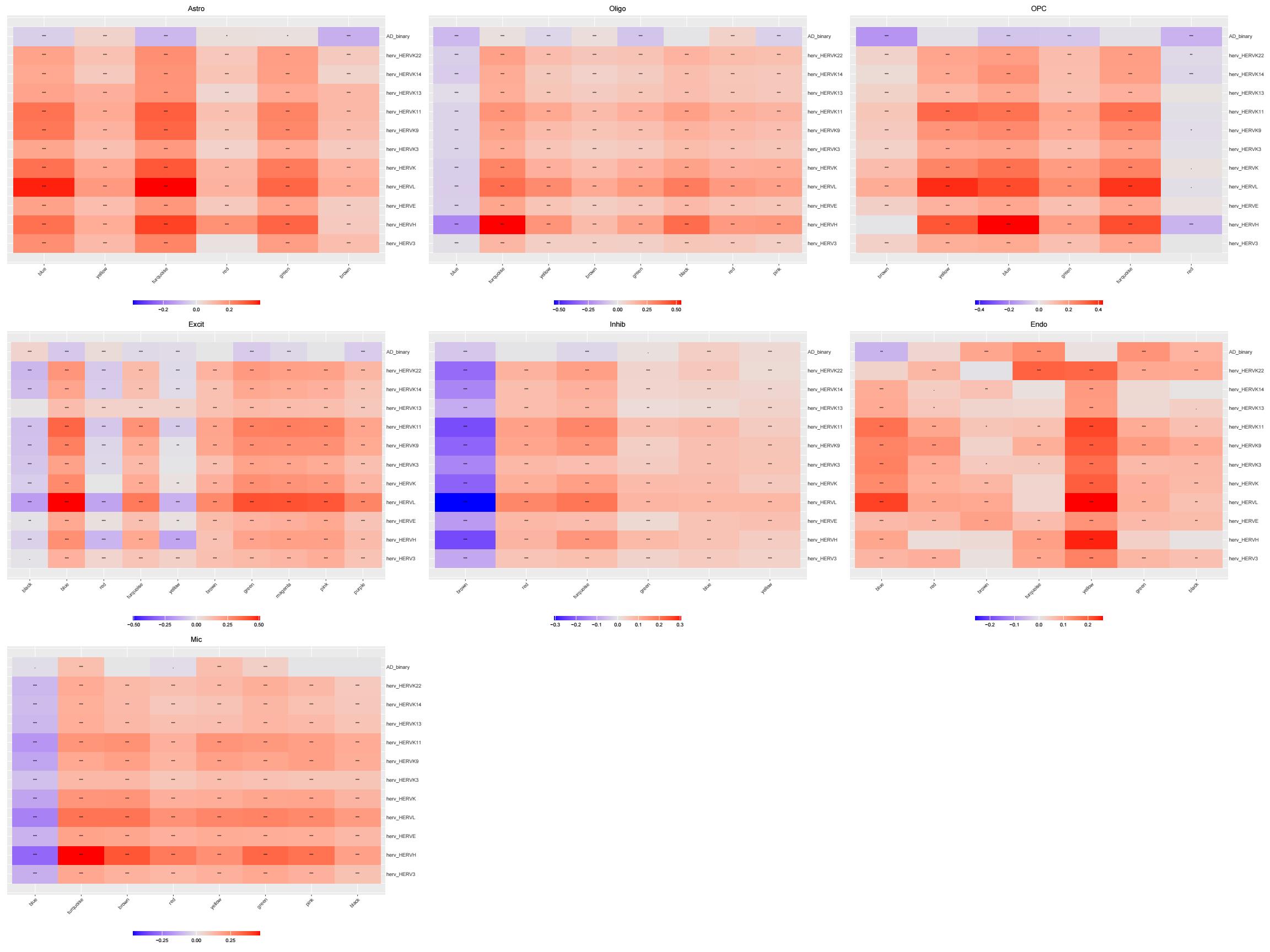
各细胞类型的gene共表达网络与hERV的相关性
family:
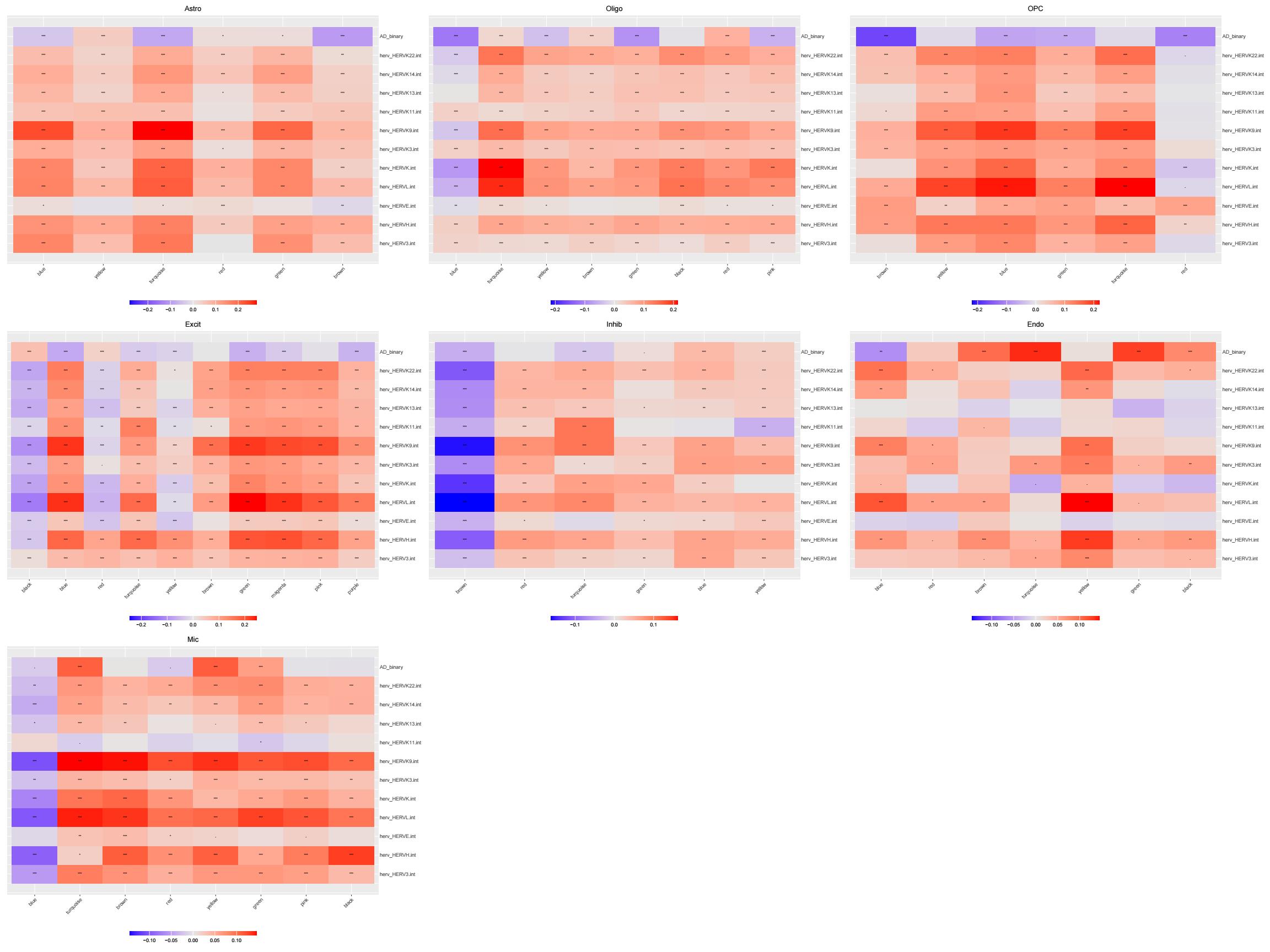
group:
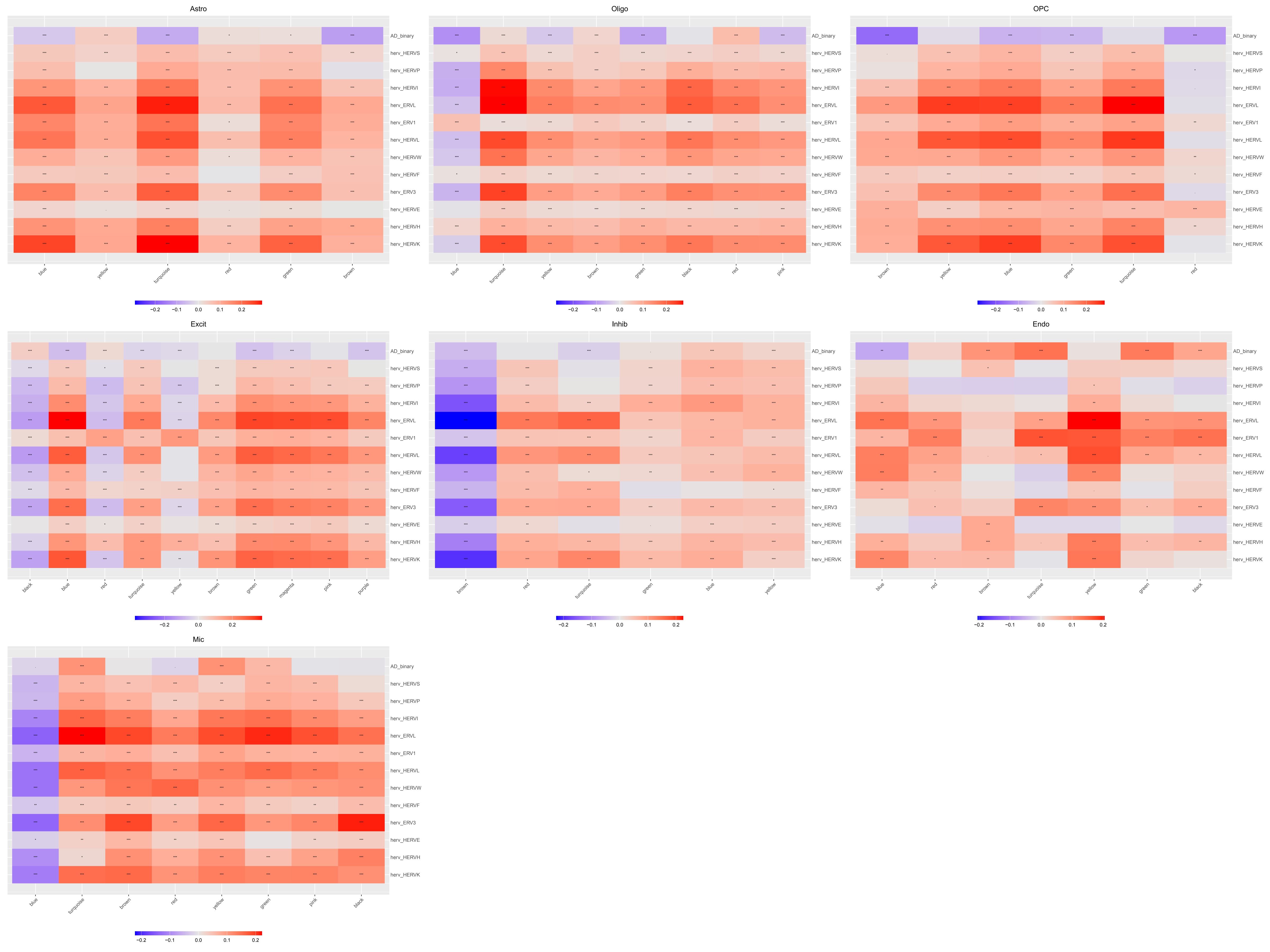
family_scTE:
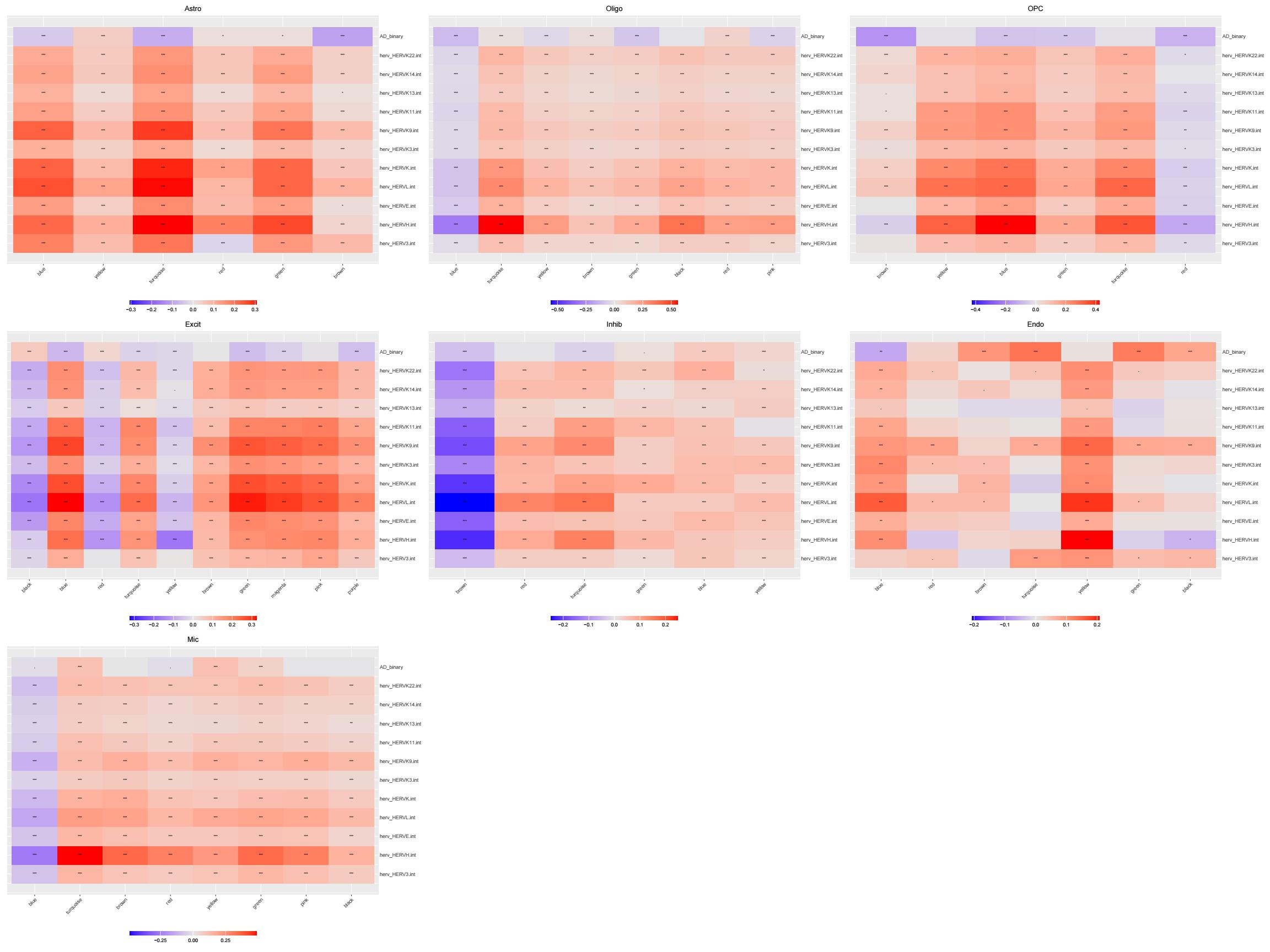
family_LTR_scTE:
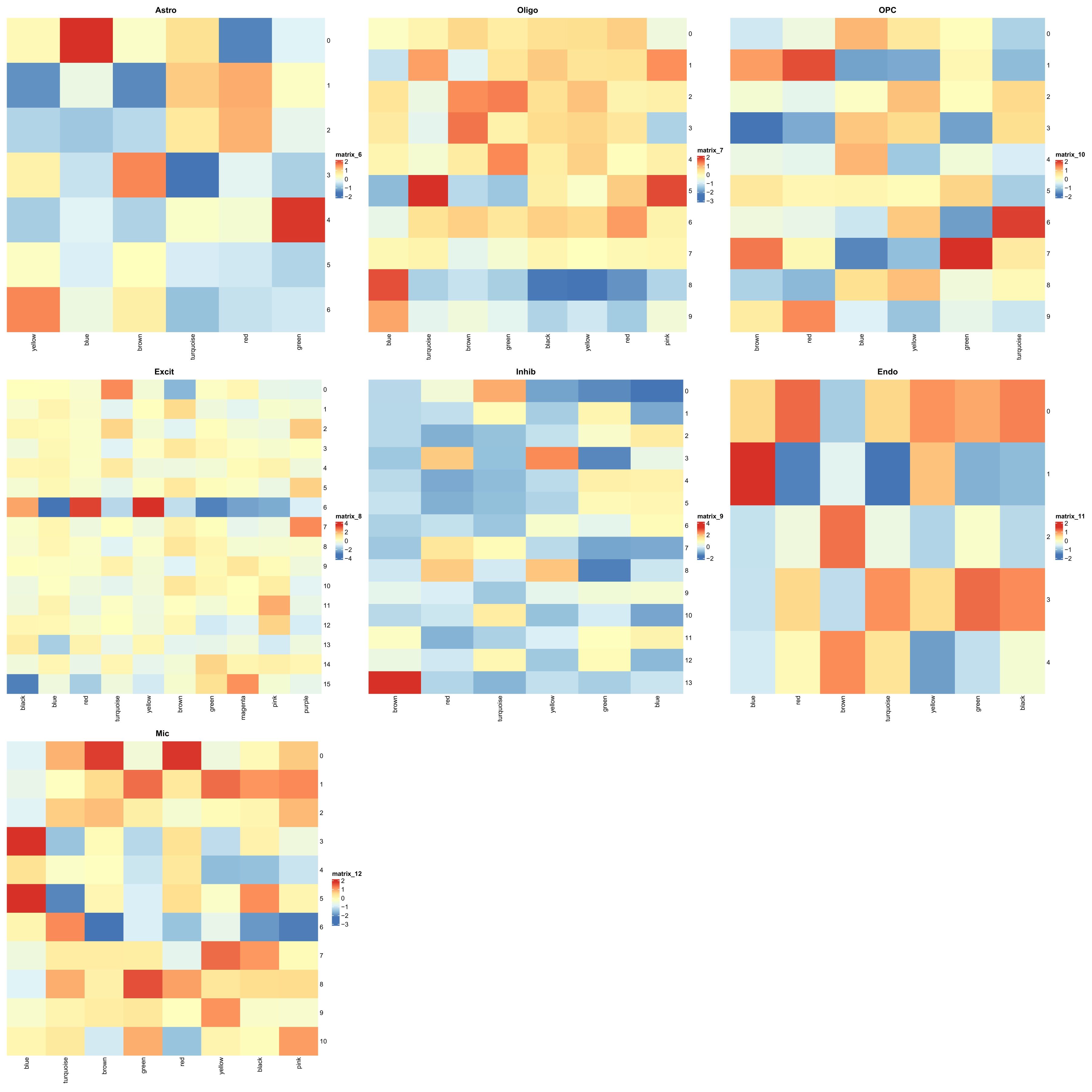
各细胞类型的模块分数
注:这里使用hERV group和family的RData都一样,因为这个只影响hERV~gene的相关性,它们的模块都是一样的(下同)
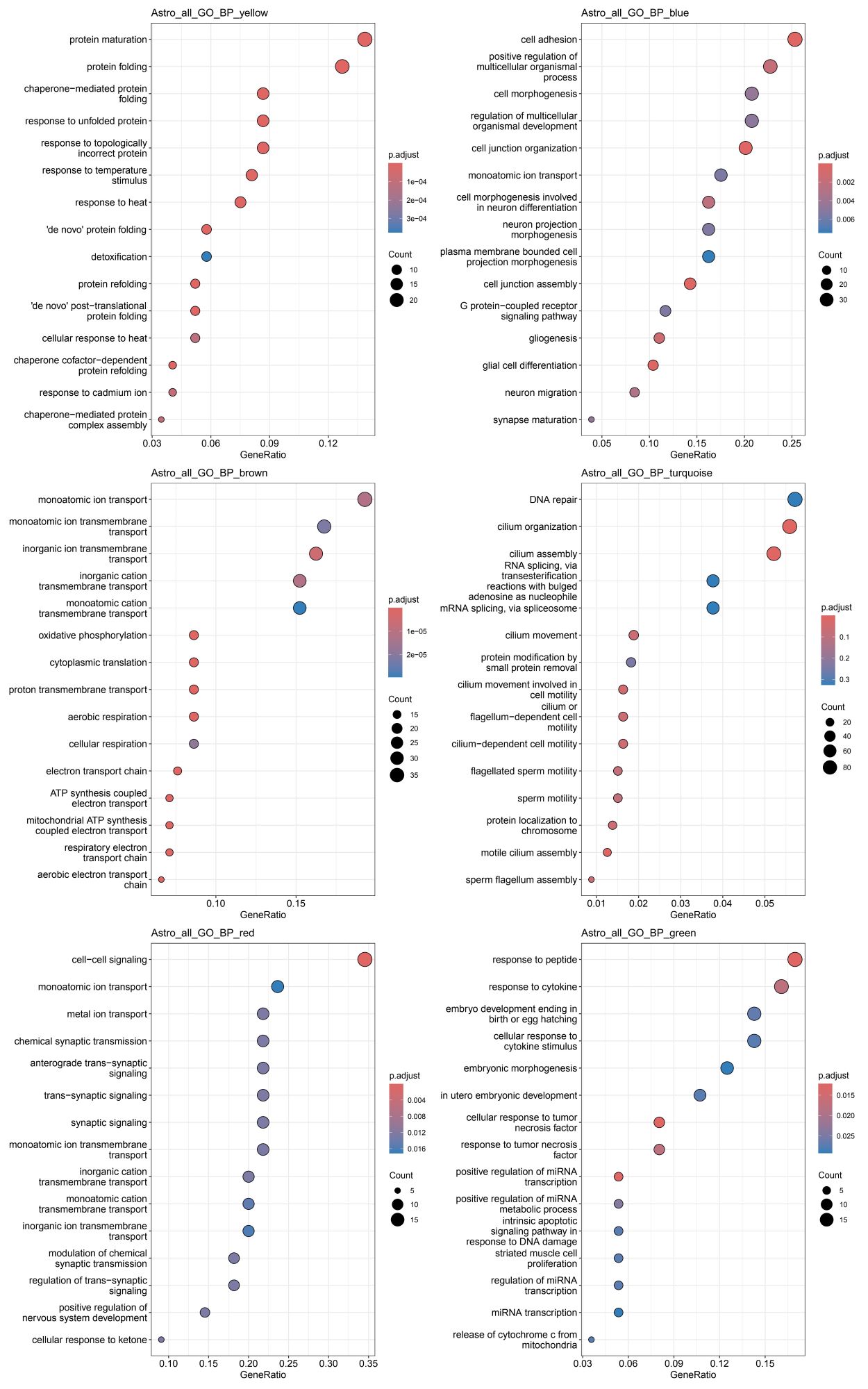
各细胞类型的各模块GO结果
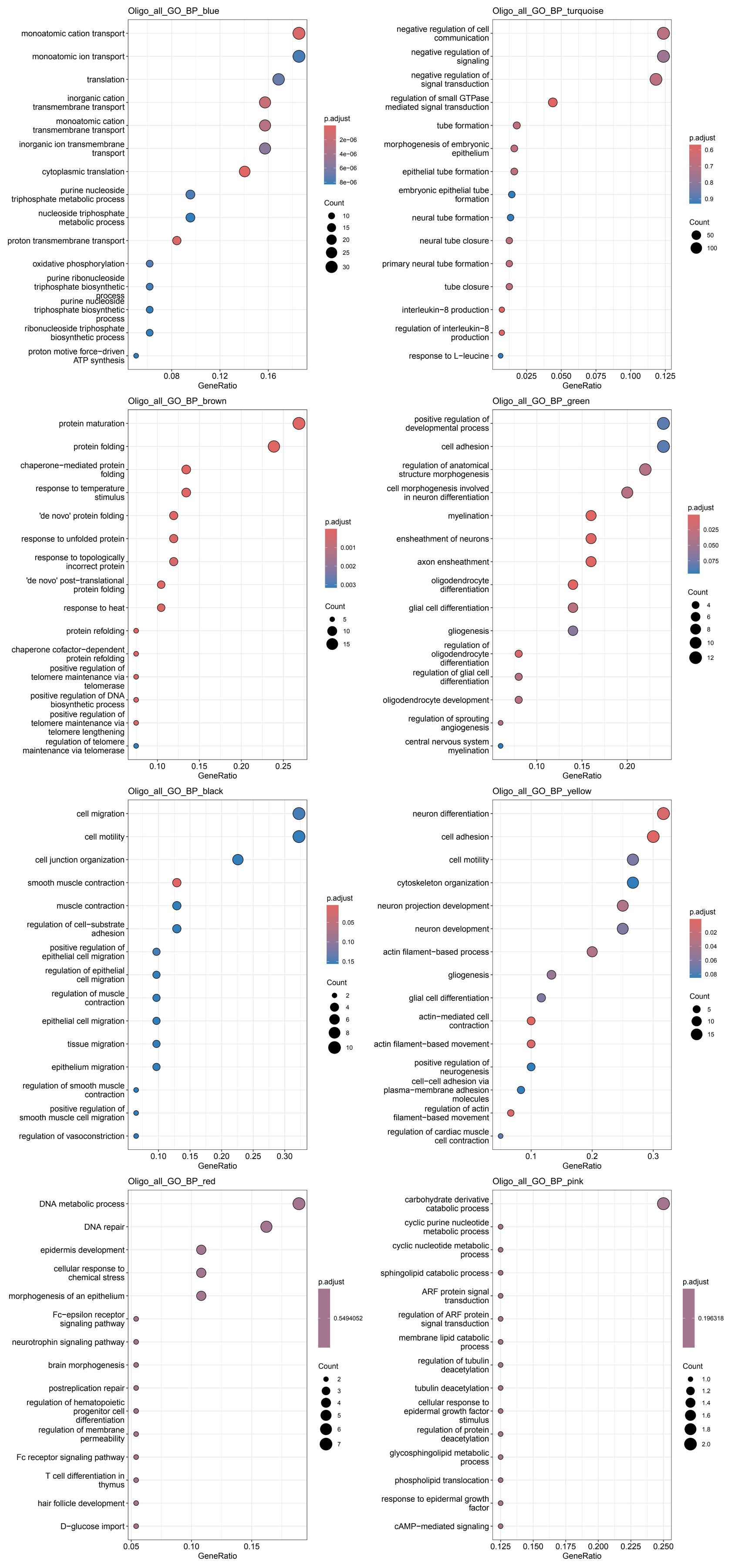
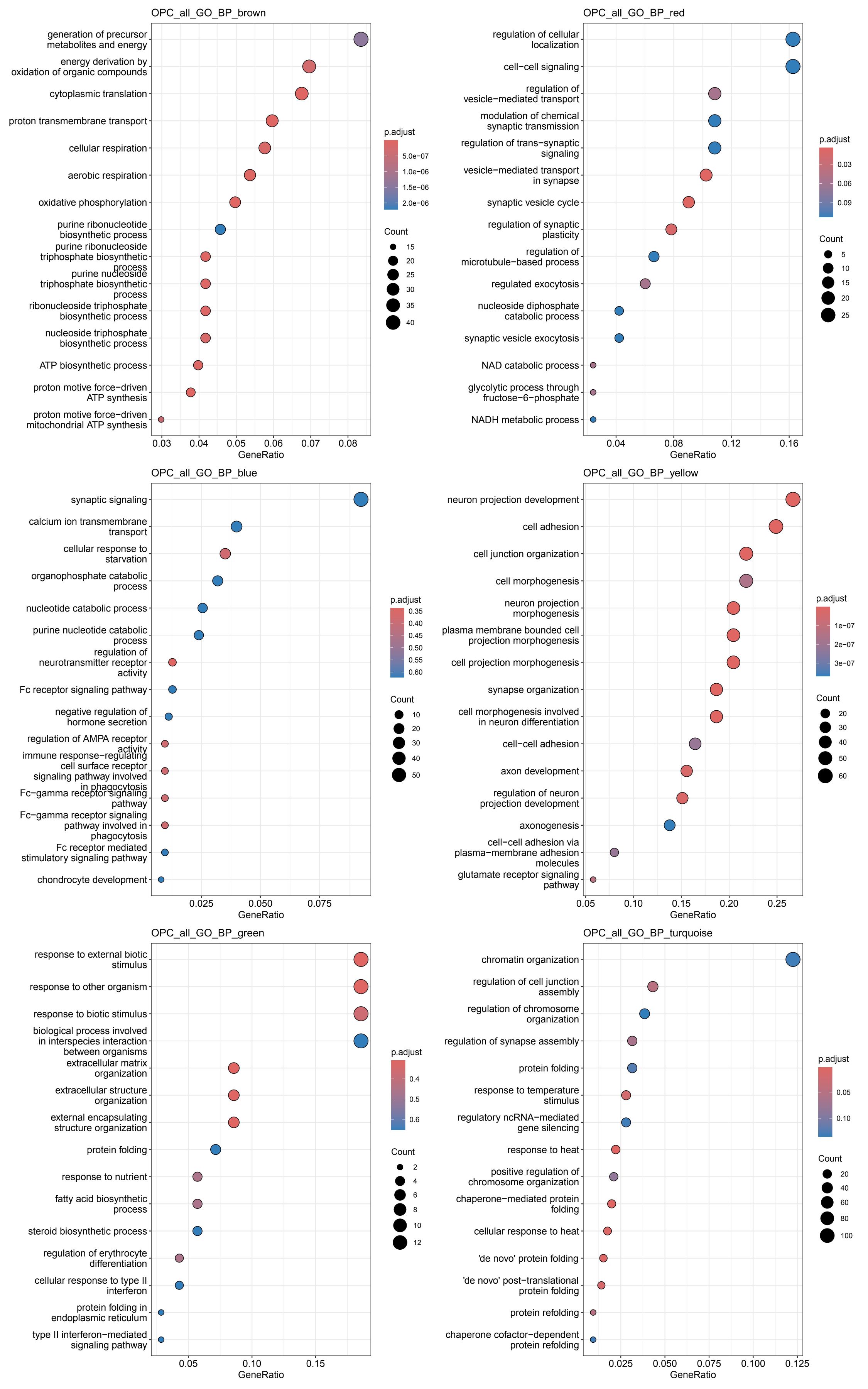
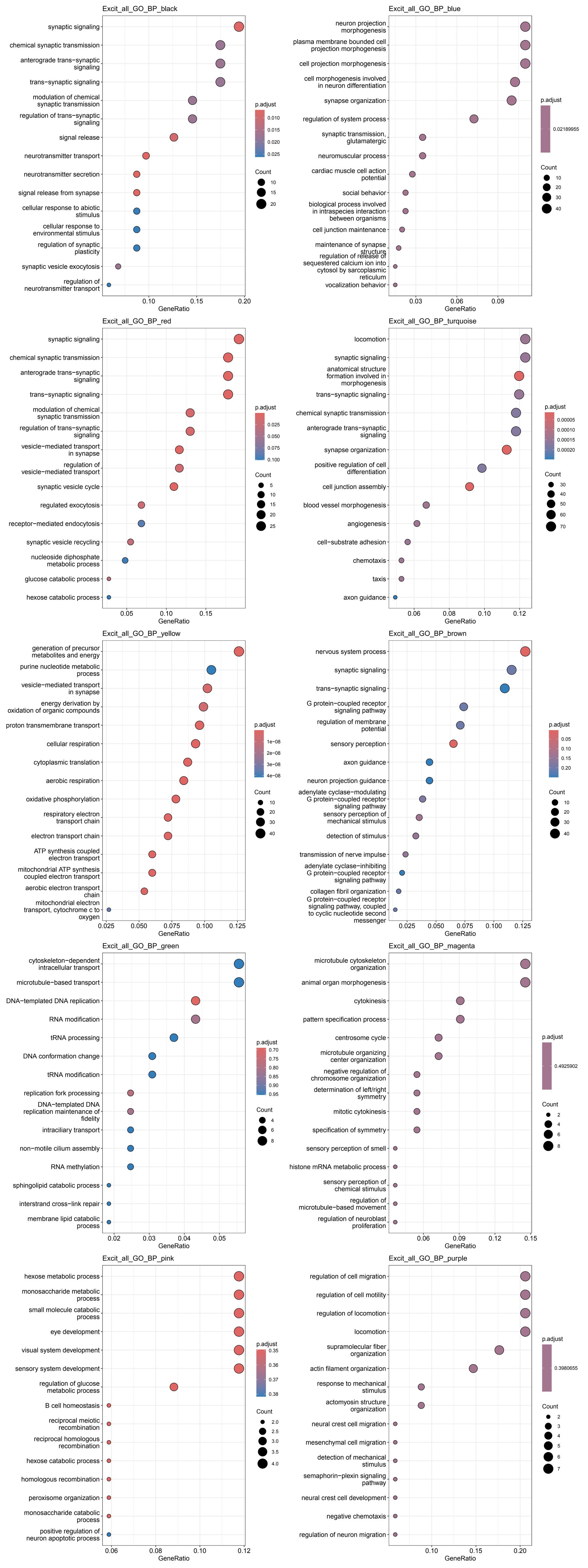
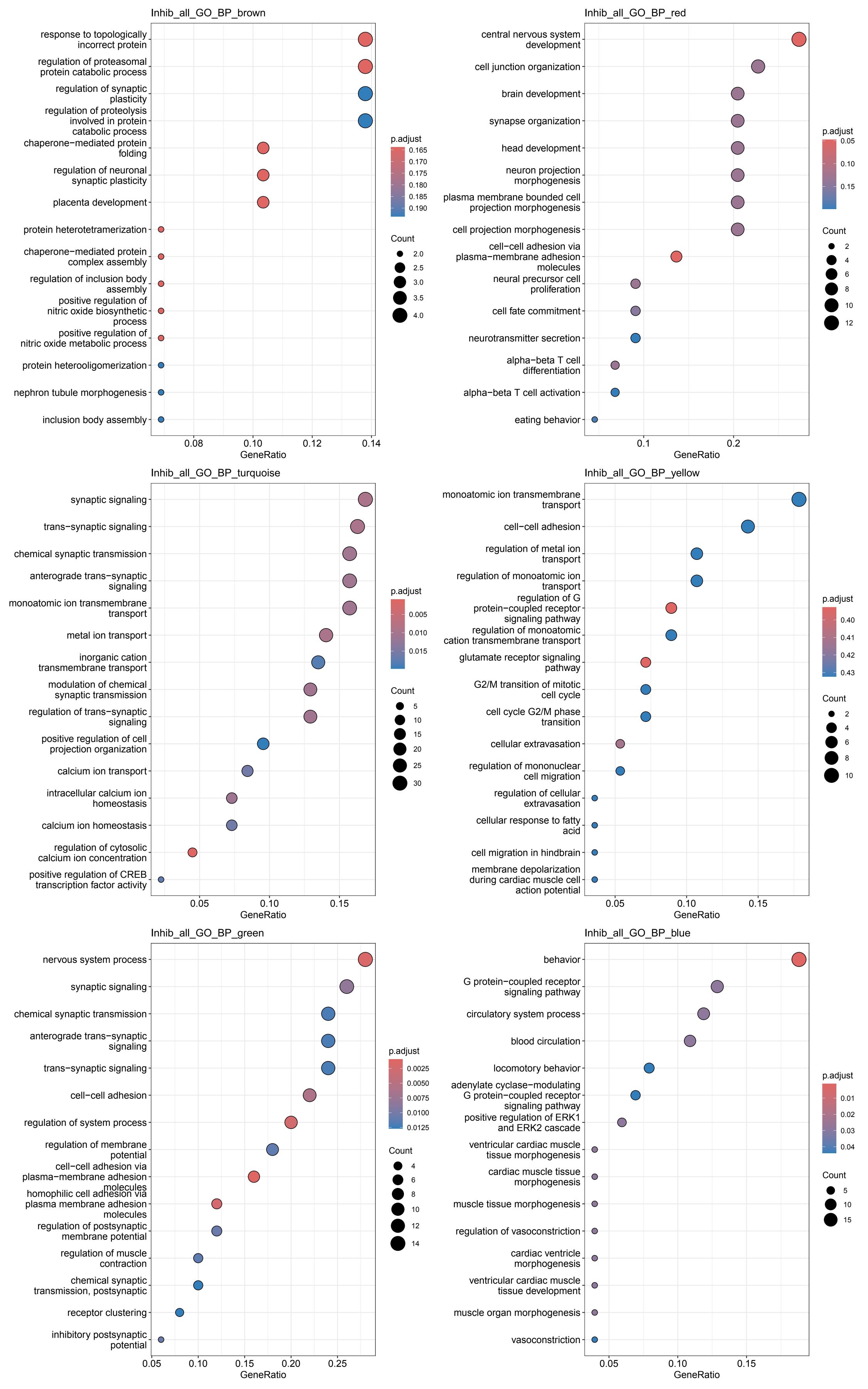
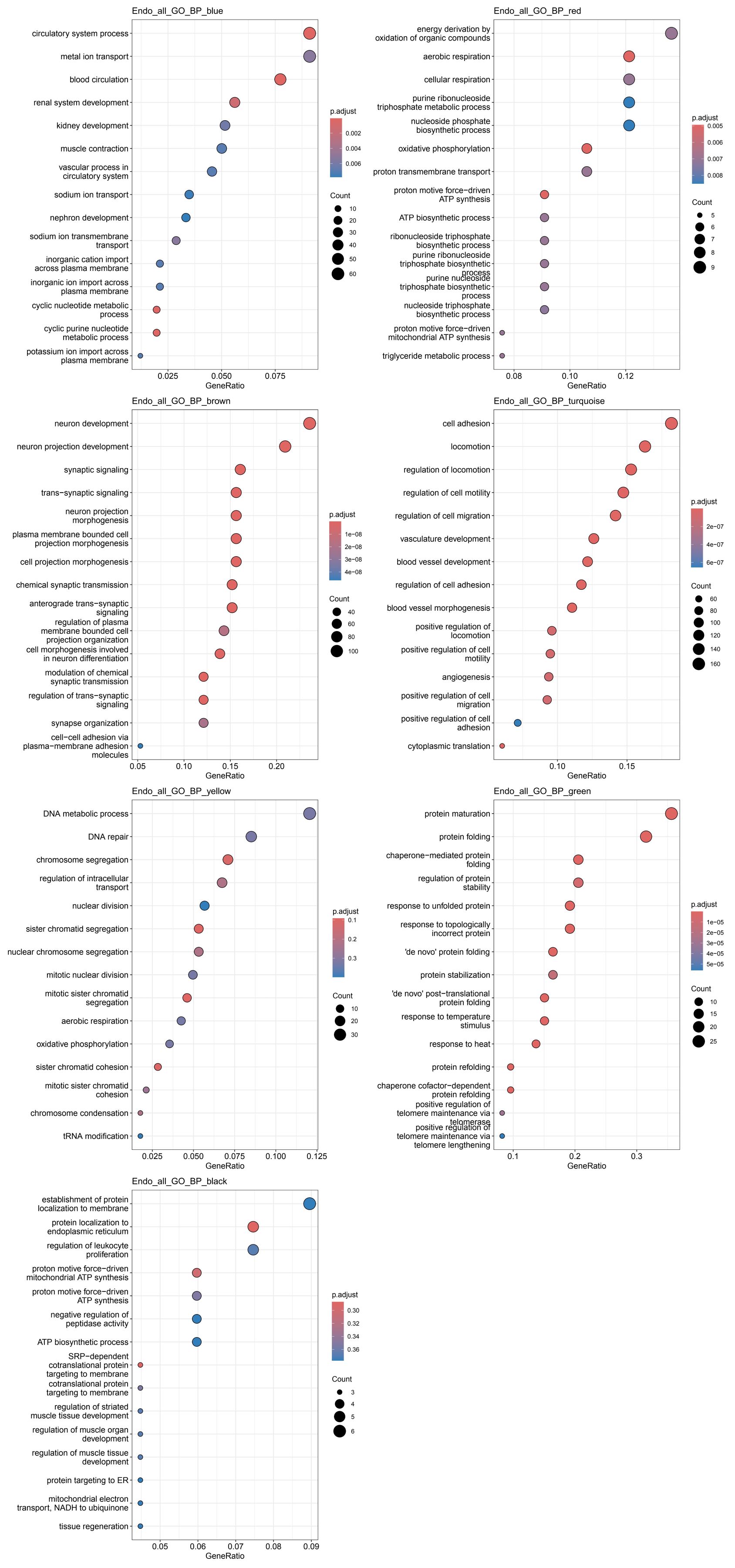
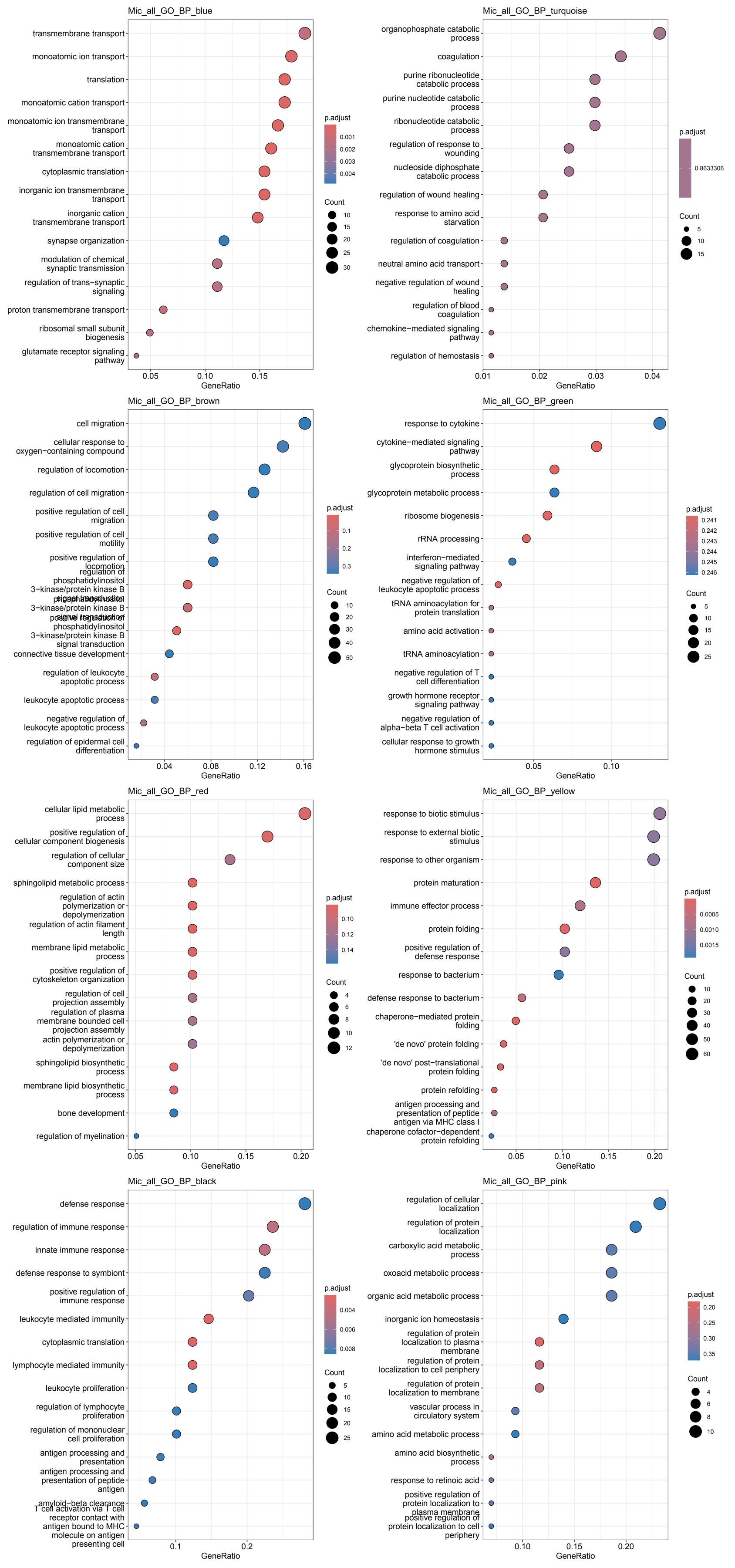
其它结果图
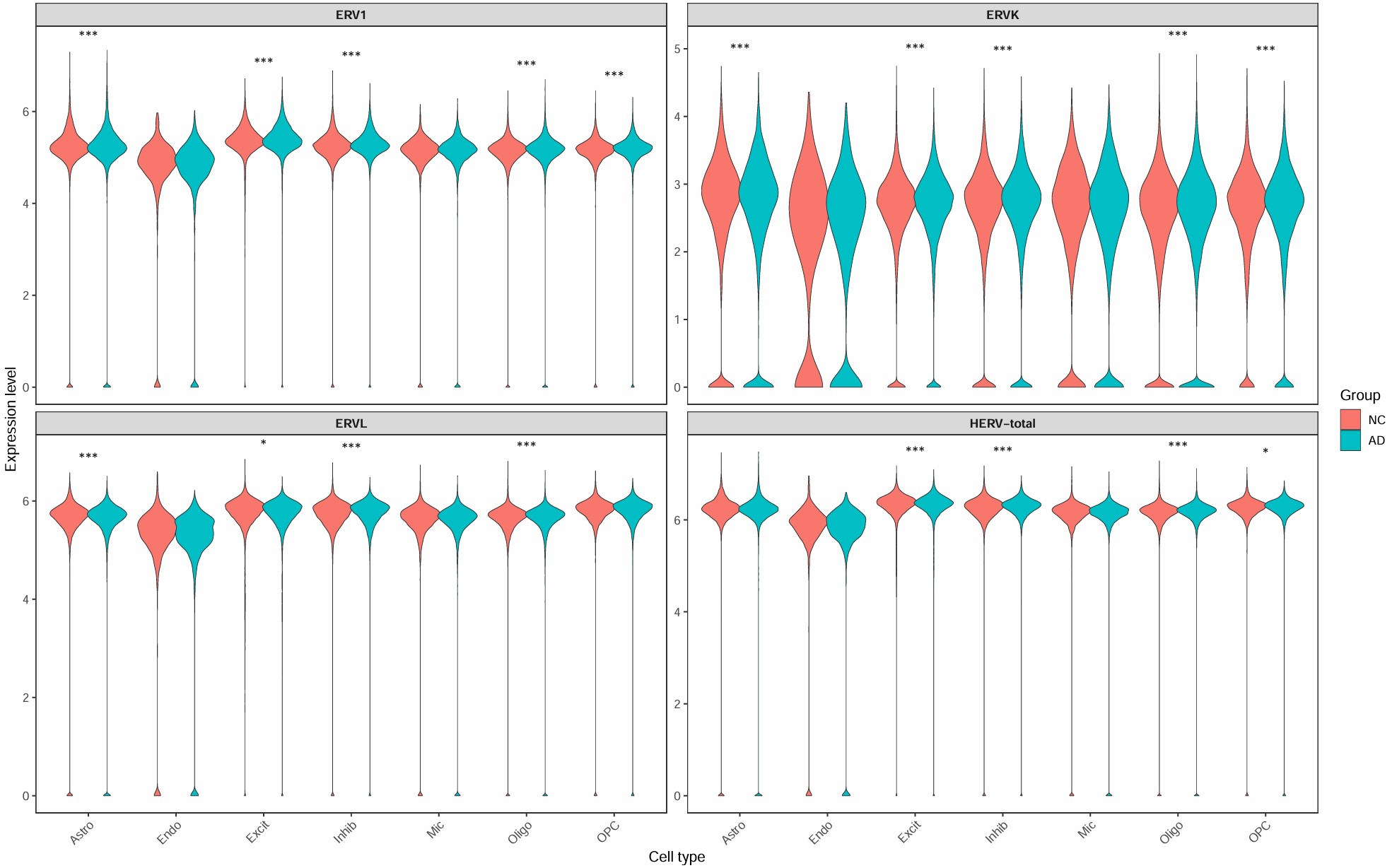
各细胞类型的hERV表达量和DE显著性
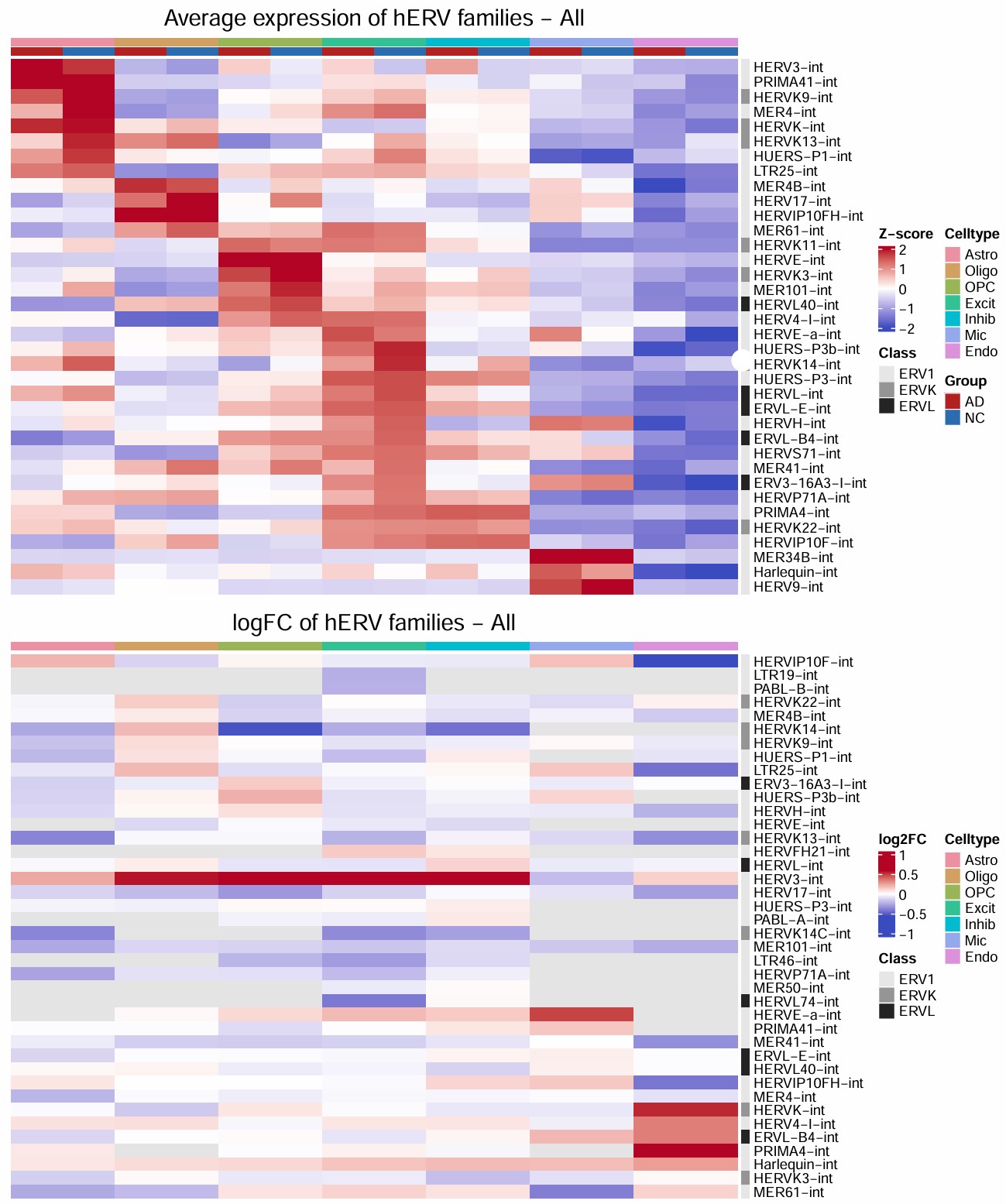
综合图:
-
HERV_family:
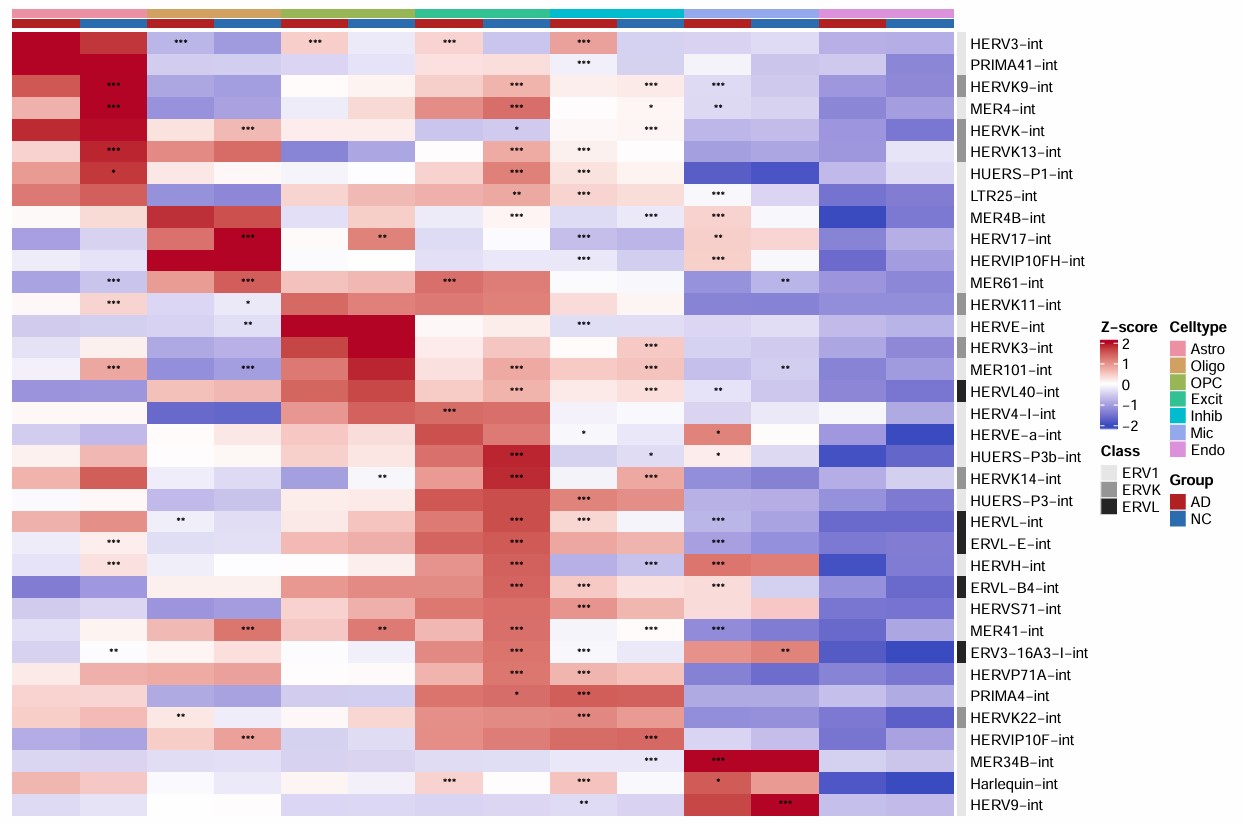
-
HERV_family:
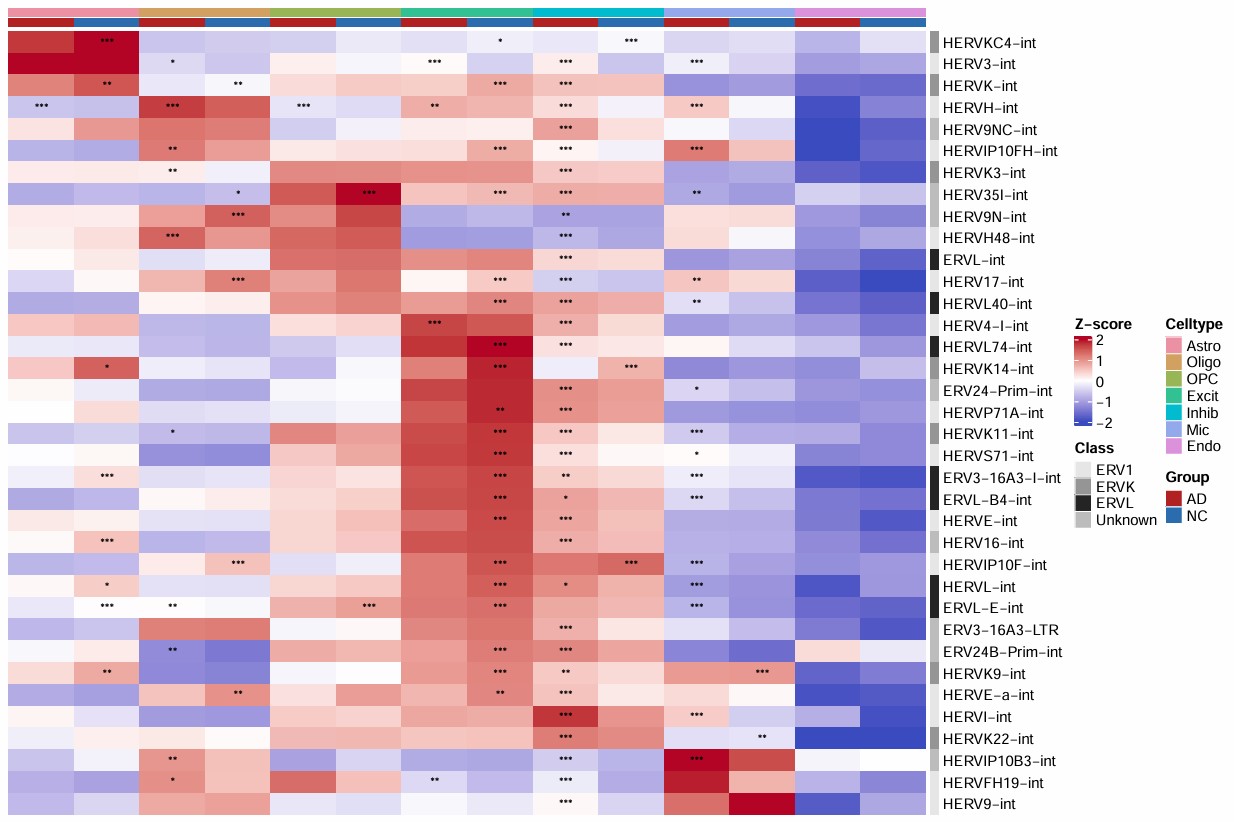
-
HERV_subfamily_LTR_scTE: